 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRPG (Decompose, Retrieve, Plan, Generate): An Agentic Framework for Academic Rebuttal
Jan 26, 2026Despite the growing adoption of large language models (LLMs) in scientific research workflows, automated support for academic rebuttal, a crucial step in academic communication and peer review, remains largely underexplored. Existing approaches typically rely on off-the-shelf LLMs or simple pipelines, which struggle with long-context understanding and often fail to produce targeted and persuasive responses. In this paper, we propose DRPG, an agentic framework for automatic academic rebuttal generation that operates through four steps: Decompose reviews into atomic concerns, Retrieve relevant evidence from the paper, Plan rebuttal strategies, and Generate responses accordingly. Notably, the Planner in DRPG reaches over 98% accuracy in identifying the most feasible rebuttal direction. Experiments on data from top-tier conferences demonstrate that DRPG significantly outperforms existing rebuttal pipelines and achieves performance beyond the average human level using only an 8B model. Our analysis further demonstrates the effectiveness of the planner design and its value in providing multi-perspective and explainable suggestions. We also showed that DRPG works well in a more complex multi-round setting. These results highlight the effectiveness of DRPG and its potential to provide high-quality rebuttal content and support the scaling of academic discussions. Codes for this work are available at https://github.com/ulab-uiuc/DRPG-RebuttalAgent.
Energy-Based Transformers are Scalable Learners and Thinkers
Jul 02, 2025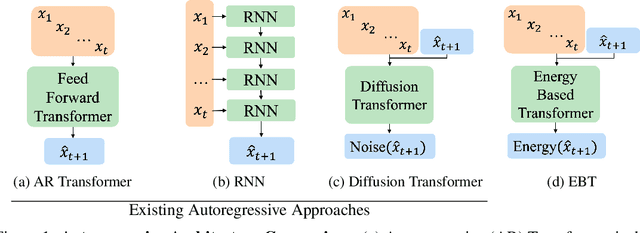


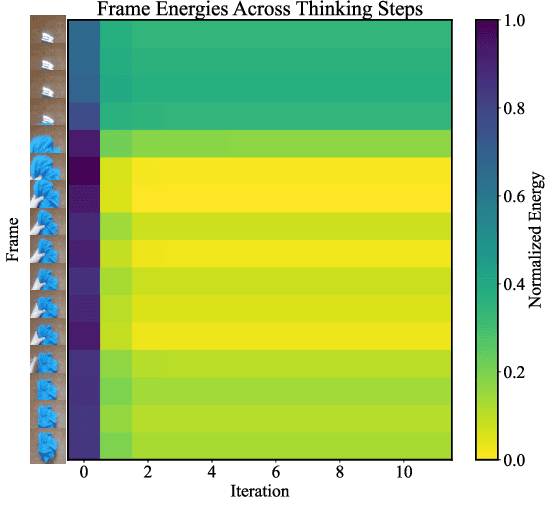
Inference-time computation techniques, analogous to human System 2 Thinking, have recently become popular for improving model performances. However, most existing approaches suffer from several limitations: they are modality-specific (e.g., working only in text), problem-specific (e.g., verifiable domains like math and coding), or require additional supervision/training on top of unsupervised pretraining (e.g., verifiers or verifiable rewards). In this paper, we ask the question "Is it possible to generalize these System 2 Thinking approaches, and develop models that learn to think solely from unsupervised learning?" Interestingly, we find the answer is yes, by learning to explicitly verify the compatibility between inputs and candidate-predictions, and then re-framing prediction problems as optimization with respect to this verifier. Specifically, we train Energy-Based Transformers (EBTs) -- a new class of Energy-Based Models (EBMs) -- to assign an energy value to every input and candidate-prediction pair, enabling predictions through gradient descent-based energy minimization until convergence. Across both discrete (text) and continuous (visual) modalities, we find EBTs scale faster than the dominant Transformer++ approach during training, achieving an up to 35% higher scaling rate with respect to data, batch size, parameters, FLOPs, and depth. During inference, EBTs improve performance with System 2 Thinking by 29% more than the Transformer++ on language tasks, and EBTs outperform Diffusion Transformers on image denoising while using fewer forward passes. Further, we find that EBTs achieve better results than existing models on most downstream tasks given the same or worse pretraining performance, suggesting that EBTs generalize better than existing approaches. Consequently, EBTs are a promising new paradigm for scaling both the learning and thinking capabilities of models.
ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind
May 29, 2025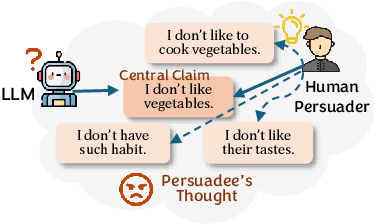

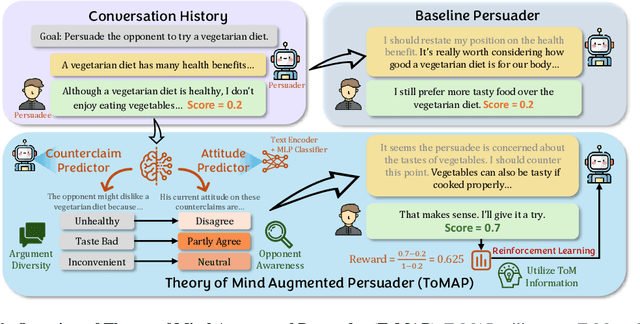

Large language models (LLMs) have shown promising potential in persuasion, but existing works on training LLM persuaders are still preliminary. Notably, while humans are skilled in modeling their opponent's thoughts and opinions proactively and dynamically, current LLMs struggle with such Theory of Mind (ToM) reasoning, resulting in limited diversity and opponent awareness. To address this limitation, we introduce Theory of Mind Augmented Persuader (ToMAP), a novel approach for building more flexible persuader agents by incorporating two theory of mind modules that enhance the persuader's awareness and analysis of the opponent's mental state. Specifically, we begin by prompting the persuader to consider possible objections to the target central claim, and then use a text encoder paired with a trained MLP classifier to predict the opponent's current stance on these counterclaims. Our carefully designed reinforcement learning schema enables the persuader learns how to analyze opponent-related information and utilize it to generate more effective arguments. Experiments show that the ToMAP persuader, while containing only 3B parameters, outperforms much larger baselines, like GPT-4o, with a relative gain of 39.4% across multiple persuadee models and diverse corpora. Notably, ToMAP exhibits complex reasoning chains and reduced repetition during training, which leads to more diverse and effective arguments. The opponent-aware feature of ToMAP also makes it suitable for long conversations and enables it to employ more logical and opponent-aware strategies. These results underscore our method's effectiveness and highlight its potential for developing more persuasive language agents. Code is available at: https://github.com/ulab-uiuc/ToMAP.
SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents
May 29, 2025Recent advancements in large language model (LLM) agents have significantly accelerated scientific discovery automation, yet concurrently raised critical ethical and safety concerns. To systematically address these challenges, we introduce \textbf{SafeScientist}, an innovative AI scientist framework explicitly designed to enhance safety and ethical responsibility in AI-driven scientific exploration. SafeScientist proactively refuses ethically inappropriate or high-risk tasks and rigorously emphasizes safety throughout the research process. To achieve comprehensive safety oversight, we integrate multiple defensive mechanisms, including prompt monitoring, agent-collaboration monitoring, tool-use monitoring, and an ethical reviewer component. Complementing SafeScientist, we propose \textbf{SciSafetyBench}, a novel benchmark specifically designed to evaluate AI safety in scientific contexts, comprising 240 high-risk scientific tasks across 6 domains, alongside 30 specially designed scientific tools and 120 tool-related risk tasks. Extensive experiments demonstrate that SafeScientist significantly improves safety performance by 35\% compared to traditional AI scientist frameworks, without compromising scientific output quality. Additionally, we rigorously validate the robustness of our safety pipeline against diverse adversarial attack methods, further confirming the effectiveness of our integrated approach. The code and data will be available at https://github.com/ulab-uiuc/SafeScientist. \textcolor{red}{Warning: this paper contains example data that may be offensive or harmful.}
DecisionFlow: Advancing Large Language Model as Principled Decision Maker
May 27, 2025In high-stakes domains such as healthcare and finance, effective decision-making demands not just accurate outcomes but transparent and explainable reasoning. However, current language models often lack the structured deliberation needed for such tasks, instead generating decisions and justifications in a disconnected, post-hoc manner. To address this, we propose DecisionFlow, a novel decision modeling framework that guides models to reason over structured representations of actions, attributes, and constraints. Rather than predicting answers directly from prompts, DecisionFlow builds a semantically grounded decision space and infers a latent utility function to evaluate trade-offs in a transparent, utility-driven manner. This process produces decisions tightly coupled with interpretable rationales reflecting the model's reasoning. Empirical results on two high-stakes benchmarks show that DecisionFlow not only achieves up to 30% accuracy gains over strong prompting baselines but also enhances alignment in outcomes. Our work is a critical step toward integrating symbolic reasoning with LLMs, enabling more accountable, explainable, and reliable LLM decision support systems. We release the data and code at https://github.com/xiusic/DecisionFlow.
Internal Activation as the Polar Star for Steering Unsafe LLM Behavior
Feb 04, 2025



Large language models (LLMs) have demonstrated exceptional capabilities across a wide range of tasks but also pose significant risks due to their potential to generate harmful content. Although existing safety mechanisms can improve model safety, they often lead to overly cautious behavior and fail to fully utilize LLMs' internal cognitive processes. Drawing inspiration from cognitive science, where humans rely on reflective reasoning (System 2 thinking) to regulate language and behavior, we empirically demonstrate that LLMs also possess a similar capacity for internal assessment and regulation, which can be actively detected. Building on this insight, we introduce SafeSwitch, a framework that dynamically regulates unsafe outputs by monitoring and utilizing the model's internal states. Our empirical results show that SafeSwitch reduces harmful outputs by over 80% on safety benchmarks while maintaining strong utility. Compared to traditional safety alignment methods, SafeSwitch delivers more informative and context-aware refusals, demonstrates resilience to unseen queries, and achieves these benefits while only tuning less than 6% of the original parameters. These features make SafeSwitch a promising approach for implementing nuanced safety controls in LLMs.
EscapeBench: Pushing Language Models to Think Outside the Box
Dec 18, 2024Language model agents excel in long-session planning and reasoning, but existing benchmarks primarily focus on goal-oriented tasks with explicit objectives, neglecting creative adaptation in unfamiliar environments. To address this, we introduce EscapeBench, a benchmark suite of room escape game environments designed to challenge agents with creative reasoning, unconventional tool use, and iterative problem-solving to uncover implicit goals. Our results show that current LM models, despite employing working memory and Chain-of-Thought reasoning, achieve only 15% average progress without hints, highlighting their limitations in creativity. To bridge this gap, we propose EscapeAgent, a framework designed to enhance creative reasoning through Foresight (innovative tool use) and Reflection (identifying unsolved tasks). Experiments show that EscapeAgent can execute action chains over 1,000 steps while maintaining logical coherence. It navigates and completes games with up to 40% fewer steps and hints, performs robustly across varying difficulty levels, and achieves higher action success rates with more efficient and innovative puzzle-solving strategies. All the data and codes are released.
Distributionally Robust Unsupervised Dense Retrieval Training on Web Graphs
Oct 26, 2023This paper introduces Web-DRO, an unsupervised dense retrieval model, which clusters documents based on web structures and reweights the groups during contrastive training. Specifically, we first leverage web graph links and contrastively train an embedding model for clustering anchor-document pairs. Then we use Group Distributional Robust Optimization to reweight different clusters of anchor-document pairs, which guides the model to assign more weights to the group with higher contrastive loss and pay more attention to the worst case during training. Our experiments on MS MARCO and BEIR show that our model, Web-DRO, significantly improves the retrieval effectiveness in unsupervised scenarios. A comparison of clustering techniques shows that training on the web graph combining URL information reaches optimal performance on clustering. Further analysis confirms that group weights are stable and valid, indicating consistent model preferences as well as effective up-weighting of valuable groups and down-weighting of uninformative ones. The code of this paper can be obtained from https://github.com/OpenMatch/Web-DRO.