 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn enhanced method of initial cluster center selection for K-means algorithm
Oct 18, 2022
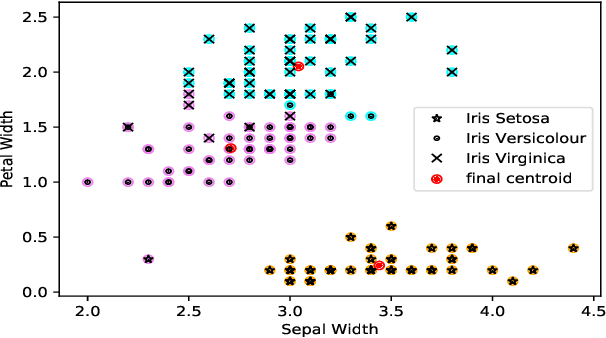
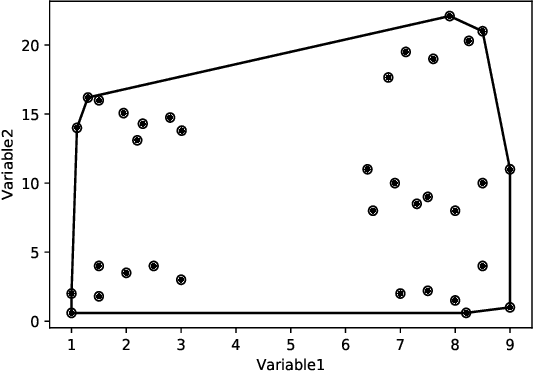
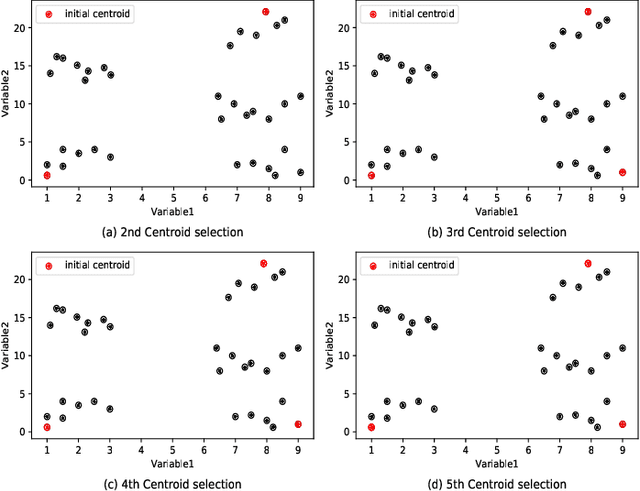
Clustering is one of the widely used techniques to find out patterns from a dataset that can be applied in different applications or analyses. K-means, the most popular and simple clustering algorithm, might get trapped into local minima if not properly initialized and the initialization of this algorithm is done randomly. In this paper, we propose a novel approach to improve initial cluster selection for K-means algorithm. This algorithm is based on the fact that the initial centroids must be well separated from each other since the final clusters are separated groups in feature space. The Convex Hull algorithm facilitates the computing of the first two centroids and the remaining ones are selected according to the distance from previously selected centers. To ensure the selection of one center per cluster, we use the nearest neighbor technique. To check the robustness of our proposed algorithm, we consider several real-world datasets. We obtained only 7.33%, 7.90%, and 0% clustering error in Iris, Letter, and Ruspini data respectively which proves better performance than other existing systems. The results indicate that our proposed method outperforms the conventional K means approach by accelerating the computation when the number of clusters is greater than 2.
* 6 pages