 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEveGuard: Defeating Vibration-based Side-Channel Eavesdropping with Audio Adversarial Perturbations
Nov 15, 2024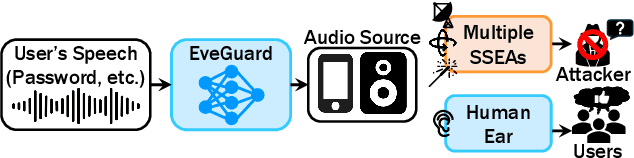


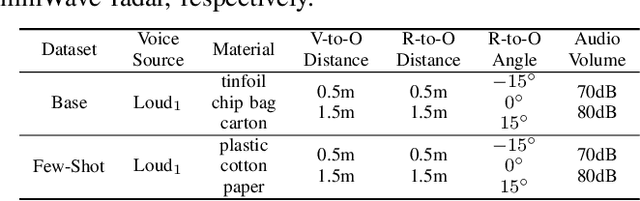
Vibrometry-based side channels pose a significant privacy risk, exploiting sensors like mmWave radars, light sensors, and accelerometers to detect vibrations from sound sources or proximate objects, enabling speech eavesdropping. Despite various proposed defenses, these involve costly hardware solutions with inherent physical limitations. This paper presents EveGuard, a software-driven defense framework that creates adversarial audio, protecting voice privacy from side channels without compromising human perception. We leverage the distinct sensing capabilities of side channels and traditional microphones where side channels capture vibrations and microphones record changes in air pressure, resulting in different frequency responses. EveGuard first proposes a perturbation generator model (PGM) that effectively suppresses sensor-based eavesdropping while maintaining high audio quality. Second, to enable end-to-end training of PGM, we introduce a new domain translation task called Eve-GAN for inferring an eavesdropped signal from a given audio. We further apply few-shot learning to mitigate the data collection overhead for Eve-GAN training. Our extensive experiments show that EveGuard achieves a protection rate of more than 97 percent from audio classifiers and significantly hinders eavesdropped audio reconstruction. We further validate the performance of EveGuard across three adaptive attack mechanisms. We have conducted a user study to verify the perceptual quality of our perturbed audio.
Magmaw: Modality-Agnostic Adversarial Attacks on Machine Learning-Based Wireless Communication Systems
Nov 01, 2023



Machine Learning (ML) has been instrumental in enabling joint transceiver optimization by merging all physical layer blocks of the end-to-end wireless communication systems. Although there have been a number of adversarial attacks on ML-based wireless systems, the existing methods do not provide a comprehensive view including multi-modality of the source data, common physical layer components, and wireless domain constraints. This paper proposes Magmaw, the first black-box attack methodology capable of generating universal adversarial perturbations for any multimodal signal transmitted over a wireless channel. We further introduce new objectives for adversarial attacks on ML-based downstream applications. The resilience of the attack to the existing widely used defense methods of adversarial training and perturbation signal subtraction is experimentally verified. For proof-of-concept evaluation, we build a real-time wireless attack platform using a software-defined radio system. Experimental results demonstrate that Magmaw causes significant performance degradation even in the presence of the defense mechanisms. Surprisingly, Magmaw is also effective against encrypted communication channels and conventional communications.
NetFlick: Adversarial Flickering Attacks on Deep Learning Based Video Compression
Apr 04, 2023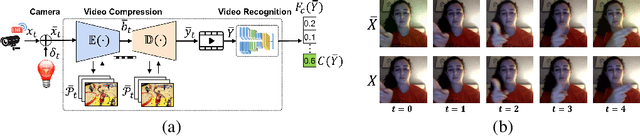
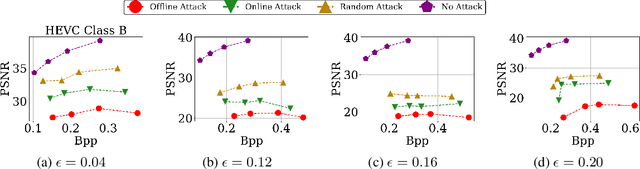
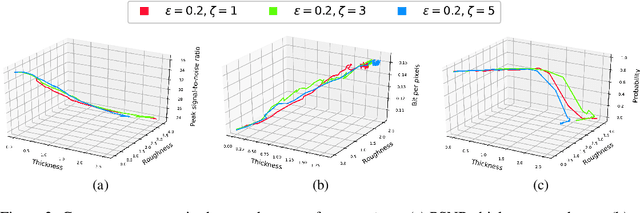
Video compression plays a significant role in IoT devices for the efficient transport of visual data while satisfying all underlying bandwidth constraints. Deep learning-based video compression methods are rapidly replacing traditional algorithms and providing state-of-the-art results on edge devices. However, recently developed adversarial attacks demonstrate that digitally crafted perturbations can break the Rate-Distortion relationship of video compression. In this work, we present a real-world LED attack to target video compression frameworks. Our physically realizable attack, dubbed NetFlick, can degrade the spatio-temporal correlation between successive frames by injecting flickering temporal perturbations. In addition, we propose universal perturbations that can downgrade performance of incoming video without prior knowledge of the contents. Experimental results demonstrate that NetFlick can successfully deteriorate the performance of video compression frameworks in both digital- and physical-settings and can be further extended to attack downstream video classification networks.
Adversarial Attacks on Deep Learning-based Video Compression and Classification Systems
Mar 18, 2022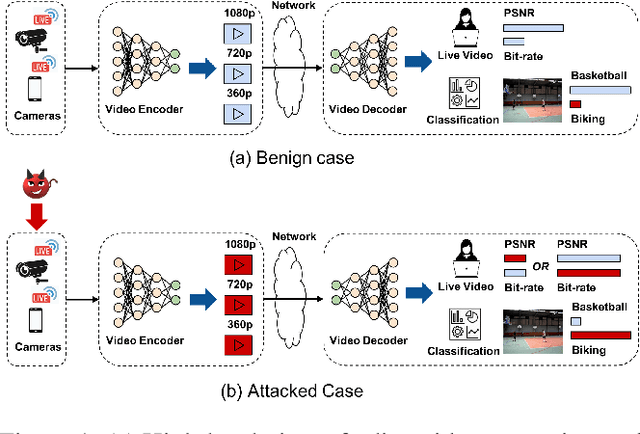
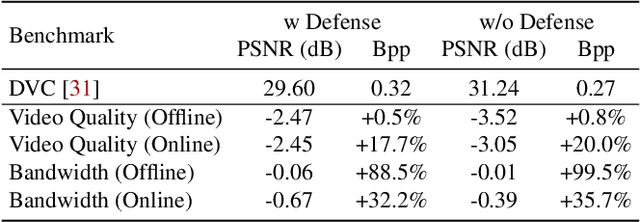
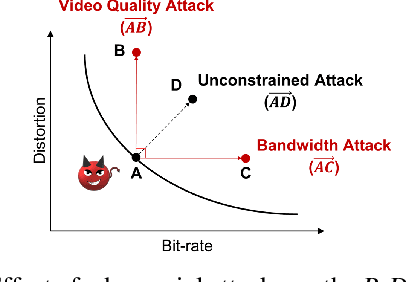
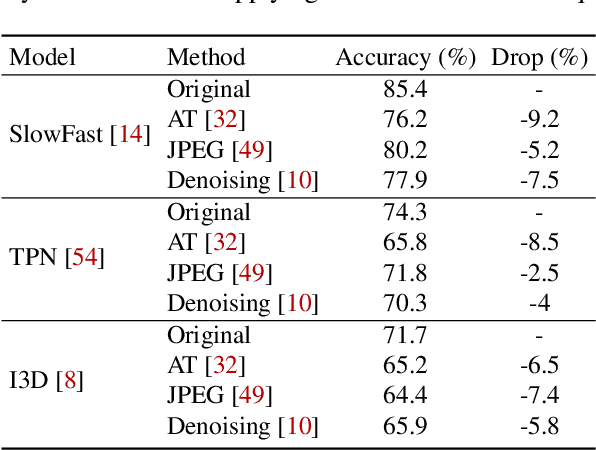
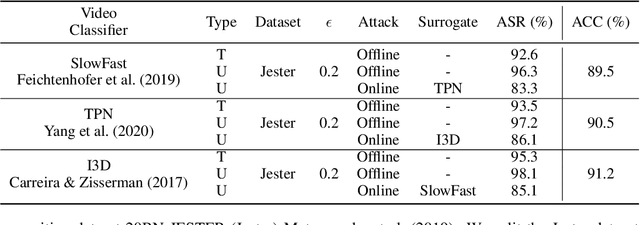
Video compression plays a crucial role in enabling video streaming and classification systems and maximizing the end-user quality of experience (QoE) at a given bandwidth budget. In this paper, we conduct the first systematic study for adversarial attacks on deep learning based video compression and downstream classification systems. We propose an adaptive adversarial attack that can manipulate the Rate-Distortion (R-D) relationship of a video compression model to achieve two adversarial goals: (1) increasing the network bandwidth or (2) degrading the video quality for end-users. We further devise novel objectives for targeted and untargeted attacks to a downstream video classification service. Finally, we design an input-invariant perturbation that universally disrupts video compression and classification systems in real time. Unlike previously proposed attacks on video classification, our adversarial perturbations are the first to withstand compression. We empirically show the resilience of our attacks against various defenses, i.e., adversarial training, video denoising, and JPEG compression. Our extensive experimental results on various video datasets demonstrate the effectiveness of our attacks. Our video quality and bandwidth attacks deteriorate peak signal-to-noise ratio by up to 5.4dB and the bit-rate by up to 2.4 times on the standard video compression datasets while achieving over 90% attack success rate on a downstream classifier.
An Efficient Accelerator Design Methodology for Deformable Convolutional Networks
Jun 13, 2020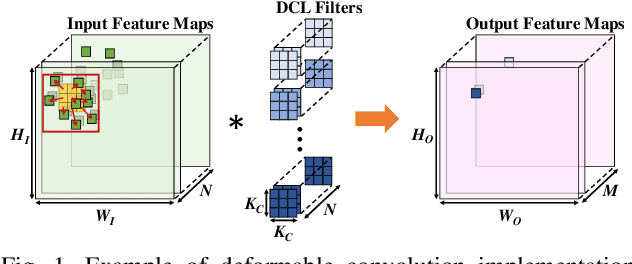
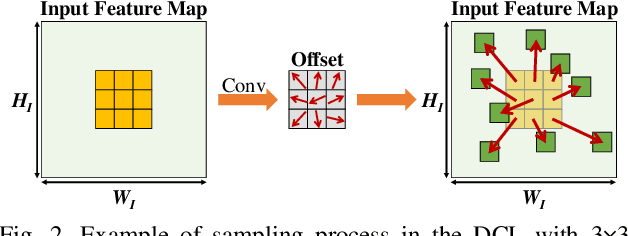
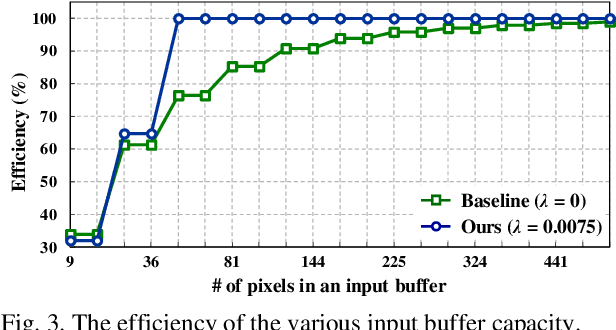
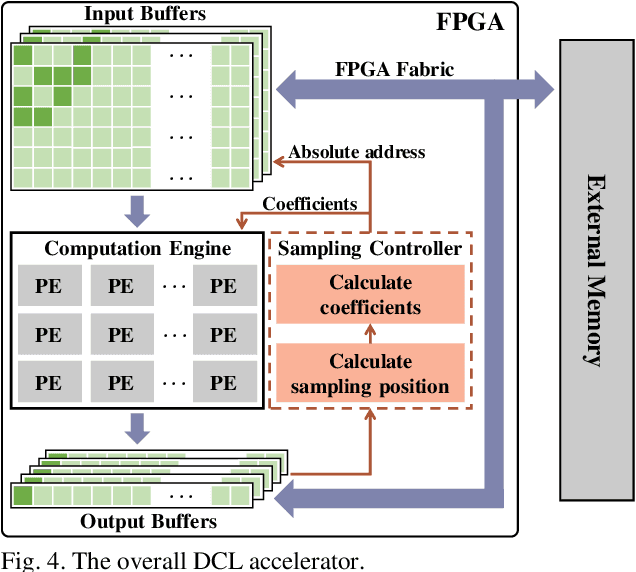
Deformable convolutional networks have demonstrated outstanding performance in object recognition tasks with an effective feature extraction. Unlike standard convolution, the deformable convolution decides the receptive field size using dynamically generated offsets, which leads to an irregular memory access. Especially, the memory access pattern varies both spatially and temporally, making static optimization ineffective. Thus, a naive implementation would lead to an excessive memory footprint. In this paper, we present a novel approach to accelerate deformable convolution on FPGA. First, we propose a novel training method to reduce the size of the receptive field in the deformable convolutional layer without compromising accuracy. By optimizing the receptive field, we can compress the maximum size of the receptive field by 12.6 times. Second, we propose an efficient systolic architecture to maximize its efficiency. We then implement our design on FPGA to support the optimized dataflow. Experimental results show that our accelerator achieves up to 17.25 times speedup over the state-of-the-art accelerator.
Towards Design Methodology of Efficient Fast Algorithms for Accelerating Generative Adversarial Networks on FPGAs
Nov 15, 2019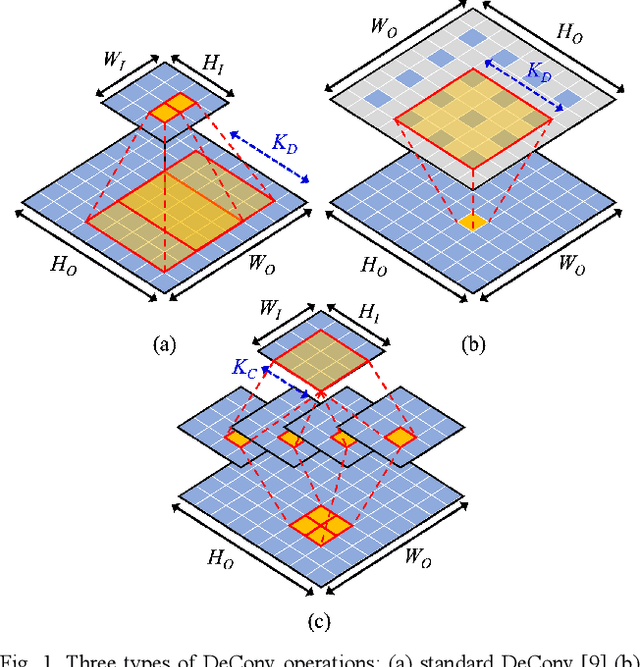
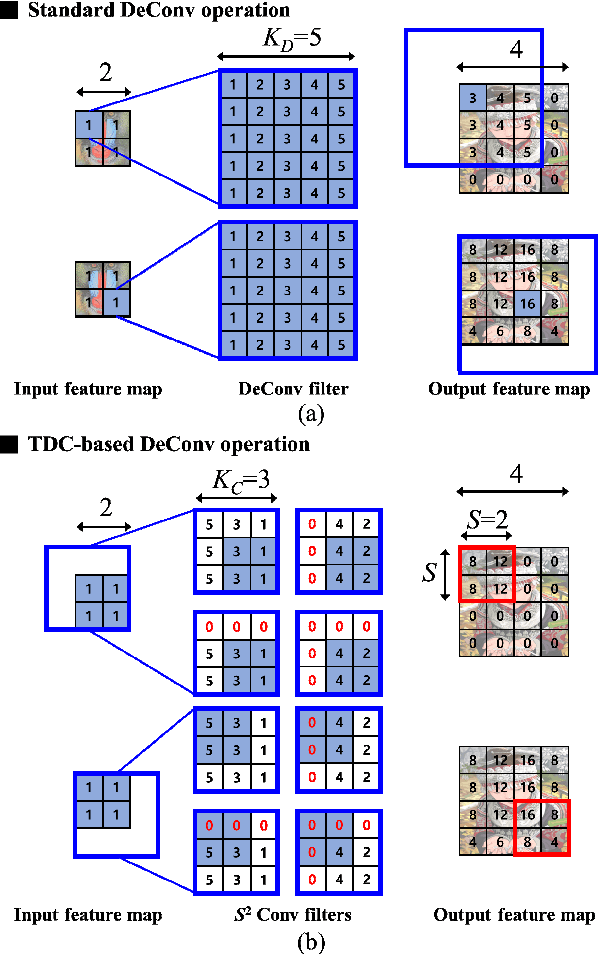
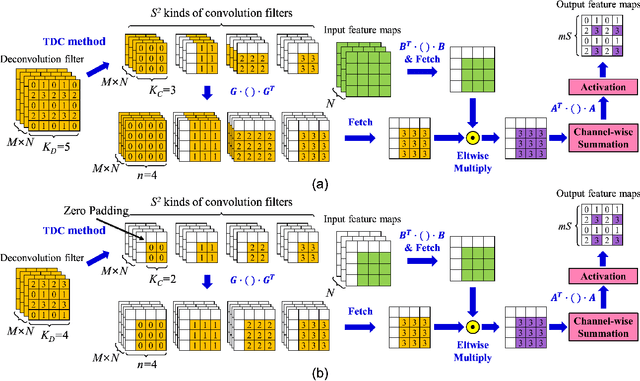
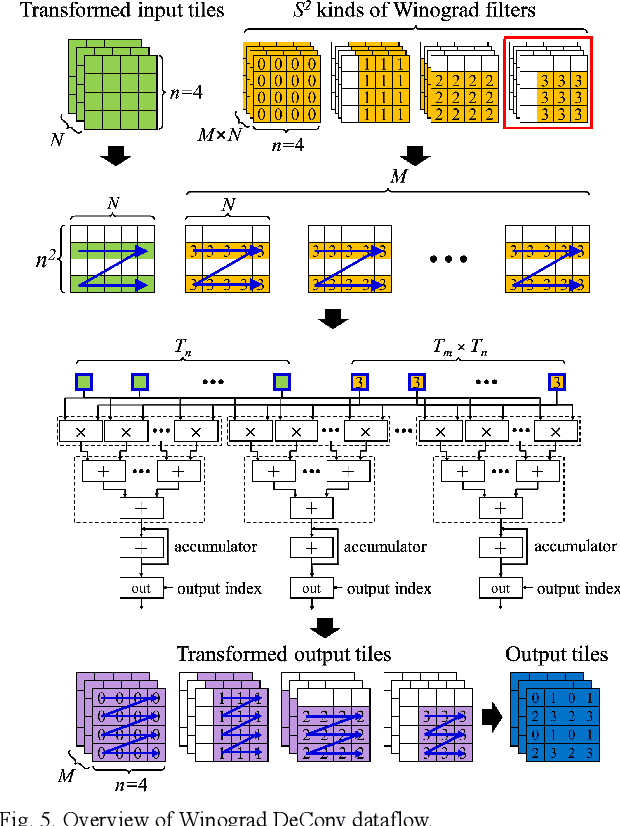
Generative adversarial networks (GANs) have shown excellent performance in image and speech applications. GANs create impressive data primarily through a new type of operator called deconvolution (DeConv) or transposed convolution (Conv). To implement the DeConv layer in hardware, the state-of-the-art accelerator reduces the high computational complexity via the DeConv-to-Conv conversion and achieves the same results. However, there is a problem that the number of filters increases due to this conversion. Recently, Winograd minimal filtering has been recognized as an effective solution to improve the arithmetic complexity and resource efficiency of the Conv layer. In this paper, we propose an efficient Winograd DeConv accelerator that combines these two orthogonal approaches on FPGAs. Firstly, we introduce a new class of fast algorithm for DeConv layers using Winograd minimal filtering. Since there are regular sparse patterns in Winograd filters, we further amortize the computational complexity by skipping zero weights. Secondly, we propose a new dataflow to prevent resource underutilization by reorganizing the filter layout in the Winograd domain. Finally, we propose an efficient architecture for implementing Winograd DeConv by designing the line buffer and exploring the design space. Experimental results on various GANs show that our accelerator achieves up to 1.78x~8.38x speedup over the state-of-the-art DeConv accelerators.