 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIf it ain't broke, don't fix it: Sparse metric repair
Paper and Code
Oct 29, 2017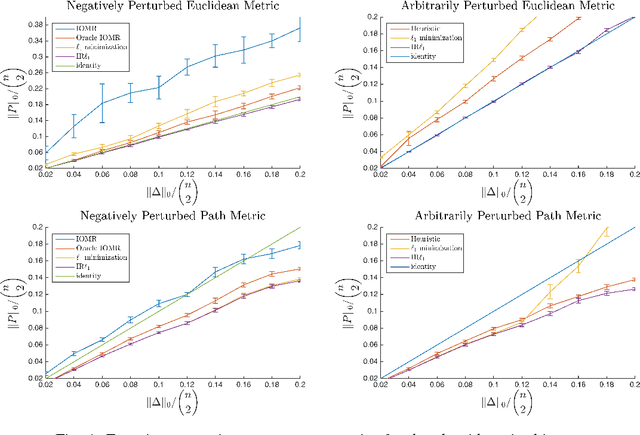
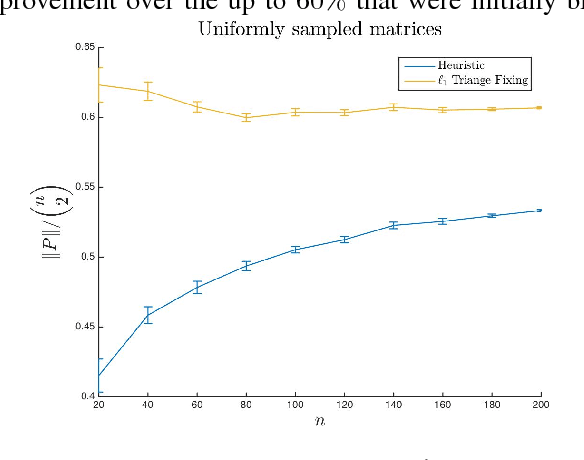
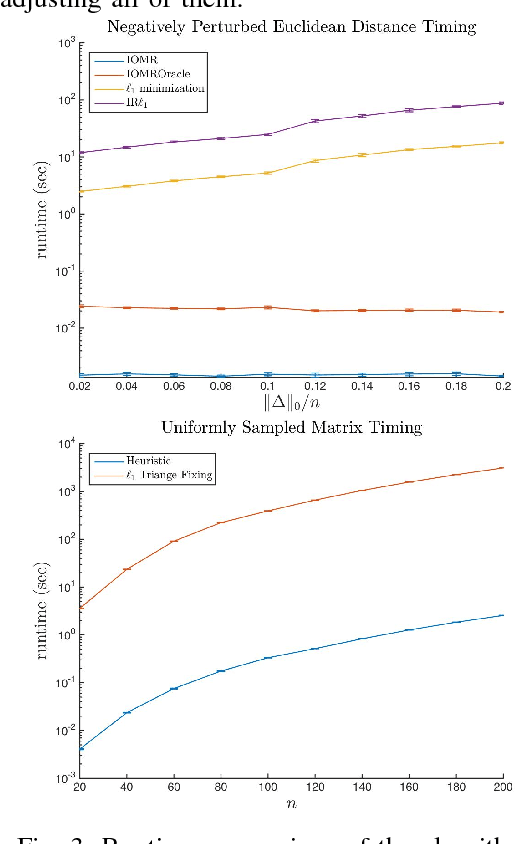
Many modern data-intensive computational problems either require, or benefit from distance or similarity data that adhere to a metric. The algorithms run faster or have better performance guarantees. Unfortunately, in real applications, the data are messy and values are noisy. The distances between the data points are far from satisfying a metric. Indeed, there are a number of different algorithms for finding the closest set of distances to the given ones that also satisfy a metric (sometimes with the extra condition of being Euclidean). These algorithms can have unintended consequences, they can change a large number of the original data points, and alter many other features of the data. The goal of sparse metric repair is to make as few changes as possible to the original data set or underlying distances so as to ensure the resulting distances satisfy the properties of a metric. In other words, we seek to minimize the sparsity (or the $\ell_0$ "norm") of the changes we make to the distances subject to the new distances satisfying a metric. We give three different combinatorial algorithms to repair a metric sparsely. In one setting the algorithm is guaranteed to return the sparsest solution and in the other settings, the algorithms repair the metric. Without prior information, the algorithms run in time proportional to the cube of the number of input data points and, with prior information we can reduce the running time considerably.