 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comparative study of neural network techniques for automatic software vulnerability detection
Apr 29, 2021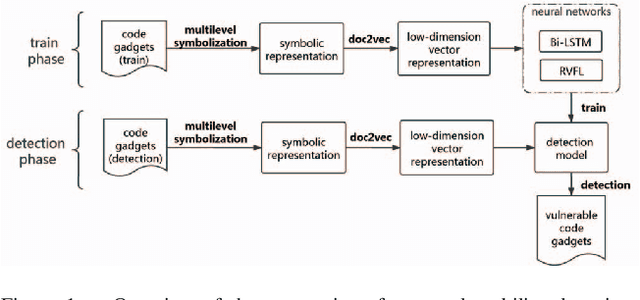
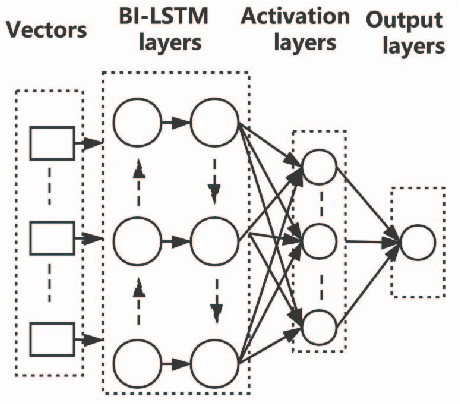
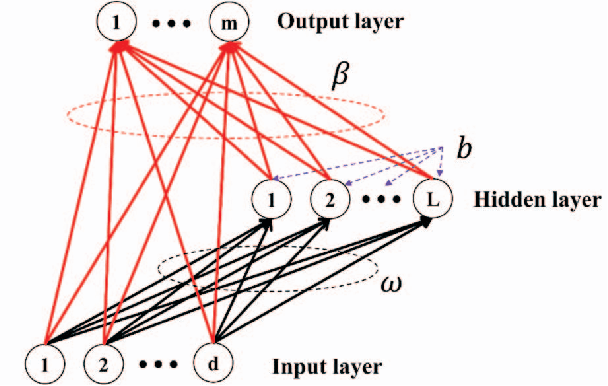
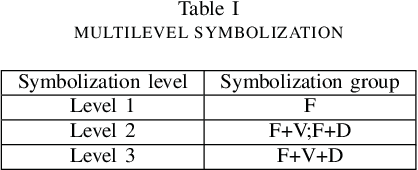
Software vulnerabilities are usually caused by design flaws or implementation errors, which could be exploited to cause damage to the security of the system. At present, the most commonly used method for detecting software vulnerabilities is static analysis. Most of the related technologies work based on rules or code similarity (source code level) and rely on manually defined vulnerability features. However, these rules and vulnerability features are difficult to be defined and designed accurately, which makes static analysis face many challenges in practical applications. To alleviate this problem, some researchers have proposed to use neural networks that have the ability of automatic feature extraction to improve the intelligence of detection. However, there are many types of neural networks, and different data preprocessing methods will have a significant impact on model performance. It is a great challenge for engineers and researchers to choose a proper neural network and data preprocessing method for a given problem. To solve this problem, we have conducted extensive experiments to test the performance of the two most typical neural networks (i.e., Bi-LSTM and RVFL) with the two most classical data preprocessing methods (i.e., the vector representation and the program symbolization methods) on software vulnerability detection problems and obtained a series of interesting research conclusions, which can provide valuable guidelines for researchers and engineers. Specifically, we found that 1) the training speed of RVFL is always faster than BiLSTM, but the prediction accuracy of Bi-LSTM model is higher than RVFL; 2) using doc2vec for vector representation can make the model have faster training speed and generalization ability than using word2vec; and 3) multi-level symbolization is helpful to improve the precision of neural network models.