 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning for Class Distribution Mismatch
May 11, 2025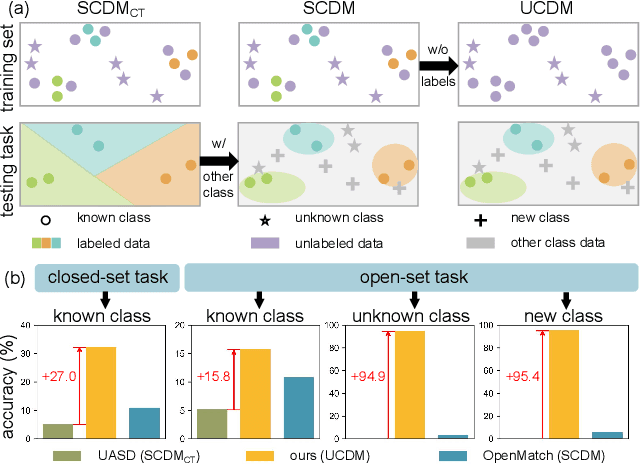

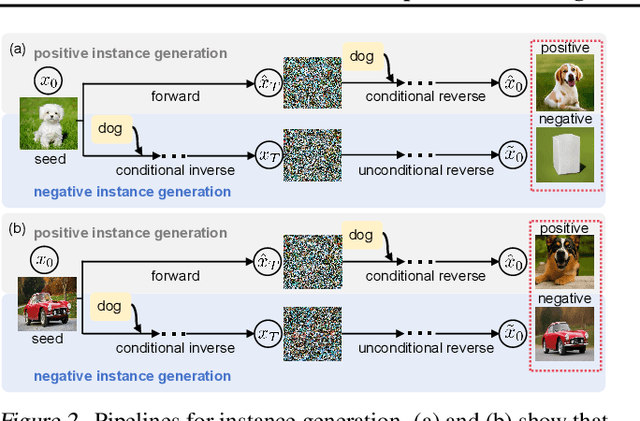

Class distribution mismatch (CDM) refers to the discrepancy between class distributions in training data and target tasks. Previous methods address this by designing classifiers to categorize classes known during training, while grouping unknown or new classes into an "other" category. However, they focus on semi-supervised scenarios and heavily rely on labeled data, limiting their applicability and performance. To address this, we propose Unsupervised Learning for Class Distribution Mismatch (UCDM), which constructs positive-negative pairs from unlabeled data for classifier training. Our approach randomly samples images and uses a diffusion model to add or erase semantic classes, synthesizing diverse training pairs. Additionally, we introduce a confidence-based labeling mechanism that iteratively assigns pseudo-labels to valuable real-world data and incorporates them into the training process. Extensive experiments on three datasets demonstrate UCDM's superiority over previous semi-supervised methods. Specifically, with a 60% mismatch proportion on Tiny-ImageNet dataset, our approach, without relying on labeled data, surpasses OpenMatch (with 40 labels per class) by 35.1%, 63.7%, and 72.5% in classifying known, unknown, and new classes.
Personalized Clustering via Targeted Representation Learning
Dec 18, 2024



Clustering traditionally aims to reveal a natural grouping structure model from unlabeled data. However, this model may not always align with users' preference. In this paper, we propose a personalized clustering method that explicitly performs targeted representation learning by interacting with users via modicum task information (e.g., $\textit{must-link}$ or $\textit{cannot-link}$ pairs) to guide the clustering direction. We query users with the most informative pairs, i.e., those pairs most hard to cluster and those most easy to miscluster, to facilitate the representation learning in terms of the clustering preference. Moreover, by exploiting attention mechanism, the targeted representation is learned and augmented. By leveraging the targeted representation and constrained constrastive loss as well, personalized clustering is obtained. Theoretically, we verify that the risk of personalized clustering is tightly bounded, guaranteeing that active queries to users do mitigate the clustering risk. Experimentally, extensive results show that our method performs well across different clustering tasks and datasets, even with a limited number of queries.
Semi-Supervised Learning via Weight-aware Distillation under Class Distribution Mismatch
Aug 23, 2023
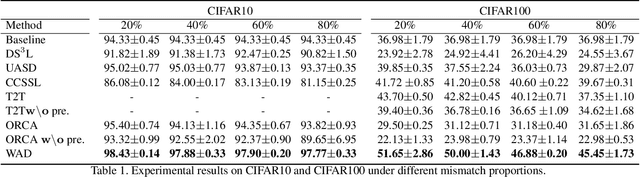


Semi-Supervised Learning (SSL) under class distribution mismatch aims to tackle a challenging problem wherein unlabeled data contain lots of unknown categories unseen in the labeled ones. In such mismatch scenarios, traditional SSL suffers severe performance damage due to the harmful invasion of the instances with unknown categories into the target classifier. In this study, by strict mathematical reasoning, we reveal that the SSL error under class distribution mismatch is composed of pseudo-labeling error and invasion error, both of which jointly bound the SSL population risk. To alleviate the SSL error, we propose a robust SSL framework called Weight-Aware Distillation (WAD) that, by weights, selectively transfers knowledge beneficial to the target task from unsupervised contrastive representation to the target classifier. Specifically, WAD captures adaptive weights and high-quality pseudo labels to target instances by exploring point mutual information (PMI) in representation space to maximize the role of unlabeled data and filter unknown categories. Theoretically, we prove that WAD has a tight upper bound of population risk under class distribution mismatch. Experimentally, extensive results demonstrate that WAD outperforms five state-of-the-art SSL approaches and one standard baseline on two benchmark datasets, CIFAR10 and CIFAR100, and an artificial cross-dataset. The code is available at https://github.com/RUC-DWBI-ML/research/tree/main/WAD-master.
Echo of Neighbors: Privacy Amplification for Personalized Private Federated Learning with Shuffle Model
Apr 11, 2023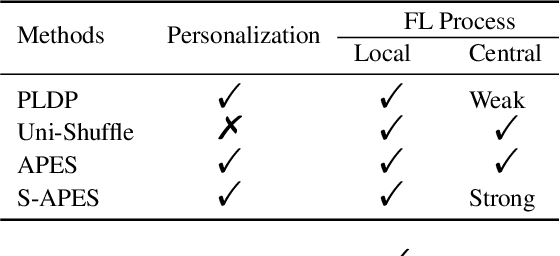
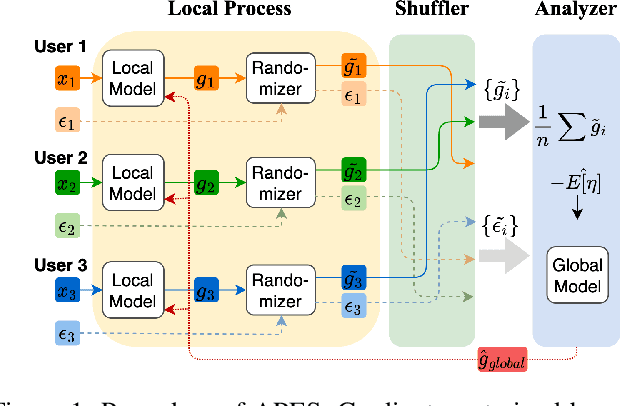

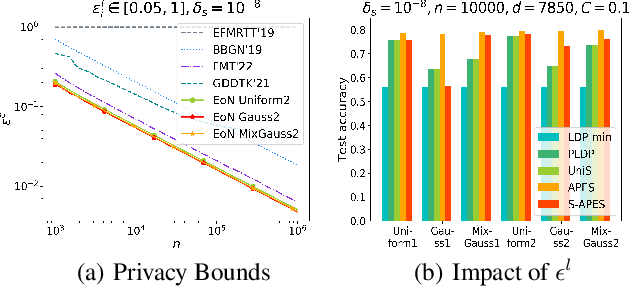
Federated Learning, as a popular paradigm for collaborative training, is vulnerable against privacy attacks. Different privacy levels regarding users' attitudes need to be satisfied locally, while a strict privacy guarantee for the global model is also required centrally. Personalized Local Differential Privacy (PLDP) is suitable for preserving users' varying local privacy, yet only provides a central privacy guarantee equivalent to the worst-case local privacy level. Thus, achieving strong central privacy as well as personalized local privacy with a utility-promising model is a challenging problem. In this work, a general framework (APES) is built up to strengthen model privacy under personalized local privacy by leveraging the privacy amplification effect of the shuffle model. To tighten the privacy bound, we quantify the heterogeneous contributions to the central privacy user by user. The contributions are characterized by the ability of generating "echos" from the perturbation of each user, which is carefully measured by proposed methods Neighbor Divergence and Clip-Laplace Mechanism. Furthermore, we propose a refined framework (S-APES) with the post-sparsification technique to reduce privacy loss in high-dimension scenarios. To the best of our knowledge, the impact of shuffling on personalized local privacy is considered for the first time. We provide a strong privacy amplification effect, and the bound is tighter than the baseline result based on existing methods for uniform local privacy. Experiments demonstrate that our frameworks ensure comparable or higher accuracy for the global model.
Oracle-guided Contrastive Clustering
Nov 01, 2022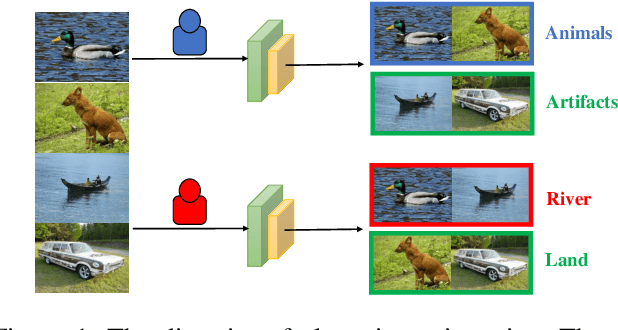
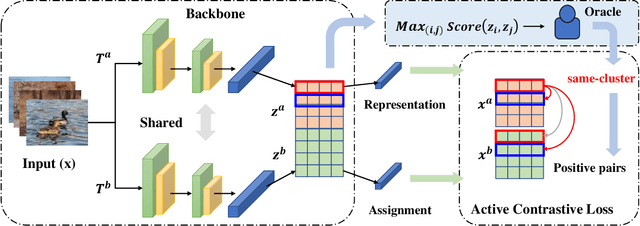
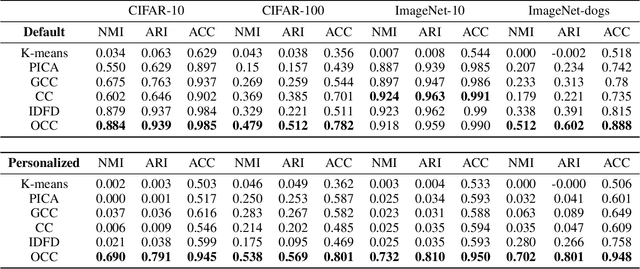
Deep clustering aims to learn a clustering representation through deep architectures. Most of the existing methods usually conduct clustering with the unique goal of maximizing clustering performance, that ignores the personalized demand of clustering tasks.% and results in unguided clustering solutions. However, in real scenarios, oracles may tend to cluster unlabeled data by exploiting distinct criteria, such as distinct semantics (background, color, object, etc.), and then put forward personalized clustering tasks. To achieve task-aware clustering results, in this study, Oracle-guided Contrastive Clustering(OCC) is then proposed to cluster by interactively making pairwise ``same-cluster" queries to oracles with distinctive demands. Specifically, inspired by active learning, some informative instance pairs are queried, and evaluated by oracles whether the pairs are in the same cluster according to their desired orientation. And then these queried same-cluster pairs extend the set of positive instance pairs for contrastive learning, guiding OCC to extract orientation-aware feature representation. Accordingly, the query results, guided by oracles with distinctive demands, may drive the OCC's clustering results in a desired orientation. Theoretically, the clustering risk in an active learning manner is given with a tighter upper bound, that guarantees active queries to oracles do mitigate the clustering risk. Experimentally, extensive results verify that OCC can cluster accurately along the specific orientation and it substantially outperforms the SOTA clustering methods as well. To the best of our knowledge, it is the first deep framework to perform personalized clustering.
An Accelerator for Rule Induction in Fuzzy Rough Theory
Jan 07, 2022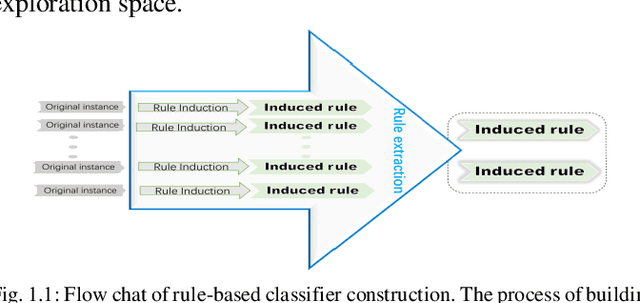
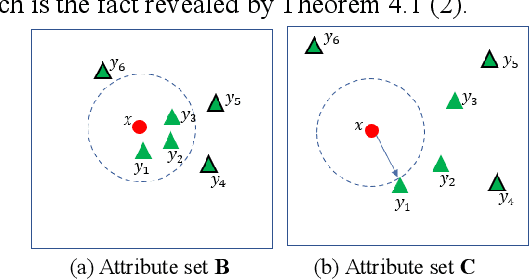
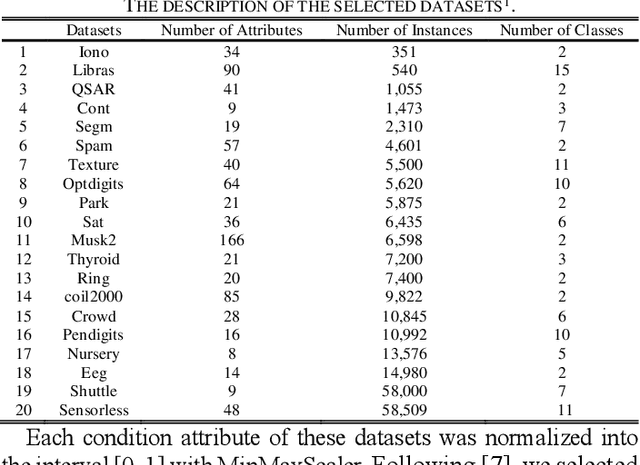
Rule-based classifier, that extract a subset of induced rules to efficiently learn/mine while preserving the discernibility information, plays a crucial role in human-explainable artificial intelligence. However, in this era of big data, rule induction on the whole datasets is computationally intensive. So far, to the best of our knowledge, no known method focusing on accelerating rule induction has been reported. This is first study to consider the acceleration technique to reduce the scale of computation in rule induction. We propose an accelerator for rule induction based on fuzzy rough theory; the accelerator can avoid redundant computation and accelerate the building of a rule classifier. First, a rule induction method based on consistence degree, called Consistence-based Value Reduction (CVR), is proposed and used as basis to accelerate. Second, we introduce a compacted search space termed Key Set, which only contains the key instances required to update the induced rule, to conduct value reduction. The monotonicity of Key Set ensures the feasibility of our accelerator. Third, a rule-induction accelerator is designed based on Key Set, and it is theoretically guaranteed to display the same results as the unaccelerated version. Specifically, the rank preservation property of Key Set ensures consistency between the rule induction achieved by the accelerator and the unaccelerated method. Finally, extensive experiments demonstrate that the proposed accelerator can perform remarkably faster than the unaccelerated rule-based classifier methods, especially on datasets with numerous instances.