 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Model For All: Partial Diffusion for Unified Try-On and Try-Off in Any Pose
Aug 06, 2025Recent diffusion-based approaches have made significant advances in image-based virtual try-on, enabling more realistic and end-to-end garment synthesis. However, most existing methods remain constrained by their reliance on exhibition garments and segmentation masks, as well as their limited ability to handle flexible pose variations. These limitations reduce their practicality in real-world scenarios-for instance, users cannot easily transfer garments worn by one person onto another, and the generated try-on results are typically restricted to the same pose as the reference image. In this paper, we introduce \textbf{OMFA} (\emph{One Model For All}), a unified diffusion framework for both virtual try-on and try-off that operates without the need for exhibition garments and supports arbitrary poses. For example, OMFA enables removing garments from a source person (try-off) and transferring them onto a target person (try-on), while also allowing the generated target to appear in novel poses-even without access to multi-pose images of that person. OMFA is built upon a novel \emph{partial diffusion} strategy that selectively applies noise and denoising to individual components of the joint input-such as the garment, the person image, or the face-enabling dynamic subtask control and efficient bidirectional garment-person transformation. The framework is entirely mask-free and requires only a single portrait and a target pose as input, making it well-suited for real-world applications. Additionally, by leveraging SMPL-X-based pose conditioning, OMFA supports multi-view and arbitrary-pose try-on from just one image. Extensive experiments demonstrate that OMFA achieves state-of-the-art results on both try-on and try-off tasks, providing a practical and generalizable solution for virtual garment synthesis. The project page is here: https://onemodelforall.github.io/.
Causality-aware Concept Extraction based on Knowledge-guided Prompting
May 10, 2023Concepts benefit natural language understanding but are far from complete in existing knowledge graphs (KGs). Recently, pre-trained language models (PLMs) have been widely used in text-based concept extraction (CE). However, PLMs tend to mine the co-occurrence associations from massive corpus as pre-trained knowledge rather than the real causal effect between tokens. As a result, the pre-trained knowledge confounds PLMs to extract biased concepts based on spurious co-occurrence correlations, inevitably resulting in low precision. In this paper, through the lens of a Structural Causal Model (SCM), we propose equipping the PLM-based extractor with a knowledge-guided prompt as an intervention to alleviate concept bias. The prompt adopts the topic of the given entity from the existing knowledge in KGs to mitigate the spurious co-occurrence correlations between entities and biased concepts. Our extensive experiments on representative multilingual KG datasets justify that our proposed prompt can effectively alleviate concept bias and improve the performance of PLM-based CE models.The code has been released on https://github.com/siyuyuan/KPCE.
Generative Entity Typing with Curriculum Learning
Oct 06, 2022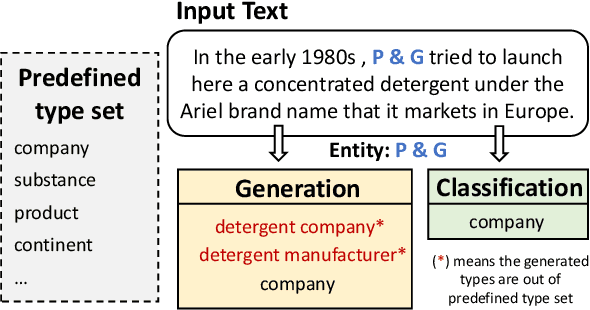

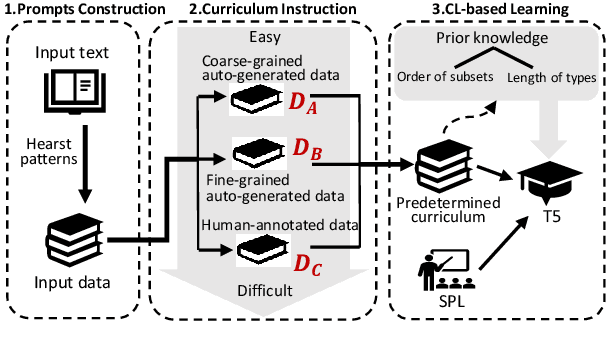

Entity typing aims to assign types to the entity mentions in given texts. The traditional classification-based entity typing paradigm has two unignorable drawbacks: 1) it fails to assign an entity to the types beyond the predefined type set, and 2) it can hardly handle few-shot and zero-shot situations where many long-tail types only have few or even no training instances. To overcome these drawbacks, we propose a novel generative entity typing (GET) paradigm: given a text with an entity mention, the multiple types for the role that the entity plays in the text are generated with a pre-trained language model (PLM). However, PLMs tend to generate coarse-grained types after fine-tuning upon the entity typing dataset. Besides, we only have heterogeneous training data consisting of a small portion of human-annotated data and a large portion of auto-generated but low-quality data. To tackle these problems, we employ curriculum learning (CL) to train our GET model upon the heterogeneous data, where the curriculum could be self-adjusted with the self-paced learning according to its comprehension of the type granularity and data heterogeneity. Our extensive experiments upon the datasets of different languages and downstream tasks justify the superiority of our GET model over the state-of-the-art entity typing models. The code has been released on https://github.com/siyuyuan/GET.