 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-Based Local Feature Matching for Multimodal Image Registration
Apr 25, 2024Ultrasound imaging is a cost-effective and radiation-free modality for visualizing anatomical structures in real-time, making it ideal for guiding surgical interventions. However, its limited field-of-view, speckle noise, and imaging artifacts make it difficult to interpret the images for inexperienced users. In this paper, we propose a new 2D ultrasound to 3D CT registration method to improve surgical guidance during ultrasound-guided interventions. Our approach adopts a dense feature matching method called LoFTR to our multimodal registration problem. We learn to predict dense coarse-to-fine correspondences using a Transformer-based architecture to estimate a robust rigid transformation between a 2D ultrasound frame and a CT scan. Additionally, a fully differentiable pose estimation method is introduced, optimizing LoFTR on pose estimation error during training. Experiments conducted on a multimodal dataset of ex vivo porcine kidneys demonstrate the method's promising results for intraoperative, trackerless ultrasound pose estimation. By mapping 2D ultrasound frames into the 3D CT volume space, the method provides intraoperative guidance, potentially improving surgical workflows and image interpretation.
Double-Uncertainty Assisted Spatial and Temporal Regularization Weighting for Learning-based Registration
Jul 15, 2021


In order to tackle the difficulty associated with the ill-posed nature of the image registration problem, researchers use regularization to constrain the solution space. For most learning-based registration approaches, the regularization usually has a fixed weight and only constrains the spatial transformation. Such convention has two limitations: (1) The regularization strength of a specific image pair should be associated with the content of the images, thus the ``one value fits all'' scheme is not ideal; (2) Only spatially regularizing the transformation (but overlooking the temporal consistency of different estimations) may not be the best strategy to cope with the ill-posedness. In this study, we propose a mean-teacher based registration framework. This framework incorporates an additional \textit{temporal regularization} term by encouraging the teacher model's temporal ensemble prediction to be consistent with that of the student model. At each training step, it also automatically adjusts the weights of the \textit{spatial regularization} and the \textit{temporal regularization} by taking account of the transformation uncertainty and appearance uncertainty derived from the perturbed teacher model. We perform experiments on multi- and uni-modal registration tasks, and the results show that our strategy outperforms the traditional and learning-based benchmark methods.
Noisy Labels are Treasure: Mean-Teacher-Assisted Confident Learning for Hepatic Vessel Segmentation
Jun 03, 2021

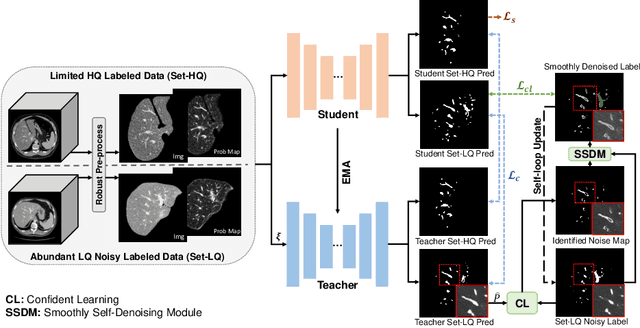

Manually segmenting the hepatic vessels from Computer Tomography (CT) is far more expertise-demanding and laborious than other structures due to the low-contrast and complex morphology of vessels, resulting in the extreme lack of high-quality labeled data. Without sufficient high-quality annotations, the usual data-driven learning-based approaches struggle with deficient training. On the other hand, directly introducing additional data with low-quality annotations may confuse the network, leading to undesirable performance degradation. To address this issue, we propose a novel mean-teacher-assisted confident learning framework to robustly exploit the noisy labeled data for the challenging hepatic vessel segmentation task. Specifically, with the adapted confident learning assisted by a third party, i.e., the weight-averaged teacher model, the noisy labels in the additional low-quality dataset can be transformed from "encumbrance" to "treasure" via progressive pixel-wise soft-correction, thus providing productive guidance. Extensive experiments using two public datasets demonstrate the superiority of the proposed framework as well as the effectiveness of each component.
Unsupervised Multimodal Image Registration with Adaptative Gradient Guidance
Nov 12, 2020

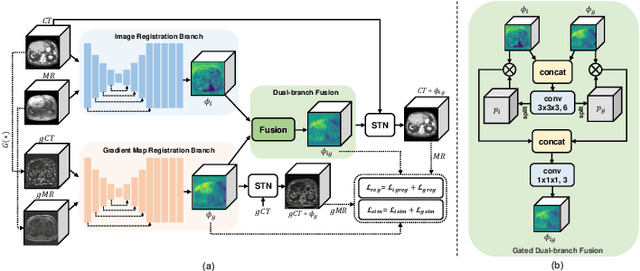

Multimodal image registration (MIR) is a fundamental procedure in many image-guided therapies. Recently, unsupervised learning-based methods have demonstrated promising performance over accuracy and efficiency in deformable image registration. However, the estimated deformation fields of the existing methods fully rely on the to-be-registered image pair. It is difficult for the networks to be aware of the mismatched boundaries, resulting in unsatisfactory organ boundary alignment. In this paper, we propose a novel multimodal registration framework, which leverages the deformation fields estimated from both: (i) the original to-be-registered image pair, (ii) their corresponding gradient intensity maps, and adaptively fuses them with the proposed gated fusion module. With the help of auxiliary gradient-space guidance, the network can concentrate more on the spatial relationship of the organ boundary. Experimental results on two clinically acquired CT-MRI datasets demonstrate the effectiveness of our proposed approach.
Unimodal Cyclic Regularization for Training Multimodal Image Registration Networks
Nov 12, 2020
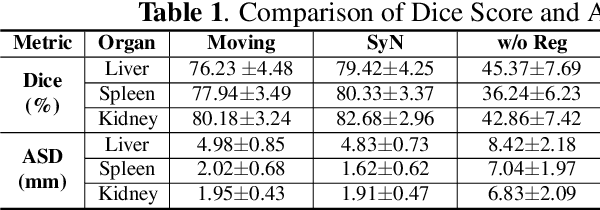

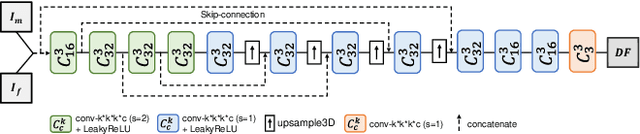
The loss function of an unsupervised multimodal image registration framework has two terms, i.e., a metric for similarity measure and regularization. In the deep learning era, researchers proposed many approaches to automatically learn the similarity metric, which has been shown effective in improving registration performance. However, for the regularization term, most existing multimodal registration approaches still use a hand-crafted formula to impose artificial properties on the estimated deformation field. In this work, we propose a unimodal cyclic regularization training pipeline, which learns task-specific prior knowledge from simpler unimodal registration, to constrain the deformation field of multimodal registration. In the experiment of abdominal CT-MR registration, the proposed method yields better results over conventional regularization methods, especially for severely deformed local regions.
Adversarial Uni- and Multi-modal Stream Networks for Multimodal Image Registration
Jul 06, 2020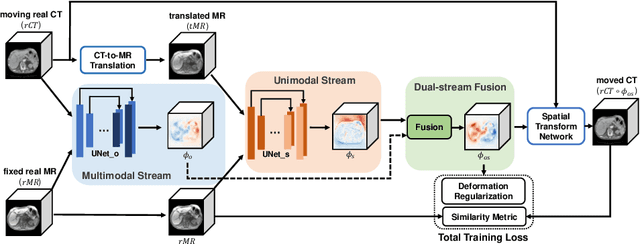



Deformable image registration between Computed Tomography (CT) images and Magnetic Resonance (MR) imaging is essential for many image-guided therapies. In this paper, we propose a novel translation-based unsupervised deformable image registration method. Distinct from other translation-based methods that attempt to convert the multimodal problem (e.g., CT-to-MR) into a unimodal problem (e.g., MR-to-MR) via image-to-image translation, our method leverages the deformation fields estimated from both: (i) the translated MR image and (ii) the original CT image in a dual-stream fashion, and automatically learns how to fuse them to achieve better registration performance. The multimodal registration network can be effectively trained by computationally efficient similarity metrics without any ground-truth deformation. Our method has been evaluated on two clinical datasets and demonstrates promising results compared to state-of-the-art traditional and learning-based methods.