 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASBERT: Siamese and Triplet network embedding for open question answering
Paper and Code
Apr 17, 2021
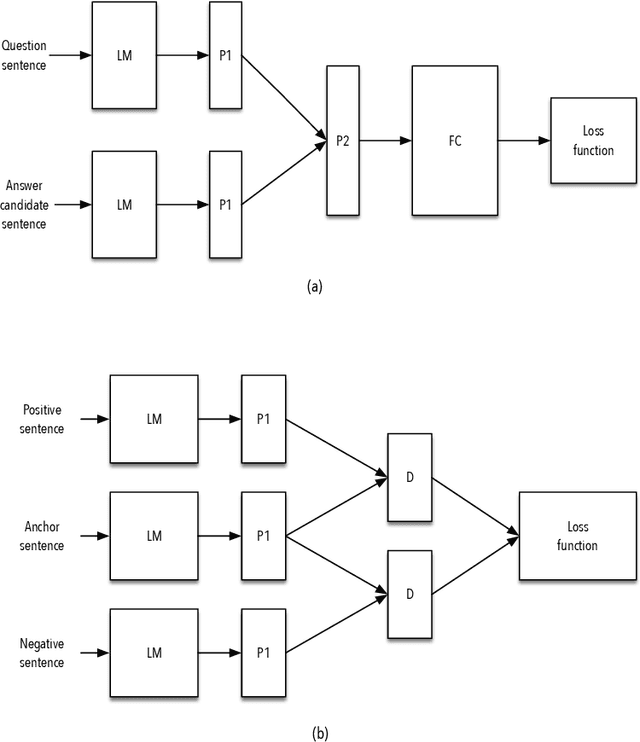
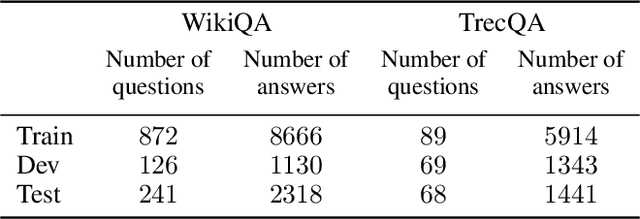
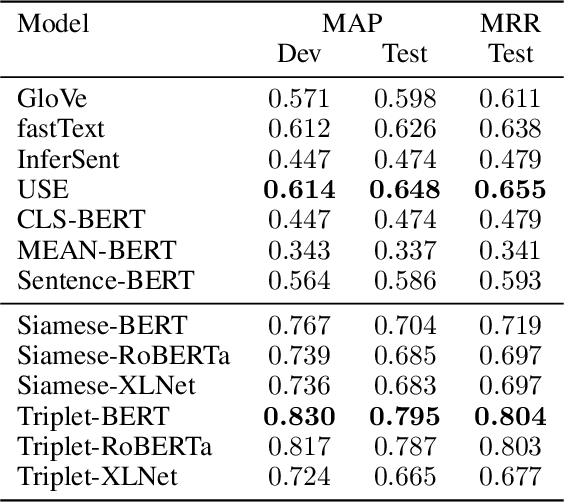
Answer selection (AS) is an essential subtask in the field of natural language processing with an objective to identify the most likely answer to a given question from a corpus containing candidate answer sentences. A common approach to address the AS problem is to generate an embedding for each candidate sentence and query. Then, select the sentence whose vector representation is closest to the query's. A key drawback is the low quality of the embeddings, hitherto, based on its performance on AS benchmark datasets. In this work, we present ASBERT, a framework built on the BERT architecture that employs Siamese and Triplet neural networks to learn an encoding function that maps a text to a fixed-size vector in an embedded space. The notion of distance between two points in this space connotes similarity in meaning between two texts. Experimental results on the WikiQA and TrecQA datasets demonstrate that our proposed approach outperforms many state-of-the-art baseline methods.