 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdgePruner: Poisoned Edge Pruning in Graph Contrastive Learning
Dec 12, 2023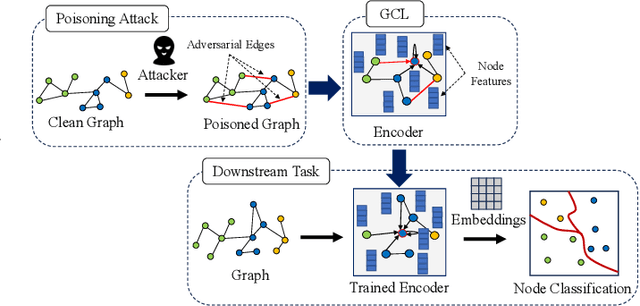
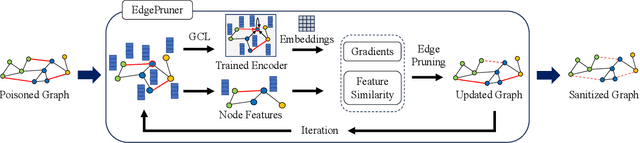
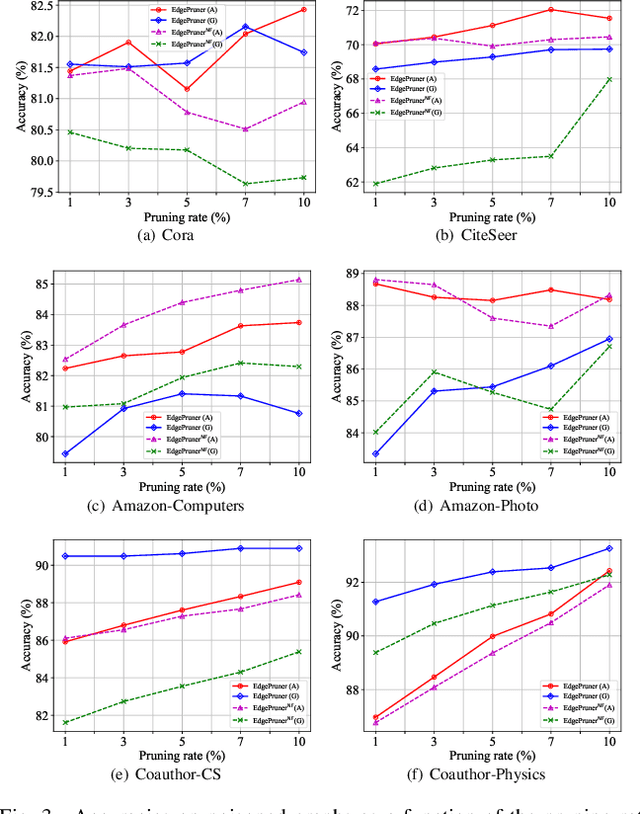
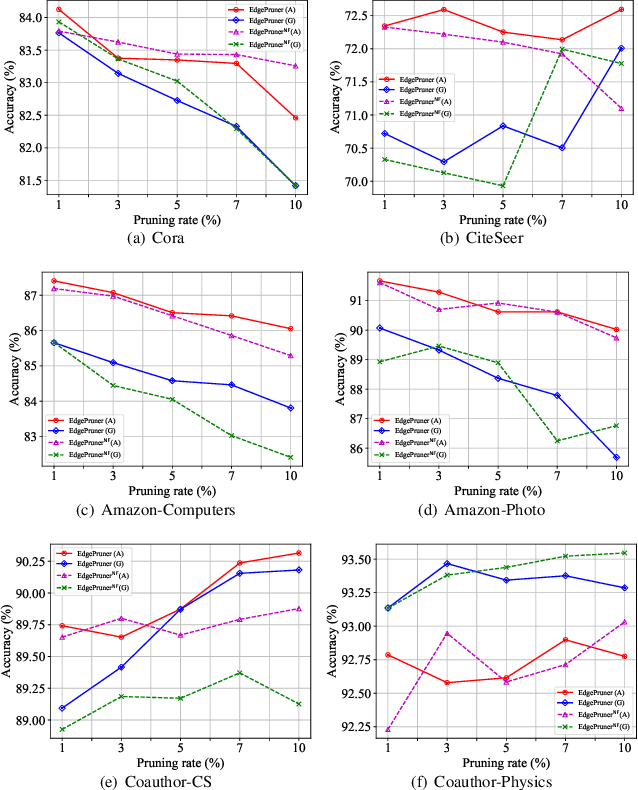
Graph Contrastive Learning (GCL) is unsupervised graph representation learning that can obtain useful representation of unknown nodes. The node representation can be utilized as features of downstream tasks. However, GCL is vulnerable to poisoning attacks as with existing learning models. A state-of-the-art defense cannot sufficiently negate adverse effects by poisoned graphs although such a defense introduces adversarial training in the GCL. To achieve further improvement, pruning adversarial edges is important. To the best of our knowledge, the feasibility remains unexplored in the GCL domain. In this paper, we propose a simple defense for GCL, EdgePruner. We focus on the fact that the state-of-the-art poisoning attack on GCL tends to mainly add adversarial edges to create poisoned graphs, which means that pruning edges is important to sanitize the graphs. Thus, EdgePruner prunes edges that contribute to minimizing the contrastive loss based on the node representation obtained after training on poisoned graphs by GCL. Furthermore, we focus on the fact that nodes with distinct features are connected by adversarial edges in poisoned graphs. Thus, we introduce feature similarity between neighboring nodes to help more appropriately determine adversarial edges. This similarity is helpful in further eliminating adverse effects from poisoned graphs on various datasets. Finally, EdgePruner outputs a graph that yields the minimum contrastive loss as the sanitized graph. Our results demonstrate that pruning adversarial edges is feasible on six datasets. EdgePruner can improve the accuracy of node classification under the attack by up to 5.55% compared with that of the state-of-the-art defense. Moreover, we show that EdgePruner is immune to an adaptive attack.
VoteTRANS: Detecting Adversarial Text without Training by Voting on Hard Labels of Transformations
Jun 02, 2023
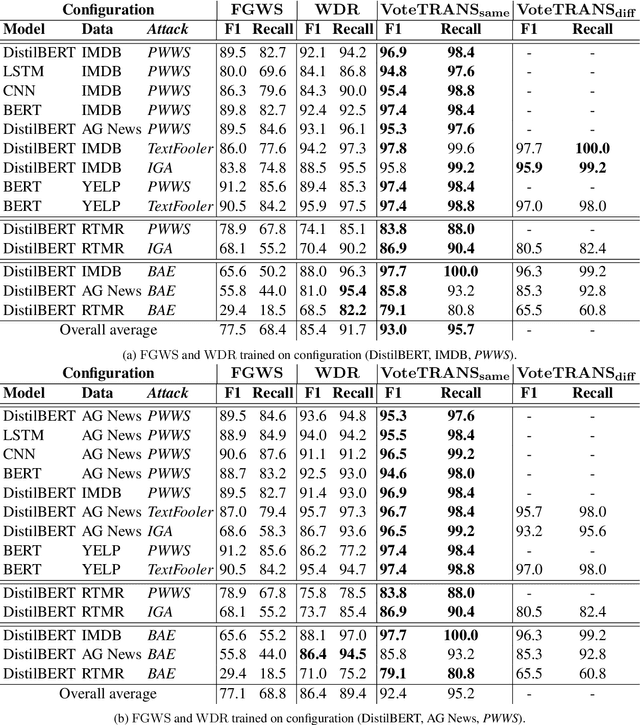
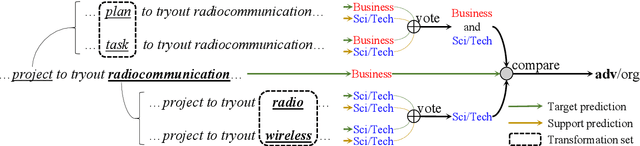

Adversarial attacks reveal serious flaws in deep learning models. More dangerously, these attacks preserve the original meaning and escape human recognition. Existing methods for detecting these attacks need to be trained using original/adversarial data. In this paper, we propose detection without training by voting on hard labels from predictions of transformations, namely, VoteTRANS. Specifically, VoteTRANS detects adversarial text by comparing the hard labels of input text and its transformation. The evaluation demonstrates that VoteTRANS effectively detects adversarial text across various state-of-the-art attacks, models, and datasets.
SEPP: Similarity Estimation of Predicted Probabilities for Defending and Detecting Adversarial Text
Oct 13, 2021
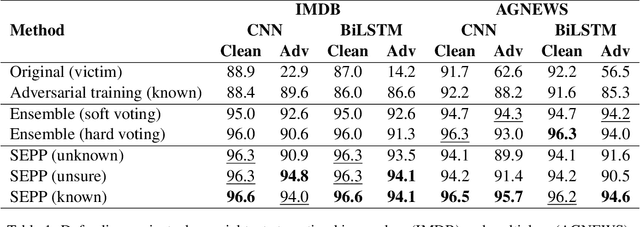
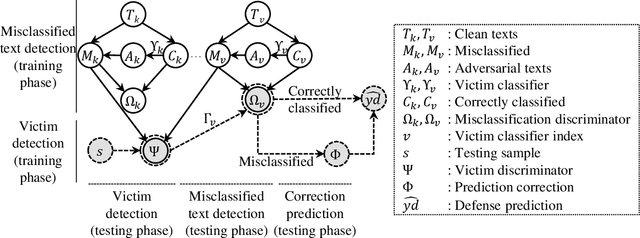
There are two cases describing how a classifier processes input text, namely, misclassification and correct classification. In terms of misclassified texts, a classifier handles the texts with both incorrect predictions and adversarial texts, which are generated to fool the classifier, which is called a victim. Both types are misunderstood by the victim, but they can still be recognized by other classifiers. This induces large gaps in predicted probabilities between the victim and the other classifiers. In contrast, text correctly classified by the victim is often successfully predicted by the others and induces small gaps. In this paper, we propose an ensemble model based on similarity estimation of predicted probabilities (SEPP) to exploit the large gaps in the misclassified predictions in contrast to small gaps in the correct classification. SEPP then corrects the incorrect predictions of the misclassified texts. We demonstrate the resilience of SEPP in defending and detecting adversarial texts through different types of victim classifiers, classification tasks, and adversarial attacks.