 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatermarking Large Language Models and the Generated Content: Opportunities and Challenges
Paper and Code
Oct 24, 2024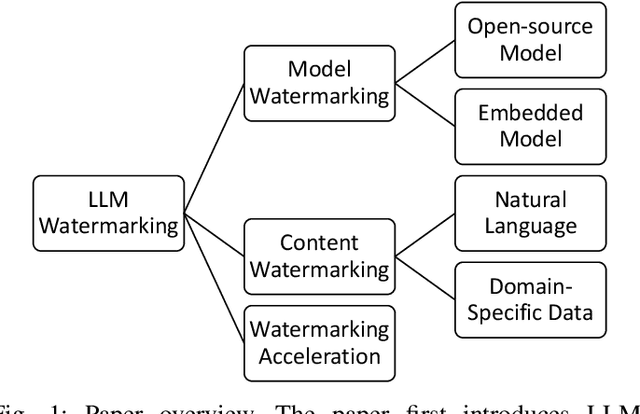



The widely adopted and powerful generative large language models (LLMs) have raised concerns about intellectual property rights violations and the spread of machine-generated misinformation. Watermarking serves as a promising approch to establish ownership, prevent unauthorized use, and trace the origins of LLM-generated content. This paper summarizes and shares the challenges and opportunities we found when watermarking LLMs. We begin by introducing techniques for watermarking LLMs themselves under different threat models and scenarios. Next, we investigate watermarking methods designed for the content generated by LLMs, assessing their effectiveness and resilience against various attacks. We also highlight the importance of watermarking domain-specific models and data, such as those used in code generation, chip design, and medical applications. Furthermore, we explore methods like hardware acceleration to improve the efficiency of the watermarking process. Finally, we discuss the limitations of current approaches and outline future research directions for the responsible use and protection of these generative AI tools.