 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeN-GLARE: An Non-Generative Latent Representation-Efficient LLM Safety Evaluator
Nov 18, 2025Evaluating the safety robustness of LLMs is critical for their deployment. However, mainstream Red Teaming methods rely on online generation and black-box output analysis. These approaches are not only costly but also suffer from feedback latency, making them unsuitable for agile diagnostics after training a new model. To address this, we propose N-GLARE (A Non-Generative, Latent Representation-Efficient LLM Safety Evaluator). N-GLARE operates entirely on the model's latent representations, bypassing the need for full text generation. It characterizes hidden layer dynamics by analyzing the APT (Angular-Probabilistic Trajectory) of latent representations and introducing the JSS (Jensen-Shannon Separability) metric. Experiments on over 40 models and 20 red teaming strategies demonstrate that the JSS metric exhibits high consistency with the safety rankings derived from Red Teaming. N-GLARE reproduces the discriminative trends of large-scale red-teaming tests at less than 1\% of the token cost and the runtime cost, providing an efficient output-free evaluation proxy for real-time diagnostics.
Concept Enhancement Engineering: A Lightweight and Efficient Robust Defense Against Jailbreak Attacks in Embodied AI
Apr 15, 2025


Embodied Intelligence (EI) systems integrated with large language models (LLMs) face significant security risks, particularly from jailbreak attacks that manipulate models into generating harmful outputs or executing unsafe physical actions. Traditional defense strategies, such as input filtering and output monitoring, often introduce high computational overhead or interfere with task performance in real-time embodied scenarios. To address these challenges, we propose Concept Enhancement Engineering (CEE), a novel defense framework that leverages representation engineering to enhance the safety of embodied LLMs by dynamically steering their internal activations. CEE operates by (1) extracting multilingual safety patterns from model activations, (2) constructing control directions based on safety-aligned concept subspaces, and (3) applying subspace concept rotation to reinforce safe behavior during inference. Our experiments demonstrate that CEE effectively mitigates jailbreak attacks while maintaining task performance, outperforming existing defense methods in both robustness and efficiency. This work contributes a scalable and interpretable safety mechanism for embodied AI, bridging the gap between theoretical representation engineering and practical security applications. Our findings highlight the potential of latent-space interventions as a viable defense paradigm against emerging adversarial threats in physically grounded AI systems.
DFG-NAS: Deep and Flexible Graph Neural Architecture Search
Jun 17, 2022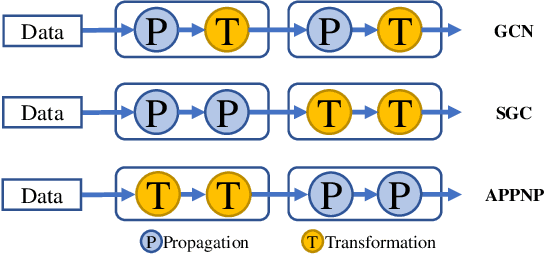
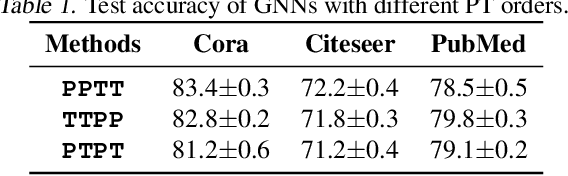
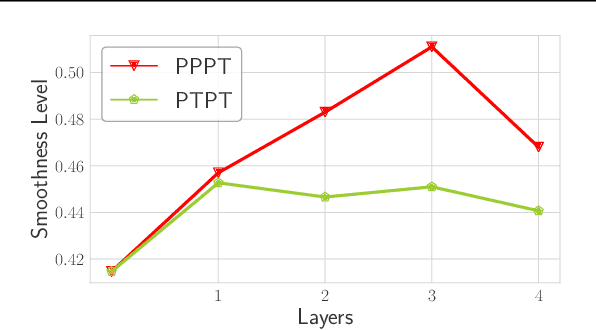
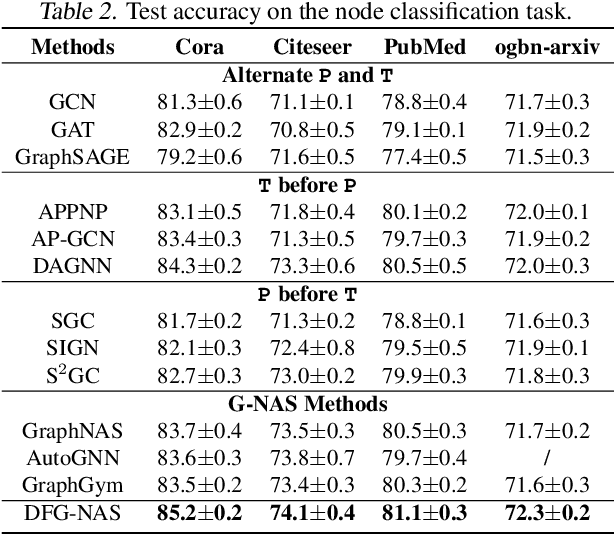
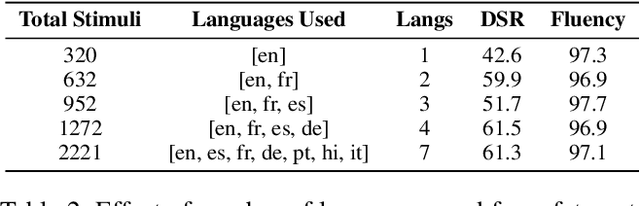
Graph neural networks (GNNs) have been intensively applied to various graph-based applications. Despite their success, manually designing the well-behaved GNNs requires immense human expertise. And thus it is inefficient to discover the potentially optimal data-specific GNN architecture. This paper proposes DFG-NAS, a new neural architecture search (NAS) method that enables the automatic search of very deep and flexible GNN architectures. Unlike most existing methods that focus on micro-architectures, DFG-NAS highlights another level of design: the search for macro-architectures on how atomic propagation (\textbf{\texttt{P}}) and transformation (\textbf{\texttt{T}}) operations are integrated and organized into a GNN. To this end, DFG-NAS proposes a novel search space for \textbf{\texttt{P-T}} permutations and combinations based on message-passing dis-aggregation, defines four custom-designed macro-architecture mutations, and employs the evolutionary algorithm to conduct an efficient and effective search. Empirical studies on four node classification tasks demonstrate that DFG-NAS outperforms state-of-the-art manual designs and NAS methods of GNNs.
* 13 pages, 7 figures
PaSca: a Graph Neural Architecture Search System under the Scalable Paradigm
Mar 01, 2022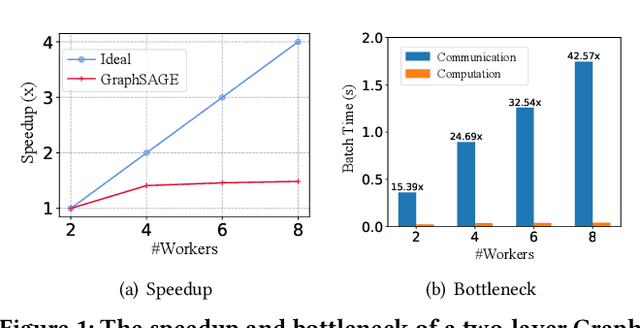
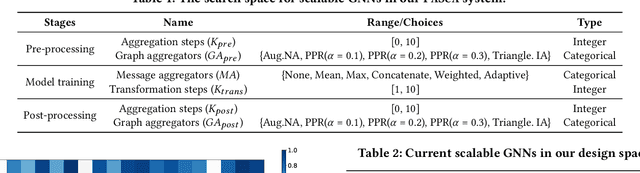
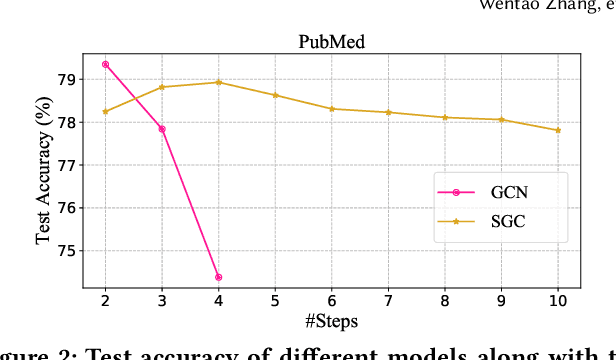

Graph neural networks (GNNs) have achieved state-of-the-art performance in various graph-based tasks. However, as mainstream GNNs are designed based on the neural message passing mechanism, they do not scale well to data size and message passing steps. Although there has been an emerging interest in the design of scalable GNNs, current researches focus on specific GNN design, rather than the general design space, limiting the discovery of potential scalable GNN models. This paper proposes PasCa, a new paradigm and system that offers a principled approach to systemically construct and explore the design space for scalable GNNs, rather than studying individual designs. Through deconstructing the message passing mechanism, PasCa presents a novel Scalable Graph Neural Architecture Paradigm (SGAP), together with a general architecture design space consisting of 150k different designs. Following the paradigm, we implement an auto-search engine that can automatically search well-performing and scalable GNN architectures to balance the trade-off between multiple criteria (e.g., accuracy and efficiency) via multi-objective optimization. Empirical studies on ten benchmark datasets demonstrate that the representative instances (i.e., PasCa-V1, V2, and V3) discovered by our system achieve consistent performance among competitive baselines. Concretely, PasCa-V3 outperforms the state-of-the-art GNN method JK-Net by 0.4\% in terms of predictive accuracy on our large industry dataset while achieving up to $28.3\times$ training speedups.
* 13 pages, 8 figures. arXiv admin note: text overlap with arXiv:2104.09880
GMLP: Building Scalable and Flexible Graph Neural Networks with Feature-Message Passing
Apr 20, 2021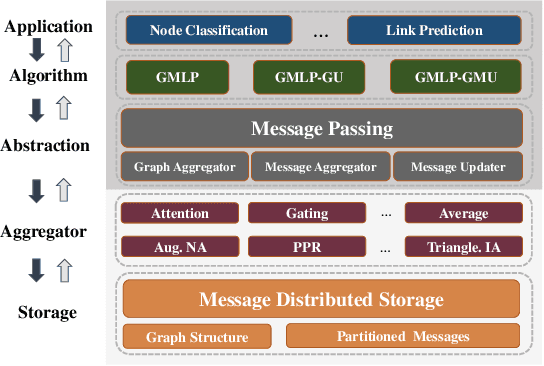
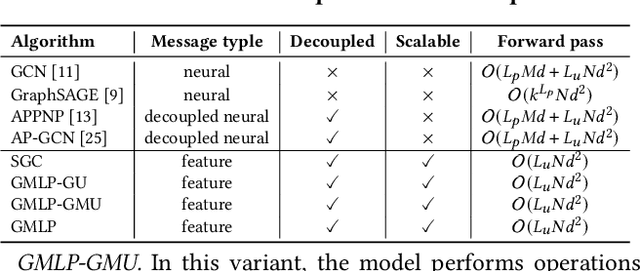
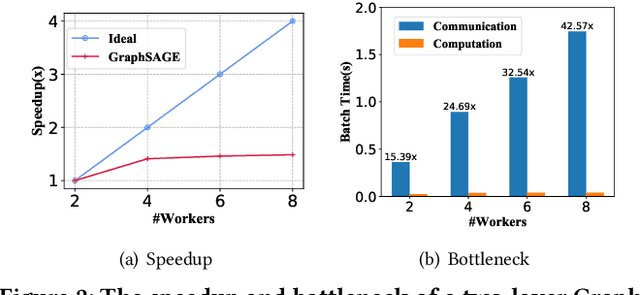
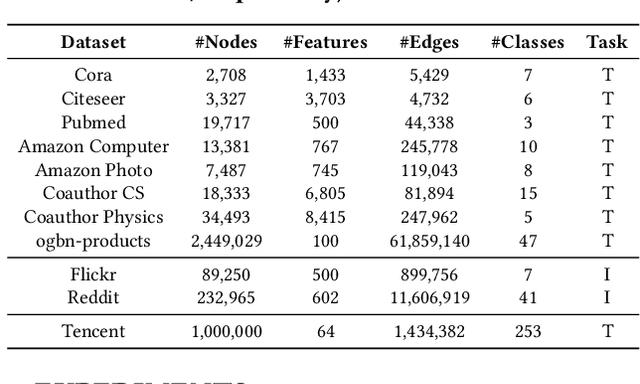
In recent studies, neural message passing has proved to be an effective way to design graph neural networks (GNNs), which have achieved state-of-the-art performance in many graph-based tasks. However, current neural-message passing architectures typically need to perform an expensive recursive neighborhood expansion in multiple rounds and consequently suffer from a scalability issue. Moreover, most existing neural-message passing schemes are inflexible since they are restricted to fixed-hop neighborhoods and insensitive to the actual demands of different nodes. We circumvent these limitations by a novel feature-message passing framework, called Graph Multi-layer Perceptron (GMLP), which separates the neural update from the message passing. With such separation, GMLP significantly improves the scalability and efficiency by performing the message passing procedure in a pre-compute manner, and is flexible and adaptive in leveraging node feature messages over various levels of localities. We further derive novel variants of scalable GNNs under this framework to achieve the best of both worlds in terms of performance and efficiency. We conduct extensive evaluations on 11 benchmark datasets, including large-scale datasets like ogbn-products and an industrial dataset, demonstrating that GMLP achieves not only the state-of-art performance, but also high training scalability and efficiency.