 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Learning with Cost-Sensitive Classes
Jan 29, 2021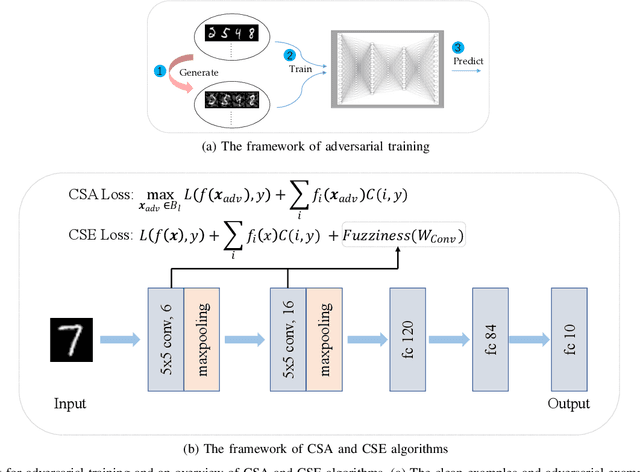

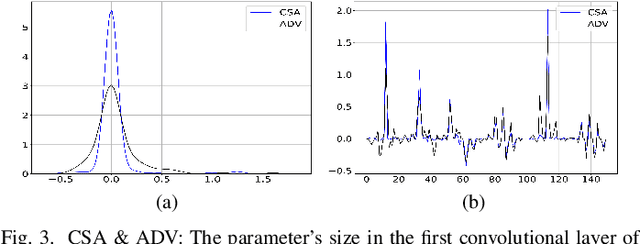
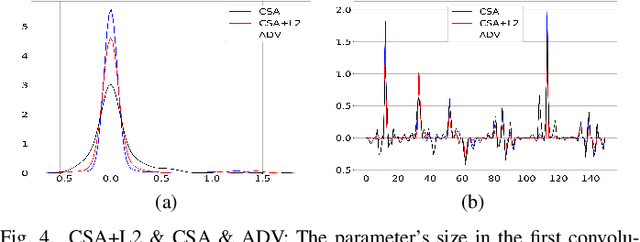
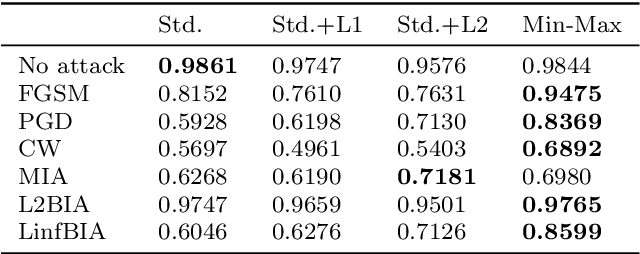
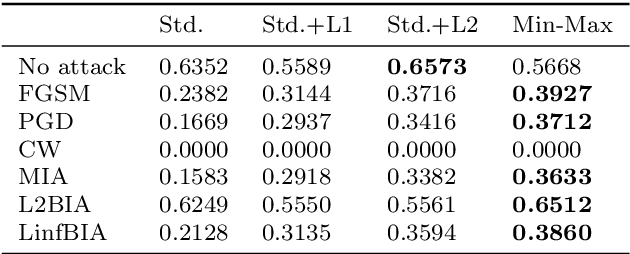
It is necessary to improve the performance of some special classes or to particularly protect them from attacks in adversarial learning. This paper proposes a framework combining cost-sensitive classification and adversarial learning together to train a model that can distinguish between protected and unprotected classes, such that the protected classes are less vulnerable to adversarial examples. We find in this framework an interesting phenomenon during the training of deep neural networks, called Min-Max property, that is, the absolute values of most parameters in the convolutional layer approach zero while the absolute values of a few parameters are significantly larger becoming bigger. Based on this Min-Max property which is formulated and analyzed in a view of random distribution, we further build a new defense model against adversarial examples for adversarial robustness improvement. An advantage of the built model is that it does no longer need adversarial training, and thus, has a higher computational efficiency than most existing models of needing adversarial training. It is experimentally confirmed that, regarding the average accuracy of all classes, our model is almost as same as the existing models when an attack does not occur and is better than the existing models when an attack occurs. Specifically, regarding the accuracy of protected classes, the proposed model is much better than the existing models when an attack occurs.
Generalized Adversarial Examples: Attacks and Defenses
Nov 28, 2020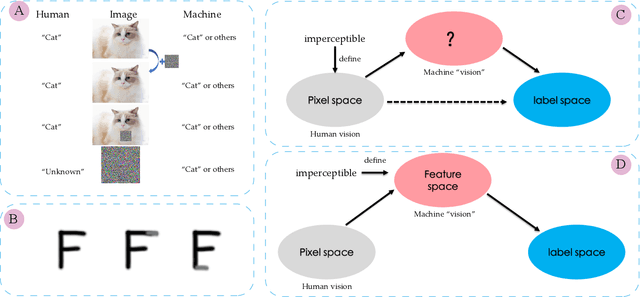
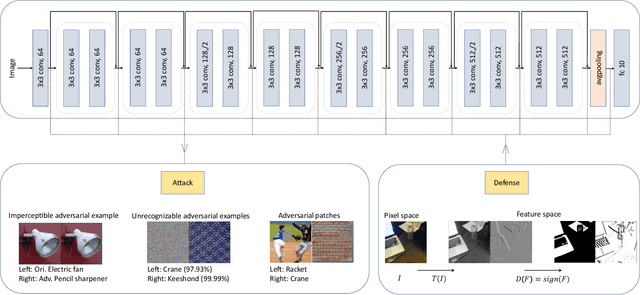

Most of the works follow such definition of adversarial example that is imperceptible to humans but can fool the deep neural networks (DNNs). Some works find another interesting form of adversarial examples such as one which is unrecognizable to humans, but DNNs classify it as one class with high confidence and adversarial patch. Based on this phenomenon, in this paper, from the perspective of cognition of humans and machines, we propose a new definition of adversarial examples. We show that imperceptible adversarial examples, unrecognizable adversarial examples, and adversarial patches are derivates of generalized adversarial examples. Then, we propose three types of adversarial attacks based on the generalized definition. Finally, we propose a defence mechanism that achieves state-of-the-art performance. We construct a lossy compression function to filter out the redundant features generated by the network. In this process, the perturbation produced by the attacker will be filtered out. Therefore, the defence mechanism can effectively improve the robustness of the model. The experiments show that our attack methods can effectively generate adversarial examples, and our defence method can significantly improve the adversarial robustness of DNNs compared with adversarial training. As far as we know, our defending method achieves the best performance even though we do not adopt adversarial training.
A Study on the Uncertainty of Convolutional Layers in Deep Neural Networks
Nov 27, 2020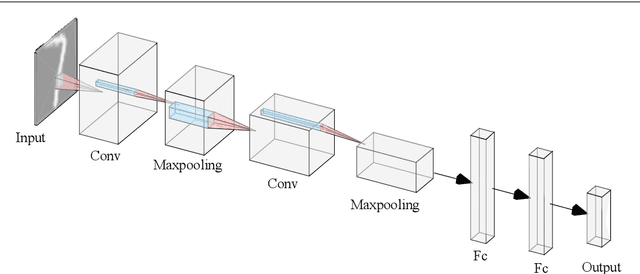
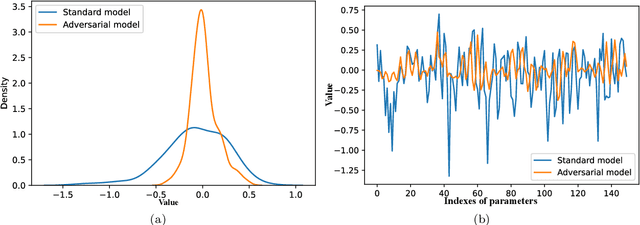
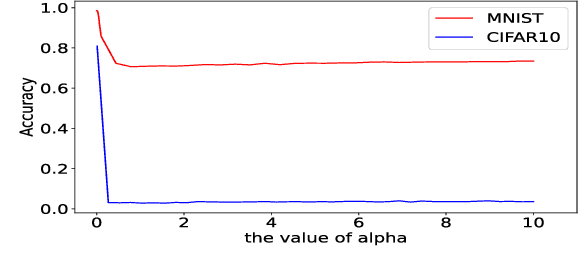
This paper shows a Min-Max property existing in the connection weights of the convolutional layers in a neural network structure, i.e., the LeNet. Specifically, the Min-Max property means that, during the back propagation-based training for LeNet, the weights of the convolutional layers will become far away from their centers of intervals, i.e., decreasing to their minimum or increasing to their maximum. From the perspective of uncertainty, we demonstrate that the Min-Max property corresponds to minimizing the fuzziness of the model parameters through a simplified formulation of convolution. It is experimentally confirmed that the model with the Min-Max property has a stronger adversarial robustness, thus this property can be incorporated into the design of loss function. This paper points out a changing tendency of uncertainty in the convolutional layers of LeNet structure, and gives some insights to the interpretability of convolution.