 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen saliency goes off on a tangent: Interpreting Deep Neural Networks with nonlinear saliency maps
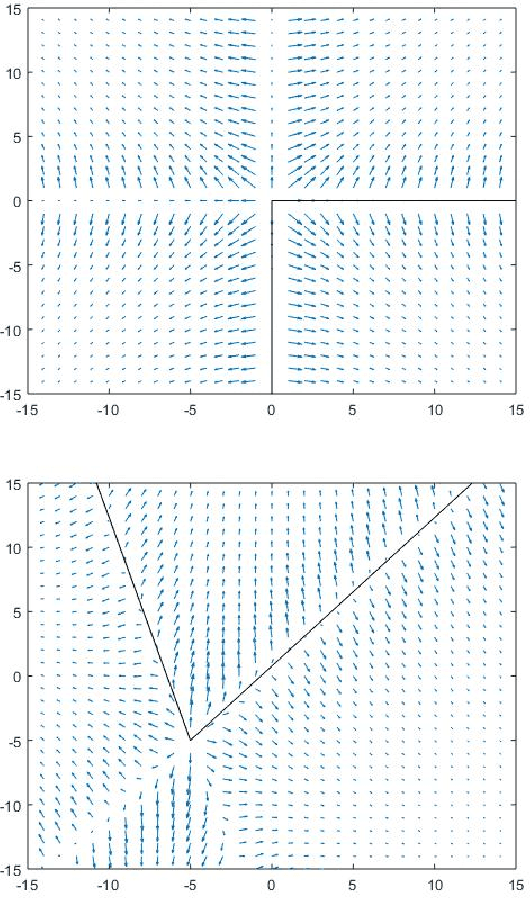
Oct 13, 2021A fundamental bottleneck in utilising complex machine learning systems for critical applications has been not knowing why they do and what they do, thus preventing the development of any crucial safety protocols. To date, no method exist that can provide full insight into the granularity of the neural network's decision process. In the past, saliency maps were an early attempt at resolving this problem through sensitivity calculations, whereby dimensions of a data point are selected based on how sensitive the output of the system is to them. However, the success of saliency maps has been at best limited, mainly due to the fact that they interpret the underlying learning system through a linear approximation. We present a novel class of methods for generating nonlinear saliency maps which fully account for the nonlinearity of the underlying learning system. While agreeing with linear saliency maps on simple problems where linear saliency maps are correct, they clearly identify more specific drivers of classification on complex examples where nonlinearities are more pronounced. This new class of methods significantly aids interpretability of deep neural networks and related machine learning systems. Crucially, they provide a starting point for their more broad use in serious applications, where 'why' is equally important as 'what'.
Goldilocks Neural Networks
Feb 26, 2020
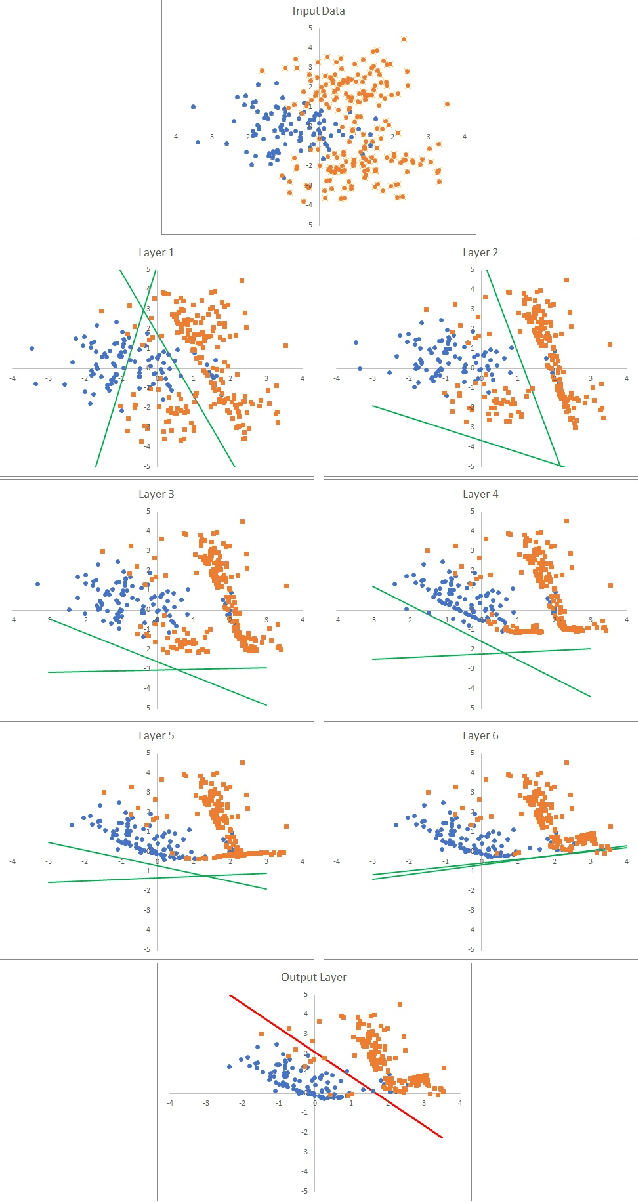
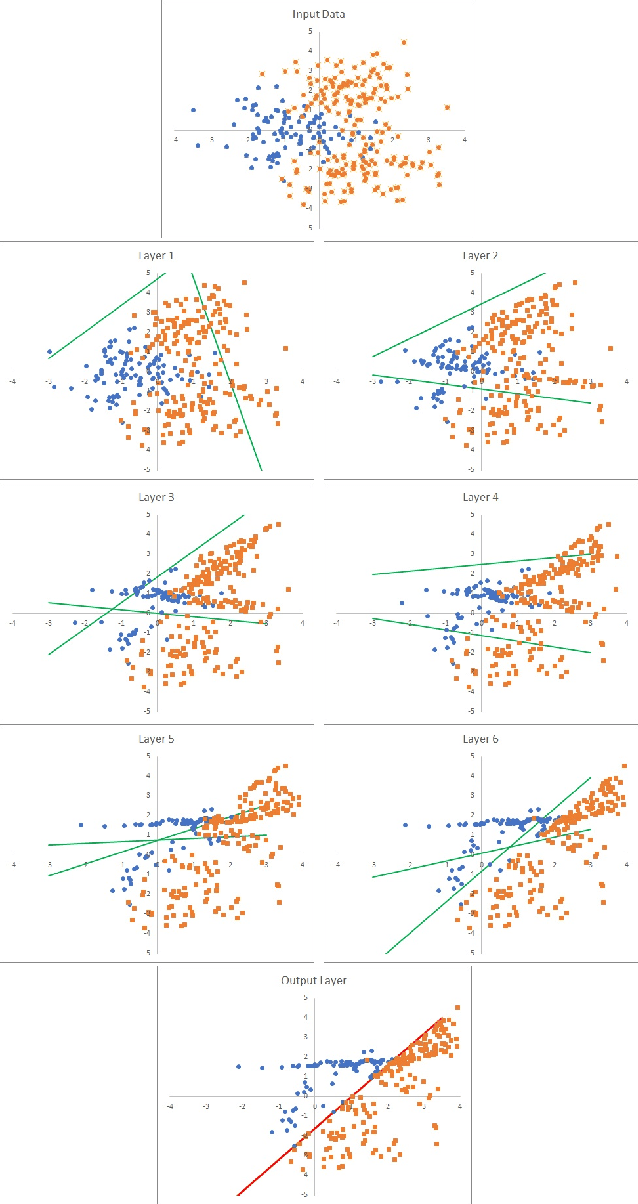
We introduce the new "Goldilocks" class of activation functions, which non-linearly deform the input signal only locally when the input signal is in the appropriate range. The small local deformation of the signal enables better understanding of how and why the signal is transformed through the layers. Numerical results on CIFAR-10 and CIFAR-100 data sets show that Goldilocks networks perform better than, or comparably to SELU and RELU, while introducing tractability of data deformation through the layers.