 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Bottleneck-Based Hebbian Learning Rule Naturally Ties Working Memory and Synaptic Updates
Nov 24, 2021
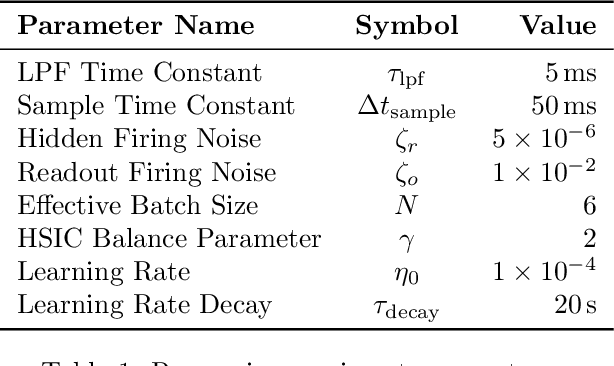

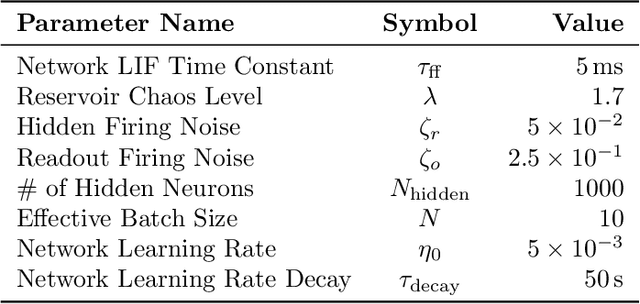
Artificial neural networks have successfully tackled a large variety of problems by training extremely deep networks via back-propagation. A direct application of back-propagation to spiking neural networks contains biologically implausible components, like the weight transport problem or separate inference and learning phases. Various methods address different components individually, but a complete solution remains intangible. Here, we take an alternate approach that avoids back-propagation and its associated issues entirely. Recent work in deep learning proposed independently training each layer of a network via the information bottleneck (IB). Subsequent studies noted that this layer-wise approach circumvents error propagation across layers, leading to a biologically plausible paradigm. Unfortunately, the IB is computed using a batch of samples. The prior work addresses this with a weight update that only uses two samples (the current and previous sample). Our work takes a different approach by decomposing the weight update into a local and global component. The local component is Hebbian and only depends on the current sample. The global component computes a layer-wise modulatory signal that depends on a batch of samples. We show that this modulatory signal can be learned by an auxiliary circuit with working memory (WM) like a reservoir. Thus, we can use batch sizes greater than two, and the batch size determines the required capacity of the WM. To the best of our knowledge, our rule is the first biologically plausible mechanism to directly couple synaptic updates with a WM of the task. We evaluate our rule on synthetic datasets and image classification datasets like MNIST, and we explore the effect of the WM capacity on learning performance. We hope our work is a first-step towards understanding the mechanistic role of memory in learning.
Accelerating Deep Learning with Dynamic Data Pruning
Nov 24, 2021



Deep learning's success has been attributed to the training of large, overparameterized models on massive amounts of data. As this trend continues, model training has become prohibitively costly, requiring access to powerful computing systems to train state-of-the-art networks. A large body of research has been devoted to addressing the cost per iteration of training through various model compression techniques like pruning and quantization. Less effort has been spent targeting the number of iterations. Previous work, such as forget scores and GraNd/EL2N scores, address this problem by identifying important samples within a full dataset and pruning the remaining samples, thereby reducing the iterations per epoch. Though these methods decrease the training time, they use expensive static scoring algorithms prior to training. When accounting for the scoring mechanism, the total run time is often increased. In this work, we address this shortcoming with dynamic data pruning algorithms. Surprisingly, we find that uniform random dynamic pruning can outperform the prior work at aggressive pruning rates. We attribute this to the existence of "sometimes" samples -- points that are important to the learned decision boundary only some of the training time. To better exploit the subtlety of sometimes samples, we propose two algorithms, based on reinforcement learning techniques, to dynamically prune samples and achieve even higher accuracy than the random dynamic method. We test all our methods against a full-dataset baseline and the prior work on CIFAR-10 and CIFAR-100, and we can reduce the training time by up to 2x without significant performance loss. Our results suggest that data pruning should be understood as a dynamic process that is closely tied to a model's training trajectory, instead of a static step based solely on the dataset alone.
BlurNet: Defense by Filtering the Feature Maps
Aug 06, 2019


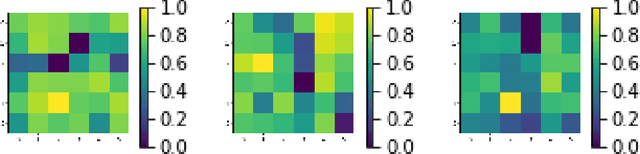
Recently, the field of adversarial machine learning has been garnering attention by showing that state-of-the-art deep neural networks are vulnerable to adverserial examples, stemming from small perturbations being added to the input image. Adversarial examples are generated by a malicious adversary by obtaining access to the model parameters, such as gradient information, to alter the input or by attacking a substitute model and transferring those malicious examples over to attack the victim model. Specifically, one of these attack algorithms, Robust Physical Perturbations ($RP_2$), generates adverserial images of stop signs with black and white stickers to achieve high targeted misclassification rates against standard-architecture traffic sign classifiers. In this paper, we propose BlurNet, a defense against the $RP_2$ attack. First, we motivate the defense with a frequency analysis of the first layer feature maps of the network on the LISA dataset by demonstrating high frequency noise is introduced into the input image by the $RP_2$ algorithm. To alleviate the high frequency, we introduce a depthwise convolution layer of standard blur kernels after the first layer. Finally, we present a regularization scheme to incorporate this low-pass filtering behavior into the training regime of the network.