 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Machine-Translated Text using Back Translation
Paper and Code
Oct 15, 2019
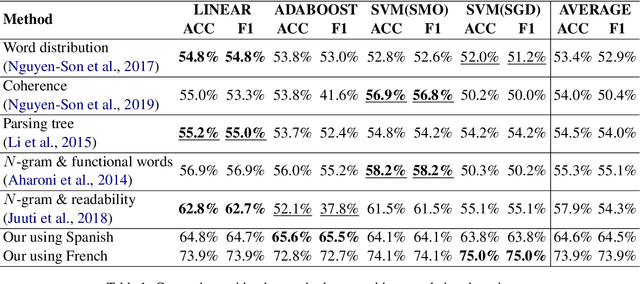
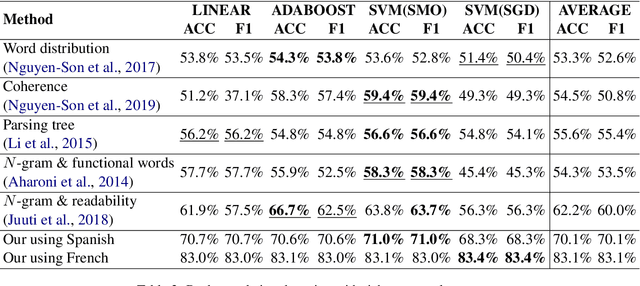
Machine-translated text plays a crucial role in the communication of people using different languages. However, adversaries can use such text for malicious purposes such as plagiarism and fake review. The existing methods detected a machine-translated text only using the text's intrinsic content, but they are unsuitable for classifying the machine-translated and human-written texts with the same meanings. We have proposed a method to extract features used to distinguish machine/human text based on the similarity between the intrinsic text and its back-translation. The evaluation of detecting translated sentences with French shows that our method achieves 75.0% of both accuracy and F-score. It outperforms the existing methods whose the best accuracy is 62.8% and the F-score is 62.7%. The proposed method even detects more efficiently the back-translated text with 83.4% of accuracy, which is higher than 66.7% of the best previous accuracy. We also achieve similar results not only with F-score but also with similar experiments related to Japanese. Moreover, we prove that our detector can recognize both machine-translated and machine-back-translated texts without the language information which is used to generate these machine texts. It demonstrates the persistence of our method in various applications in both low- and rich-resource languages.