 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Adversarial Sentences by Analyzing Text Complexity
Dec 19, 2019



Attackers create adversarial text to deceive both human perception and the current AI systems to perform malicious purposes such as spam product reviews and fake political posts. We investigate the difference between the adversarial and the original text to prevent the risk. We prove that the text written by a human is more coherent and fluent. Moreover, the human can express the idea through the flexible text with modern words while a machine focuses on optimizing the generated text by the simple and common words. We also suggest a method to identify the adversarial text by extracting the features related to our findings. The proposed method achieves high performance with 82.0% of accuracy and 18.4% of equal error rate, which is better than the existing methods whose the best accuracy is 77.0% corresponding to the error rate 22.8%.
Detecting Machine-Translated Text using Back Translation
Oct 15, 2019
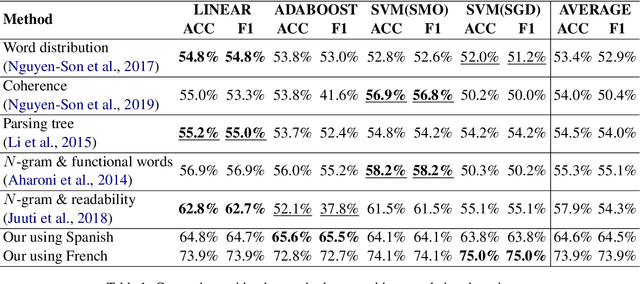
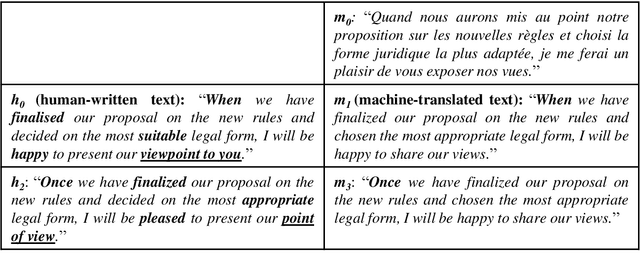
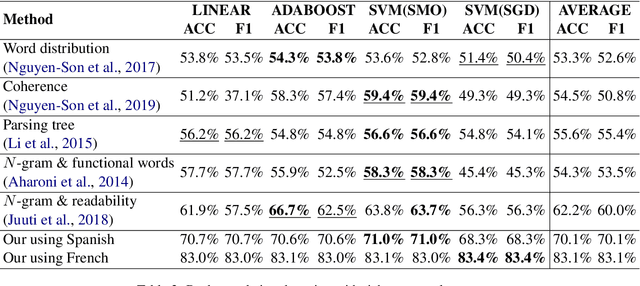
Machine-translated text plays a crucial role in the communication of people using different languages. However, adversaries can use such text for malicious purposes such as plagiarism and fake review. The existing methods detected a machine-translated text only using the text's intrinsic content, but they are unsuitable for classifying the machine-translated and human-written texts with the same meanings. We have proposed a method to extract features used to distinguish machine/human text based on the similarity between the intrinsic text and its back-translation. The evaluation of detecting translated sentences with French shows that our method achieves 75.0% of both accuracy and F-score. It outperforms the existing methods whose the best accuracy is 62.8% and the F-score is 62.7%. The proposed method even detects more efficiently the back-translated text with 83.4% of accuracy, which is higher than 66.7% of the best previous accuracy. We also achieve similar results not only with F-score but also with similar experiments related to Japanese. Moreover, we prove that our detector can recognize both machine-translated and machine-back-translated texts without the language information which is used to generate these machine texts. It demonstrates the persistence of our method in various applications in both low- and rich-resource languages.
Detecting Machine-Translated Paragraphs by Matching Similar Words
Apr 24, 2019
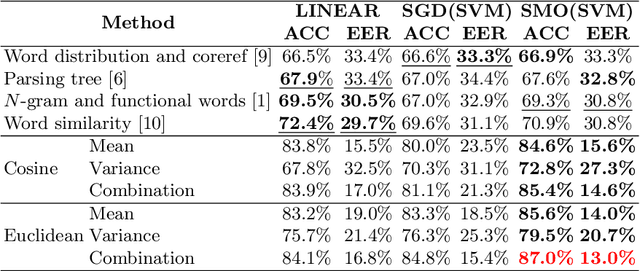

Machine-translated text plays an important role in modern life by smoothing communication from various communities using different languages. However, unnatural translation may lead to misunderstanding, a detector is thus needed to avoid the unfortunate mistakes. While a previous method measured the naturalness of continuous words using a N-gram language model, another method matched noncontinuous words across sentences but this method ignores such words in an individual sentence. We have developed a method matching similar words throughout the paragraph and estimating the paragraph-level coherence, that can identify machine-translated text. Experiment evaluates on 2000 English human-generated and 2000 English machine-translated paragraphs from German showing that the coherence-based method achieves high performance (accuracy = 87.0%; equal error rate = 13.0%). It is efficiently better than previous methods (best accuracy = 72.4%; equal error rate = 29.7%). Similar experiments on Dutch and Japanese obtain 89.2% and 97.9% accuracy, respectively. The results demonstrate the persistence of the proposed method in various languages with different resource levels.