 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Modeling of ICD Codes in EHR Foundation Models
Jun 13, 2026Electronic health record foundation models typically treat ICD diagnosis codes as flat tokens, overlooking the clinically meaningful hierarchical structure that captures disease families, subcategories, and fine-grained diagnostic detail. As a result, existing EHR representation learning methods do not explicitly exploit the hierarchical structure already present in the coding system. In this work, we study ICD-10-CM hierarchy as a general inductive bias for clinical representation learning. We investigate two complementary mechanisms for incorporating hierarchy: first, by augmenting diagnosis sequences in a BERT-style transformer with tokens corresponding to different levels of the ICD hierarchy, and second, by injecting hierarchy into graph-based code representations through hierarchy-aware edges combined with diagnosis co-occurrence structure. Across these settings, we evaluate whether explicit hierarchy improves downstream prediction, which levels of the hierarchy are most useful, whether hierarchy encoding improves transfer across datasets, and how hierarchy reshapes embedding similarity structure. We conduct experiments on two large-scale real-world clinical datasets: MIMIC-IV, used for pretraining and in-domain evaluation, and eICU, used to assess cross-dataset transfer via frozen encoder probing. Our findings show that explicitly encoding ICD hierarchy improves over flat code representations in both in-domain and cross-dataset settings, while revealing that the most useful level of hierarchy depends on both the task and the modeling approach. More broadly, we focus on hierarchy-aware EHR representation learning and show that the benefits of encoding hierarchy are generalizable across modeling settings and hierarchy levels.
Wavelet-Driven Masked Multiscale Reconstruction for PPG Foundation Models
Jan 18, 2026Wearable foundation models have the potential to transform digital health by learning transferable representations from large-scale biosignals collected in everyday settings. While recent progress has been made in large-scale pretraining, most approaches overlook the spectral structure of photoplethysmography (PPG) signals, wherein physiological rhythms unfold across multiple frequency bands. Motivated by the insight that many downstream health-related tasks depend on multi-resolution features spanning fine-grained waveform morphology to global rhythmic dynamics, we introduce Masked Multiscale Reconstruction (MMR) for PPG representation learning - a self-supervised pretraining framework that explicitly learns from hierarchical time-frequency scales of PPG data. The pretraining task is designed to reconstruct randomly masked out coefficients obtained from a wavelet-based multiresolution decomposition of PPG signals, forcing the transformer encoder to integrate information across temporal and spectral scales. We pretrain our model with MMR using ~17 million unlabeled 10-second PPG segments from ~32,000 smartwatch users. On 17 of 19 diverse health-related tasks, MMR trained on large-scale wearable PPG data improves over or matches state-of-the-art open-source PPG foundation models, time-series foundation models, and other self-supervised baselines. Extensive analysis of our learned embeddings and systematic ablations underscores the value of wavelet-based representations, showing that they capture robust and physiologically-grounded features. Together, these results highlight the potential of MMR as a step toward generalizable PPG foundation models.
AgentSense: Virtual Sensor Data Generation Using LLM Agents in Simulated Home Environments
Jun 16, 2025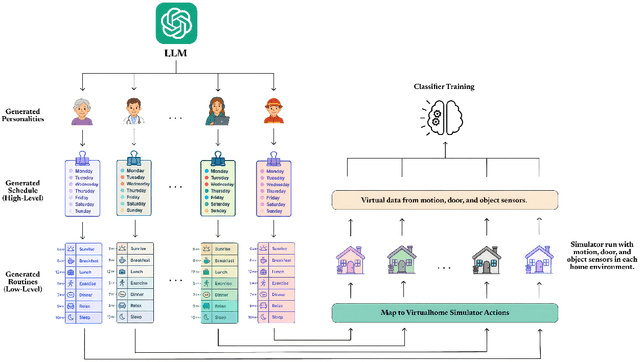
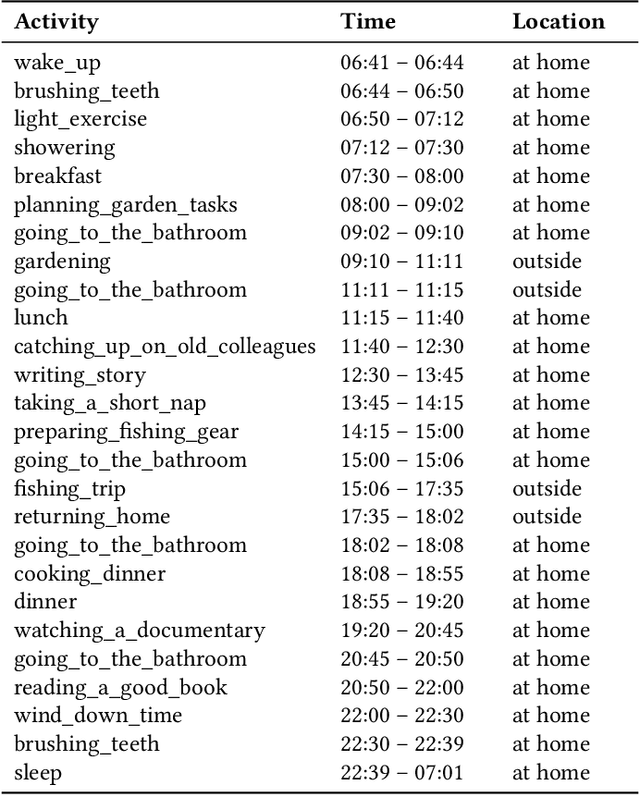
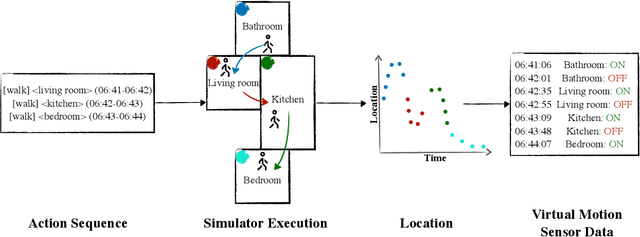
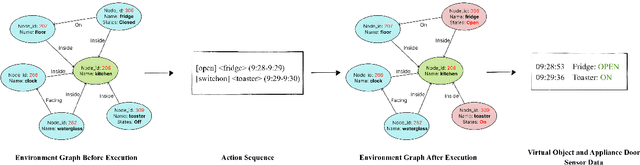
A major obstacle in developing robust and generalizable smart home-based Human Activity Recognition (HAR) systems is the lack of large-scale, diverse labeled datasets. Variability in home layouts, sensor configurations, and user behavior adds further complexity, as individuals follow varied routines and perform activities in distinct ways. Building HAR systems that generalize well requires training data that captures the diversity across users and environments. To address these challenges, we introduce AgentSense, a virtual data generation pipeline where diverse personas are generated by leveraging Large Language Models. These personas are used to create daily routines, which are then decomposed into low-level action sequences. Subsequently, the actions are executed in a simulated home environment called VirtualHome that we extended with virtual ambient sensors capable of recording the agents activities as they unfold. Overall, AgentSense enables the generation of rich, virtual sensor datasets that represent a wide range of users and home settings. Across five benchmark HAR datasets, we show that leveraging our virtual sensor data substantially improves performance, particularly when real data are limited. Notably, models trained on a combination of virtual data and just a few days of real data achieve performance comparable to those trained on the entire real datasets. These results demonstrate and prove the potential of virtual data to address one of the most pressing challenges in ambient sensing, which is the distinct lack of large-scale, annotated datasets without requiring any manual data collection efforts.
Layout Agnostic Human Activity Recognition in Smart Homes through Textual Descriptions Of Sensor Triggers (TDOST)
May 20, 2024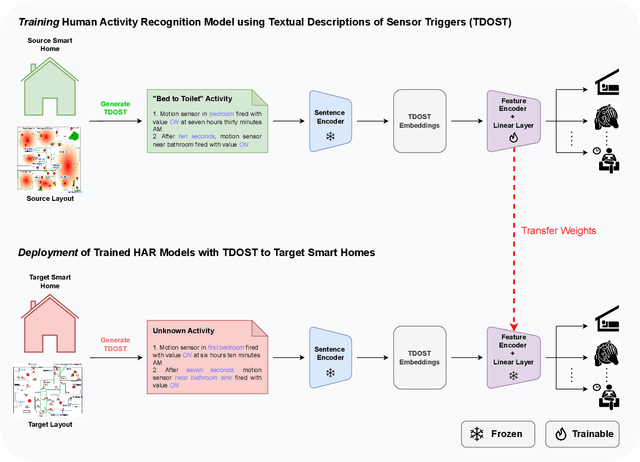
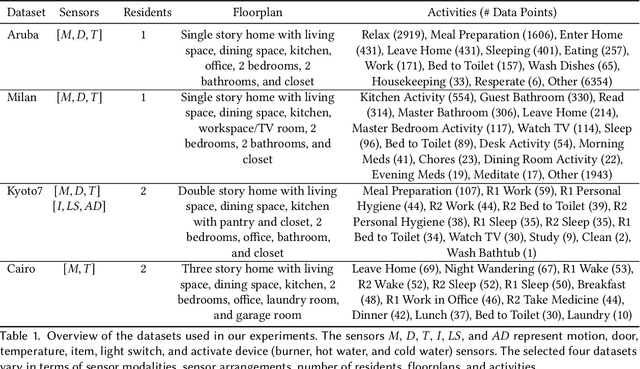
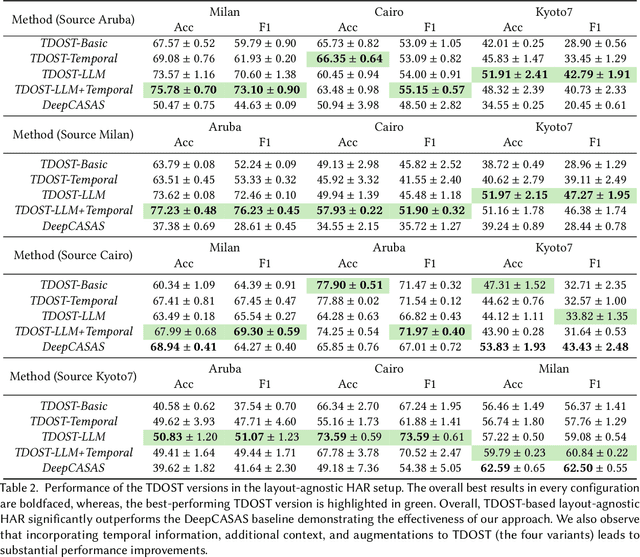
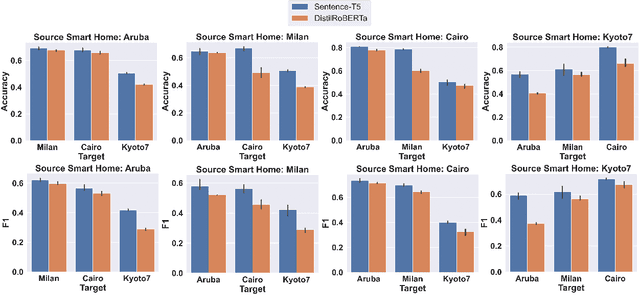
Human activity recognition (HAR) using ambient sensors in smart homes has numerous applications for human healthcare and wellness. However, building general-purpose HAR models that can be deployed to new smart home environments requires a significant amount of annotated sensor data and training overhead. Most smart homes vary significantly in their layouts, i.e., floor plans and the specifics of sensors embedded, resulting in low generalizability of HAR models trained for specific homes. We address this limitation by introducing a novel, layout-agnostic modeling approach for HAR systems in smart homes that utilizes the transferrable representational capacity of natural language descriptions of raw sensor data. To this end, we generate Textual Descriptions Of Sensor Triggers (TDOST) that encapsulate the surrounding trigger conditions and provide cues for underlying activities to the activity recognition models. Leveraging textual embeddings, rather than raw sensor data, we create activity recognition systems that predict standard activities across homes without either (re-)training or adaptation on target homes. Through an extensive evaluation, we demonstrate the effectiveness of TDOST-based models in unseen smart homes through experiments on benchmarked CASAS datasets. Furthermore, we conduct a detailed analysis of how the individual components of our approach affect downstream activity recognition performance.
Cross-Domain HAR: Few Shot Transfer Learning for Human Activity Recognition
Oct 22, 2023



The ubiquitous availability of smartphones and smartwatches with integrated inertial measurement units (IMUs) enables straightforward capturing of human activities. For specific applications of sensor based human activity recognition (HAR), however, logistical challenges and burgeoning costs render especially the ground truth annotation of such data a difficult endeavor, resulting in limited scale and diversity of datasets. Transfer learning, i.e., leveraging publicly available labeled datasets to first learn useful representations that can then be fine-tuned using limited amounts of labeled data from a target domain, can alleviate some of the performance issues of contemporary HAR systems. Yet they can fail when the differences between source and target conditions are too large and/ or only few samples from a target application domain are available, each of which are typical challenges in real-world human activity recognition scenarios. In this paper, we present an approach for economic use of publicly available labeled HAR datasets for effective transfer learning. We introduce a novel transfer learning framework, Cross-Domain HAR, which follows the teacher-student self-training paradigm to more effectively recognize activities with very limited label information. It bridges conceptual gaps between source and target domains, including sensor locations and type of activities. Through our extensive experimental evaluation on a range of benchmark datasets, we demonstrate the effectiveness of our approach for practically relevant few shot activity recognition scenarios. We also present a detailed analysis into how the individual components of our framework affect downstream performance.