 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Adversarial Examples: Attacks and Defenses
Paper and Code
Nov 28, 2020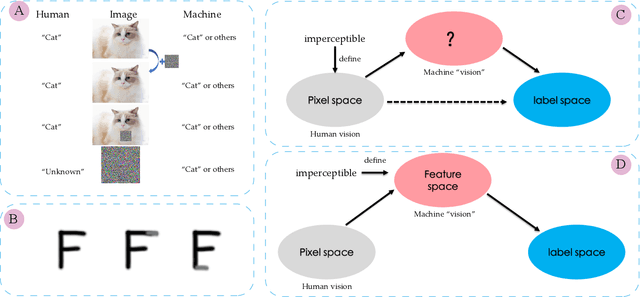
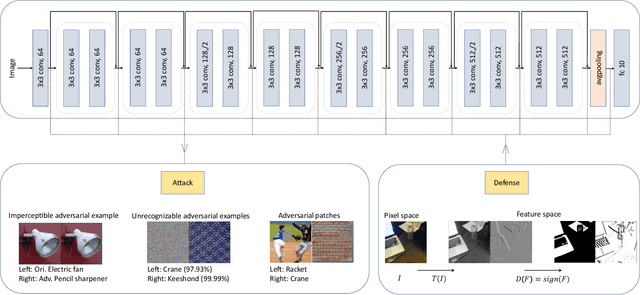
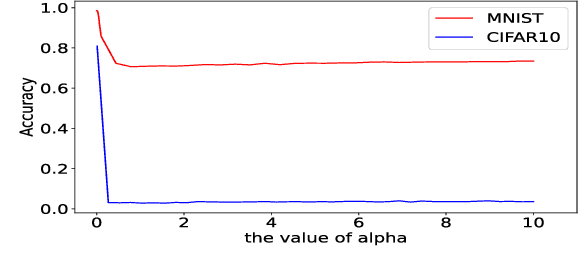

Most of the works follow such definition of adversarial example that is imperceptible to humans but can fool the deep neural networks (DNNs). Some works find another interesting form of adversarial examples such as one which is unrecognizable to humans, but DNNs classify it as one class with high confidence and adversarial patch. Based on this phenomenon, in this paper, from the perspective of cognition of humans and machines, we propose a new definition of adversarial examples. We show that imperceptible adversarial examples, unrecognizable adversarial examples, and adversarial patches are derivates of generalized adversarial examples. Then, we propose three types of adversarial attacks based on the generalized definition. Finally, we propose a defence mechanism that achieves state-of-the-art performance. We construct a lossy compression function to filter out the redundant features generated by the network. In this process, the perturbation produced by the attacker will be filtered out. Therefore, the defence mechanism can effectively improve the robustness of the model. The experiments show that our attack methods can effectively generate adversarial examples, and our defence method can significantly improve the adversarial robustness of DNNs compared with adversarial training. As far as we know, our defending method achieves the best performance even though we do not adopt adversarial training.