 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangSurf: Language-Embedded Surface Gaussians for 3D Scene Understanding
Dec 24, 2024



Applying Gaussian Splatting to perception tasks for 3D scene understanding is becoming increasingly popular. Most existing works primarily focus on rendering 2D feature maps from novel viewpoints, which leads to an imprecise 3D language field with outlier languages, ultimately failing to align objects in 3D space. By utilizing masked images for feature extraction, these approaches also lack essential contextual information, leading to inaccurate feature representation. To this end, we propose a Language-Embedded Surface Field (LangSurf), which accurately aligns the 3D language fields with the surface of objects, facilitating precise 2D and 3D segmentation with text query, widely expanding the downstream tasks such as removal and editing. The core of LangSurf is a joint training strategy that flattens the language Gaussian on the object surfaces using geometry supervision and contrastive losses to assign accurate language features to the Gaussians of objects. In addition, we also introduce the Hierarchical-Context Awareness Module to extract features at the image level for contextual information then perform hierarchical mask pooling using masks segmented by SAM to obtain fine-grained language features in different hierarchies. Extensive experiments on open-vocabulary 2D and 3D semantic segmentation demonstrate that LangSurf outperforms the previous state-of-the-art method LangSplat by a large margin. As shown in Fig. 1, our method is capable of segmenting objects in 3D space, thus boosting the effectiveness of our approach in instance recognition, removal, and editing, which is also supported by comprehensive experiments. \url{https://langsurf.github.io}.
Unsupervised Pre-training with Language-Vision Prompts for Low-Data Instance Segmentation
May 22, 2024
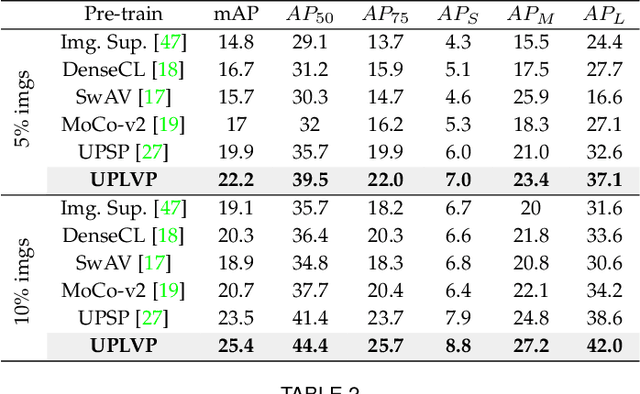


In recent times, following the paradigm of DETR (DEtection TRansformer), query-based end-to-end instance segmentation (QEIS) methods have exhibited superior performance compared to CNN-based models, particularly when trained on large-scale datasets. Nevertheless, the effectiveness of these QEIS methods diminishes significantly when confronted with limited training data. This limitation arises from their reliance on substantial data volumes to effectively train the pivotal queries/kernels that are essential for acquiring localization and shape priors. To address this problem, we propose a novel method for unsupervised pre-training in low-data regimes. Inspired by the recently successful prompting technique, we introduce a new method, Unsupervised Pre-training with Language-Vision Prompts (UPLVP), which improves QEIS models' instance segmentation by bringing language-vision prompts to queries/kernels. Our method consists of three parts: (1) Masks Proposal: Utilizes language-vision models to generate pseudo masks based on unlabeled images. (2) Prompt-Kernel Matching: Converts pseudo masks into prompts and injects the best-matched localization and shape features to their corresponding kernels. (3) Kernel Supervision: Formulates supervision for pre-training at the kernel level to ensure robust learning. With the help of our pre-training method, QEIS models can converge faster and perform better than CNN-based models in low-data regimes. Experimental evaluations conducted on MS COCO, Cityscapes, and CTW1500 datasets indicate that the QEIS models' performance can be significantly improved when pre-trained with our method. Code will be available at: https://github.com/lifuguan/UPLVP.