 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFitting trees to $\ell_1$-hyperbolic distances
Sep 02, 2024Building trees to represent or to fit distances is a critical component of phylogenetic analysis, metric embeddings, approximation algorithms, geometric graph neural nets, and the analysis of hierarchical data. Much of the previous algorithmic work, however, has focused on generic metric spaces (i.e., those with no a priori constraints). Leveraging several ideas from the mathematical analysis of hyperbolic geometry and geometric group theory, we study the tree fitting problem as finding the relation between the hyperbolicity (ultrametricity) vector and the error of tree (ultrametric) embedding. That is, we define a vector of hyperbolicity (ultrametric) values over all triples of points and compare the $\ell_p$ norms of this vector with the $\ell_q$ norm of the distortion of the best tree fit to the distances. This formulation allows us to define the average hyperbolicity (ultrametricity) in terms of a normalized $\ell_1$ norm of the hyperbolicity vector. Furthermore, we can interpret the classical tree fitting result of Gromov as a $p = q = \infty$ result. We present an algorithm HCCRootedTreeFit such that the $\ell_1$ error of the output embedding is analytically bounded in terms of the $\ell_1$ norm of the hyperbolicity vector (i.e., $p = q = 1$) and that this result is tight. Furthermore, this algorithm has significantly different theoretical and empirical performance as compared to Gromov's result and related algorithms. Finally, we show using HCCRootedTreeFit and related tree fitting algorithms, that supposedly standard data sets for hierarchical data analysis and geometric graph neural networks have radically different tree fits than those of synthetic, truly tree-like data sets, suggesting that a much more refined analysis of these standard data sets is called for.
* 12 pages, 2 figures, 14 pages supplementary. 37th Conference on Neural Information Processing Systems (NeurIPS 2023)
Sketching the Heat Kernel: Using Gaussian Processes to Embed Data
Mar 01, 2024This paper introduces a novel, non-deterministic method for embedding data in low-dimensional Euclidean space based on computing realizations of a Gaussian process depending on the geometry of the data. This type of embedding first appeared in (Adler et al, 2018) as a theoretical model for a generic manifold in high dimensions. In particular, we take the covariance function of the Gaussian process to be the heat kernel, and computing the embedding amounts to sketching a matrix representing the heat kernel. The Karhunen-Lo\`eve expansion reveals that the straight-line distances in the embedding approximate the diffusion distance in a probabilistic sense, avoiding the need for sharp cutoffs and maintaining some of the smaller-scale structure. Our method demonstrates further advantage in its robustness to outliers. We justify the approach with both theory and experiments.
CA-PCA: Manifold Dimension Estimation, Adapted for Curvature
Sep 23, 2023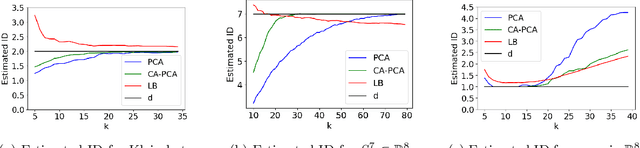
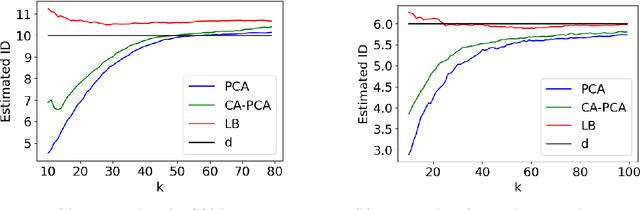
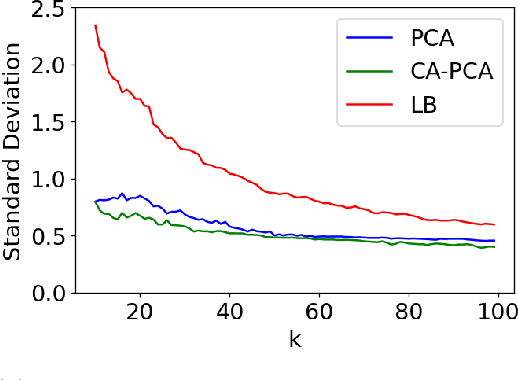
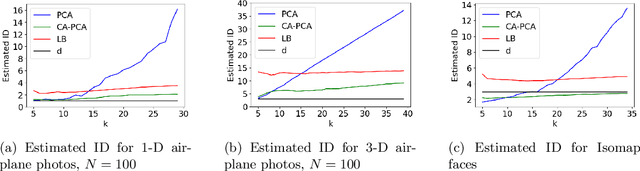
The success of algorithms in the analysis of high-dimensional data is often attributed to the manifold hypothesis, which supposes that this data lie on or near a manifold of much lower dimension. It is often useful to determine or estimate the dimension of this manifold before performing dimension reduction, for instance. Existing methods for dimension estimation are calibrated using a flat unit ball. In this paper, we develop CA-PCA, a version of local PCA based instead on a calibration of a quadratic embedding, acknowledging the curvature of the underlying manifold. Numerous careful experiments show that this adaptation improves the estimator in a wide range of settings.
May the force be with you
Aug 13, 2022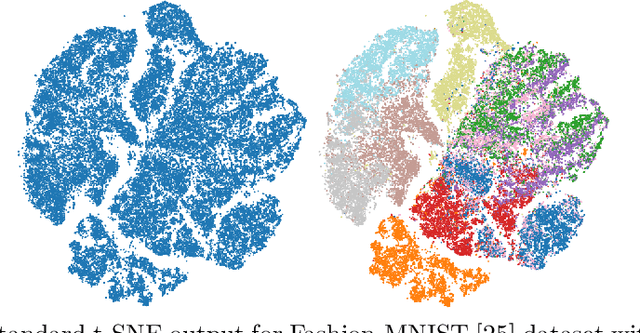
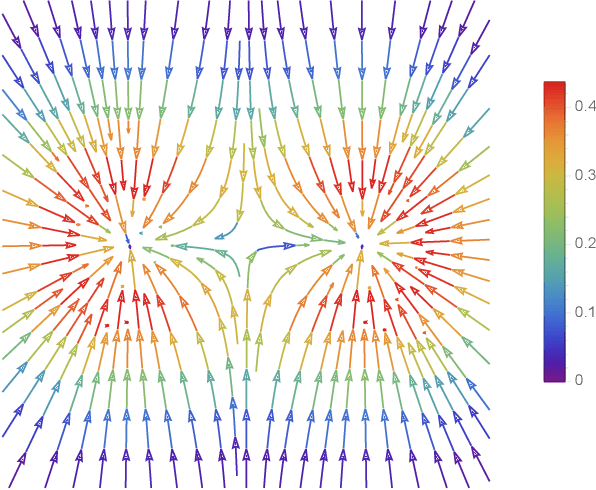
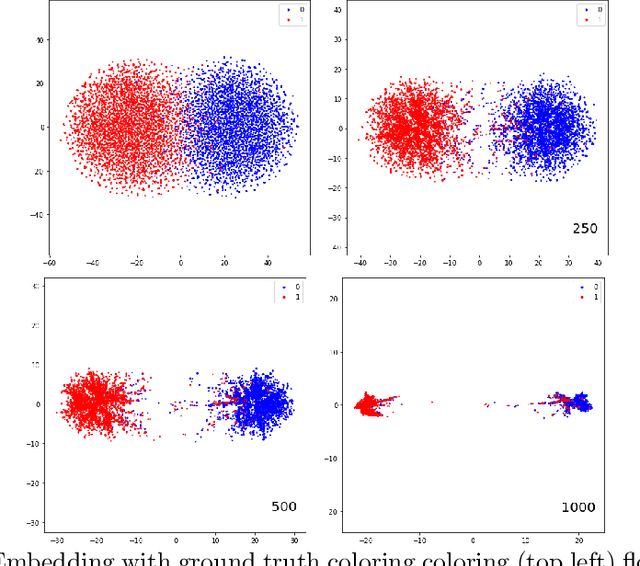
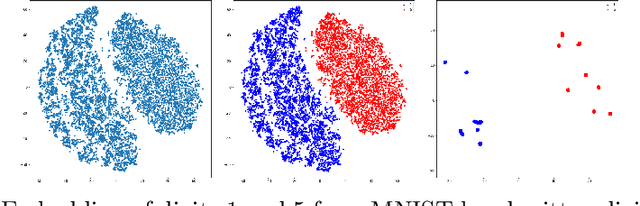
Modern methods in dimensionality reduction are dominated by nonlinear attraction-repulsion force-based methods (this includes t-SNE, UMAP, ForceAtlas2, LargeVis, and many more). The purpose of this paper is to demonstrate that all such methods, by design, come with an additional feature that is being automatically computed along the way, namely the vector field associated with these forces. We show how this vector field gives additional high-quality information and propose a general refinement strategy based on ideas from Morse theory. The efficiency of these ideas is illustrated specifically using t-SNE on synthetic and real-life data sets.
How can classical multidimensional scaling go wrong?
Oct 28, 2021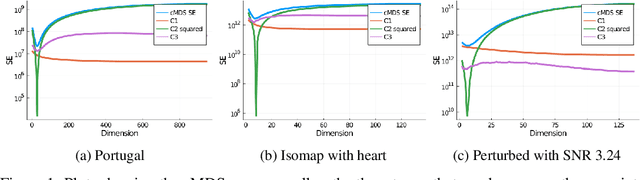
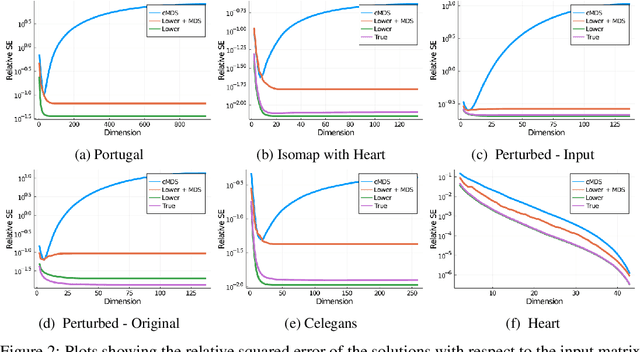
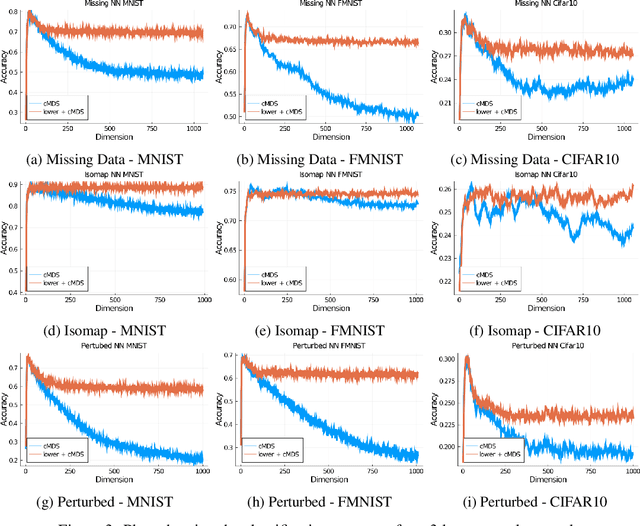

Given a matrix $D$ describing the pairwise dissimilarities of a data set, a common task is to embed the data points into Euclidean space. The classical multidimensional scaling (cMDS) algorithm is a widespread method to do this. However, theoretical analysis of the robustness of the algorithm and an in-depth analysis of its performance on non-Euclidean metrics is lacking. In this paper, we derive a formula, based on the eigenvalues of a matrix obtained from $D$, for the Frobenius norm of the difference between $D$ and the metric $D_{\text{cmds}}$ returned by cMDS. This error analysis leads us to the conclusion that when the derived matrix has a significant number of negative eigenvalues, then $\|D-D_{\text{cmds}}\|_F$, after initially decreasing, will eventually increase as we increase the dimension. Hence, counterintuitively, the quality of the embedding degrades as we increase the dimension. We empirically verify that the Frobenius norm increases as we increase the dimension for a variety of non-Euclidean metrics. We also show on several benchmark datasets that this degradation in the embedding results in the classification accuracy of both simple (e.g., 1-nearest neighbor) and complex (e.g., multi-layer neural nets) classifiers decreasing as we increase the embedding dimension. Finally, our analysis leads us to a new efficiently computable algorithm that returns a matrix $D_l$ that is at least as close to the original distances as $D_t$ (the Euclidean metric closest in $\ell_2$ distance). While $D_l$ is not metric, when given as input to cMDS instead of $D$, it empirically results in solutions whose distance to $D$ does not increase when we increase the dimension and the classification accuracy degrades less than the cMDS solution.
Spectral Methods for Ranking with Scarce Data
Jul 02, 2020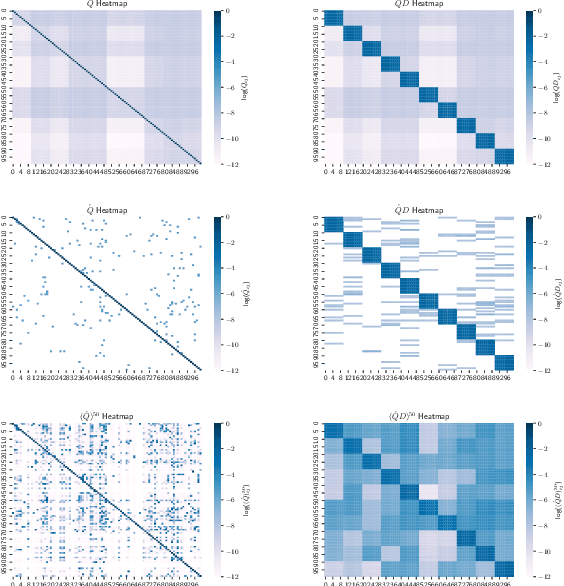

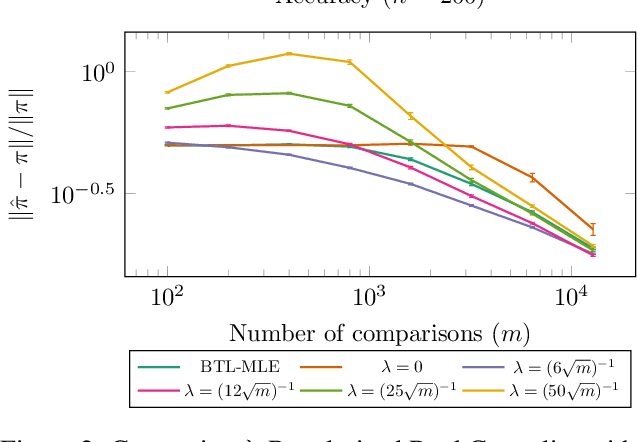
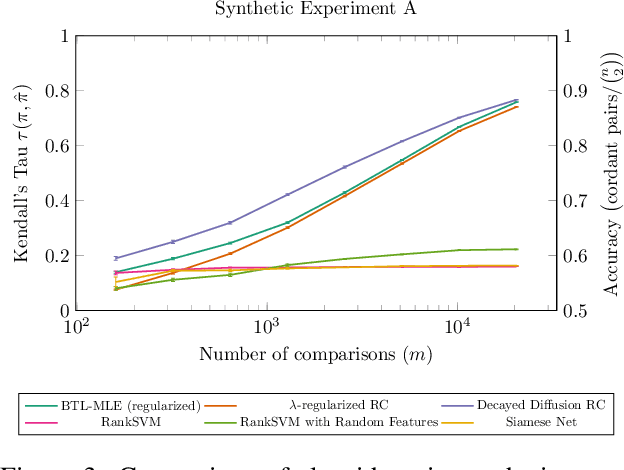
Given a number of pairwise preferences of items, a common task is to rank all the items. Examples include pairwise movie ratings, New Yorker cartoon caption contests, and many other consumer preferences tasks. What these settings have in common is two-fold: a scarcity of data (it may be costly to get comparisons for all the pairs of items) and additional feature information about the items (e.g., movie genre, director, and cast). In this paper we modify a popular and well studied method, RankCentrality for rank aggregation to account for few comparisons and that incorporates additional feature information. This method returns meaningful rankings even under scarce comparisons. Using diffusion based methods, we incorporate feature information that outperforms state-of-the-art methods in practice. We also provide improved sample complexity for RankCentrality in a variety of sampling schemes.
Tree! I am no Tree! I am a Low Dimensional Hyperbolic Embedding
May 28, 2020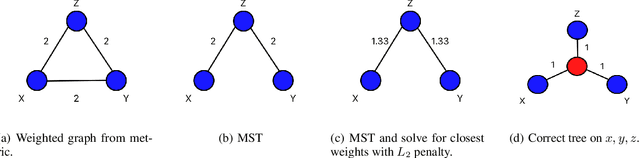



Given data, finding a faithful low-dimensional hyperbolic embedding of the data is a key method by which we can extract hierarchical information or learn representative geometric features of the data. In this paper, we explore a new method for learning hyperbolic representations that takes a metric-first approach. Rather than determining the low-dimensional hyperbolic embedding directly, we learn a tree structure on the data as an intermediate step. This tree structure can then be used directly to extract hierarchical information, embedded into a hyperbolic manifold using Sarkar's construction (Sarkar, 2012), or used as a tree approximation of the original metric. To this end, we present a novel fast algorithm TreeRep such that, given a $\delta$-hyperbolic metric (for any $\delta \geq 0$), the algorithm learns a tree structure that approximates the original metric. In the case when $\delta = 0$, we show analytically that TreeRep exactly recovers the original tree structure. We show empirically that TreeRep is not only many orders of magnitude faster than previous known algorithms, but also produces metrics with lower average distortion and higher mean average precision than most previous algorithms for learning hyperbolic embeddings, extracting hierarchical information, and approximating metrics via tree metrics.
Project and Forget: Solving Large-Scale Metric Constrained Problems
May 08, 2020
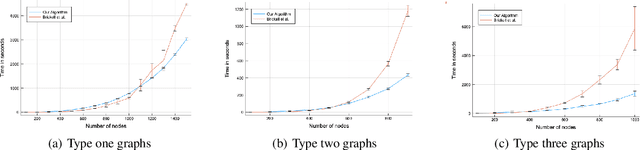


Given a set of dissimilarity measurements amongst data points, determining what metric representation is most "consistent" with the input measurements or the metric that best captures the relevant geometric features of the data is a key step in many machine learning algorithms. Existing methods are restricted to specific kinds of metrics or small problem sizes because of the large number of metric constraints in such problems. In this paper, we provide an active set algorithm, Project and Forget, that uses Bregman projections, to solve metric constrained problems with many (possibly exponentially) inequality constraints. We provide a theoretical analysis of \textsc{Project and Forget} and prove that our algorithm converges to the global optimal solution and that the $L_2$ distance of the current iterate to the optimal solution decays asymptotically at an exponential rate. We demonstrate that using our method we can solve large problem instances of three types of metric constrained problems: general weight correlation clustering, metric nearness, and metric learning; in each case, out-performing the state of the art methods with respect to CPU times and problem sizes.
Unrolling Swiss Cheese: Metric repair on manifolds with holes
Jul 23, 2018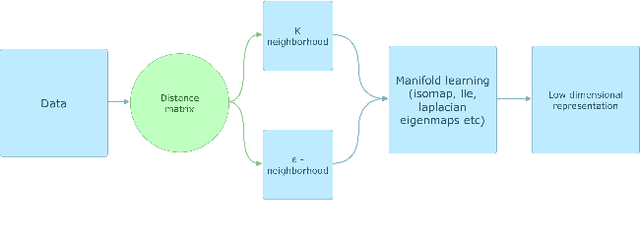
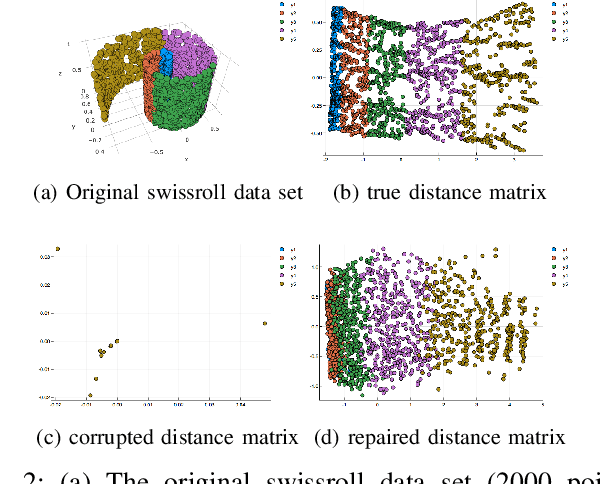
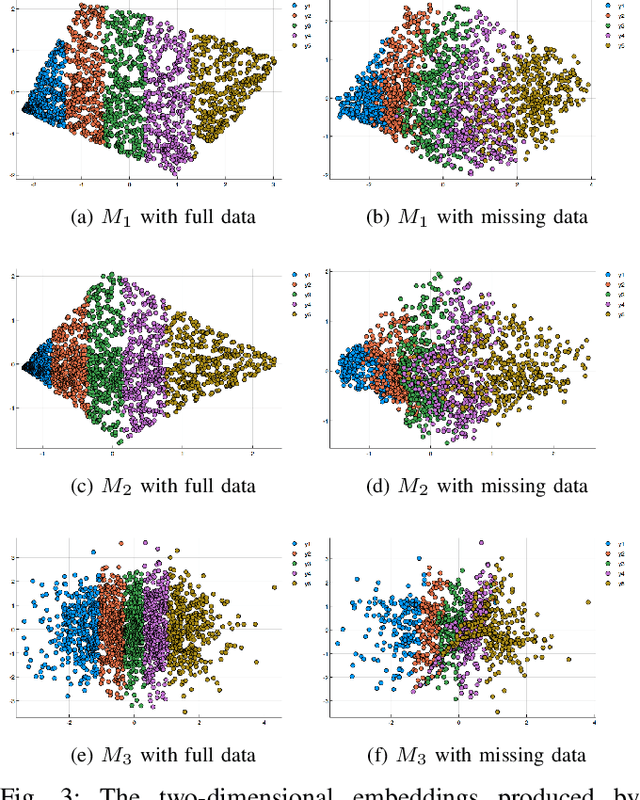

For many machine learning tasks, the input data lie on a low-dimensional manifold embedded in a high dimensional space and, because of this high-dimensional structure, most algorithms are inefficient. The typical solution is to reduce the dimension of the input data using standard dimension reduction algorithms such as ISOMAP, LAPLACIAN EIGENMAPS or LLES. This approach, however, does not always work in practice as these algorithms require that we have somewhat ideal data. Unfortunately, most data sets either have missing entries or unacceptably noisy values. That is, real data are far from ideal and we cannot use these algorithms directly. In this paper, we focus on the case when we have missing data. Some techniques, such as matrix completion, can be used to fill in missing data but these methods do not capture the non-linear structure of the manifold. Here, we present a new algorithm MR-MISSING that extends these previous algorithms and can be used to compute low dimensional representation on data sets with missing entries. We demonstrate the effectiveness of our algorithm by running three different experiments. We visually verify the effectiveness of our algorithm on synthetic manifolds, we numerically compare our projections against those computed by first filling in data using nlPCA and mDRUR on the MNIST data set, and we also show that we can do classification on MNIST with missing data. We also provide a theoretical guarantee for MR-MISSING under some simplifying assumptions.
If it ain't broke, don't fix it: Sparse metric repair
Oct 29, 2017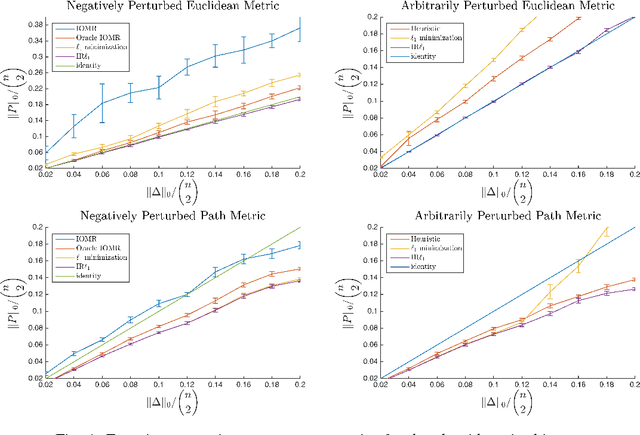
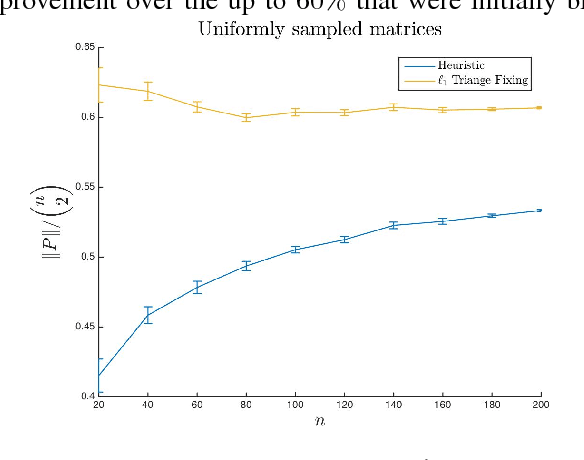
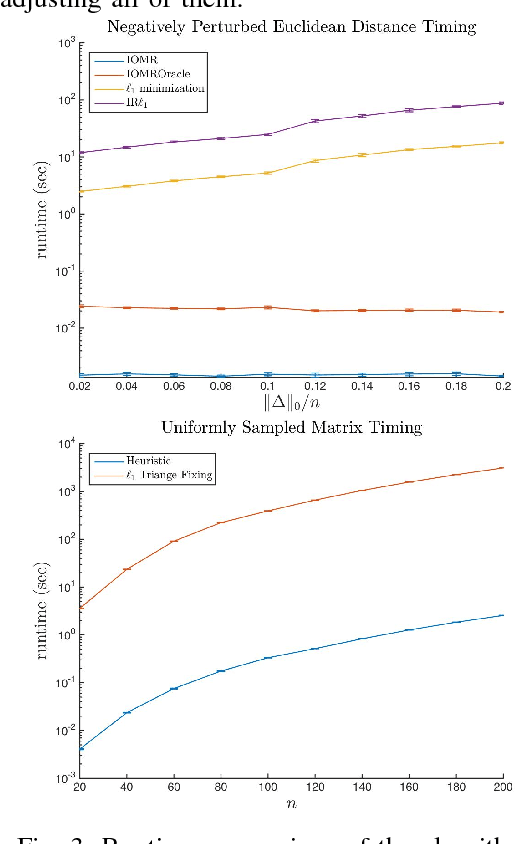
Many modern data-intensive computational problems either require, or benefit from distance or similarity data that adhere to a metric. The algorithms run faster or have better performance guarantees. Unfortunately, in real applications, the data are messy and values are noisy. The distances between the data points are far from satisfying a metric. Indeed, there are a number of different algorithms for finding the closest set of distances to the given ones that also satisfy a metric (sometimes with the extra condition of being Euclidean). These algorithms can have unintended consequences, they can change a large number of the original data points, and alter many other features of the data. The goal of sparse metric repair is to make as few changes as possible to the original data set or underlying distances so as to ensure the resulting distances satisfy the properties of a metric. In other words, we seek to minimize the sparsity (or the $\ell_0$ "norm") of the changes we make to the distances subject to the new distances satisfying a metric. We give three different combinatorial algorithms to repair a metric sparsely. In one setting the algorithm is guaranteed to return the sparsest solution and in the other settings, the algorithms repair the metric. Without prior information, the algorithms run in time proportional to the cube of the number of input data points and, with prior information we can reduce the running time considerably.