 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Classification of Phonetic Segments in Child Speech Using Raw Ultrasound Imaging
Feb 27, 2024



Speech sound disorder (SSD) is defined as a persistent impairment in speech sound production leading to reduced speech intelligibility and hindered verbal communication. Early recognition and intervention of children with SSD and timely referral to speech and language therapists (SLTs) for treatment are crucial. Automated detection of speech impairment is regarded as an efficient method for examining and screening large populations. This study focuses on advancing the automatic diagnosis of SSD in early childhood by proposing a technical solution that integrates ultrasound tongue imaging (UTI) with deep-learning models. The introduced FusionNet model combines UTI data with the extracted texture features to classify UTI. The overarching aim is to elevate the accuracy and efficiency of UTI analysis, particularly for classifying speech sounds associated with SSD. This study compared the FusionNet approach with standard deep-learning methodologies, highlighting the excellent improvement results of the FusionNet model in UTI classification and the potential of multi-learning in improving UTI classification in speech therapy clinics.
Automatic audiovisual synchronisation for ultrasound tongue imaging
May 31, 2021

Ultrasound tongue imaging is used to visualise the intra-oral articulators during speech production. It is utilised in a range of applications, including speech and language therapy and phonetics research. Ultrasound and speech audio are recorded simultaneously, and in order to correctly use this data, the two modalities should be correctly synchronised. Synchronisation is achieved using specialised hardware at recording time, but this approach can fail in practice resulting in data of limited usability. In this paper, we address the problem of automatically synchronising ultrasound and audio after data collection. We first investigate the tolerance of expert ultrasound users to synchronisation errors in order to find the thresholds for error detection. We use these thresholds to define accuracy scoring boundaries for evaluating our system. We then describe our approach for automatic synchronisation, which is driven by a self-supervised neural network, exploiting the correlation between the two signals to synchronise them. We train our model on data from multiple domains with different speaker characteristics, different equipment, and different recording environments, and achieve an accuracy >92.4% on held-out in-domain data. Finally, we introduce a novel resource, the Cleft dataset, which we gathered with a new clinical subgroup and for which hardware synchronisation proved unreliable. We apply our model to this out-of-domain data, and evaluate its performance subjectively with expert users. Results show that users prefer our model's output over the original hardware output 79.3% of the time. Our results demonstrate the strength of our approach and its ability to generalise to data from new domains.
Exploiting ultrasound tongue imaging for the automatic detection of speech articulation errors
Feb 27, 2021

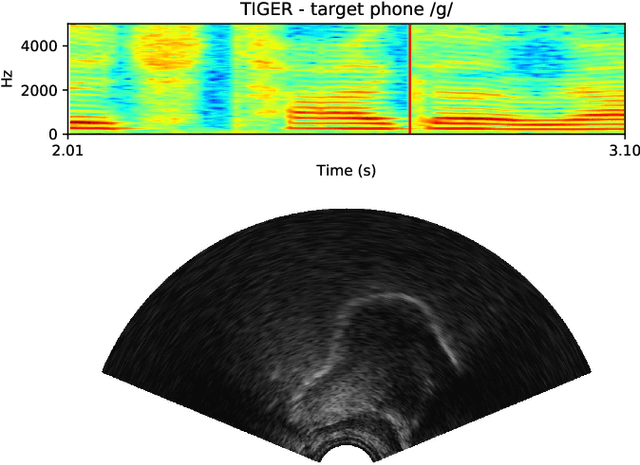
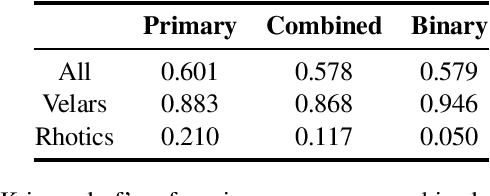
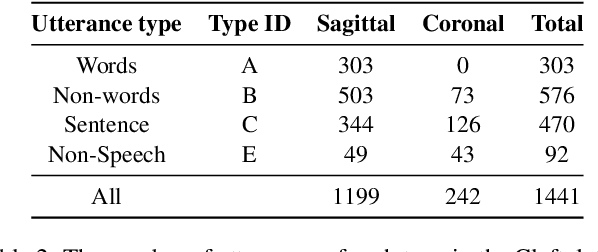
Speech sound disorders are a common communication impairment in childhood. Because speech disorders can negatively affect the lives and the development of children, clinical intervention is often recommended. To help with diagnosis and treatment, clinicians use instrumented methods such as spectrograms or ultrasound tongue imaging to analyse speech articulations. Analysis with these methods can be laborious for clinicians, therefore there is growing interest in its automation. In this paper, we investigate the contribution of ultrasound tongue imaging for the automatic detection of speech articulation errors. Our systems are trained on typically developing child speech and augmented with a database of adult speech using audio and ultrasound. Evaluation on typically developing speech indicates that pre-training on adult speech and jointly using ultrasound and audio gives the best results with an accuracy of 86.9%. To evaluate on disordered speech, we collect pronunciation scores from experienced speech and language therapists, focusing on cases of velar fronting and gliding of /r/. The scores show good inter-annotator agreement for velar fronting, but not for gliding errors. For automatic velar fronting error detection, the best results are obtained when jointly using ultrasound and audio. The best system correctly detects 86.6% of the errors identified by experienced clinicians. Out of all the segments identified as errors by the best system, 73.2% match errors identified by clinicians. Results on automatic gliding detection are harder to interpret due to poor inter-annotator agreement, but appear promising. Overall findings suggest that automatic detection of speech articulation errors has potential to be integrated into ultrasound intervention software for automatically quantifying progress during speech therapy.
* 15 pages, 9 figures, 6 tables
UltraSuite: A Repository of Ultrasound and Acoustic Data from Child Speech Therapy Sessions
Jul 01, 2019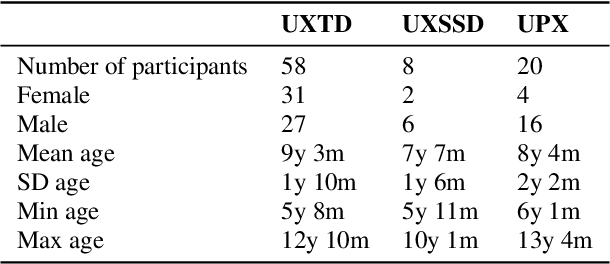

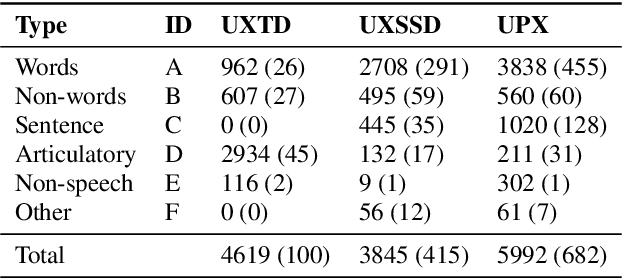
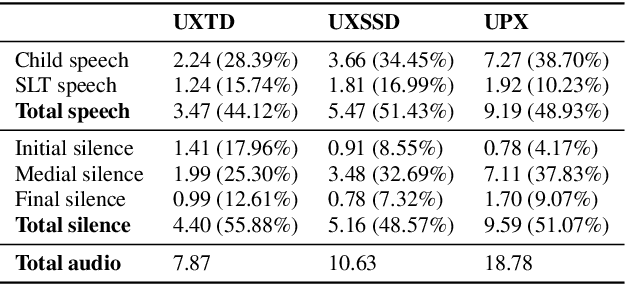
We introduce UltraSuite, a curated repository of ultrasound and acoustic data, collected from recordings of child speech therapy sessions. This release includes three data collections, one from typically developing children and two from children with speech sound disorders. In addition, it includes a set of annotations, some manual and some automatically produced, and software tools to process, transform and visualise the data.