 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Accelerator Design Methodology for Deformable Convolutional Networks
Paper and Code
Jun 13, 2020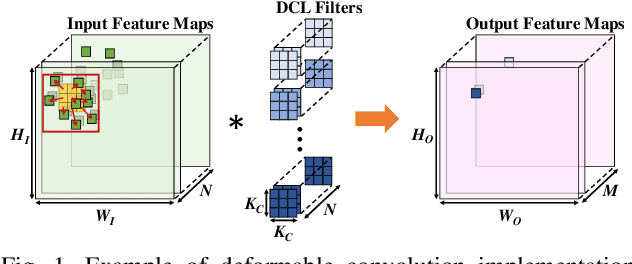
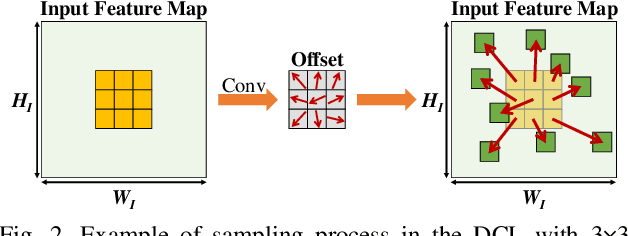
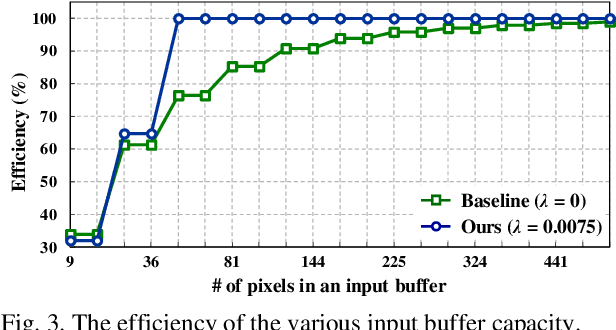
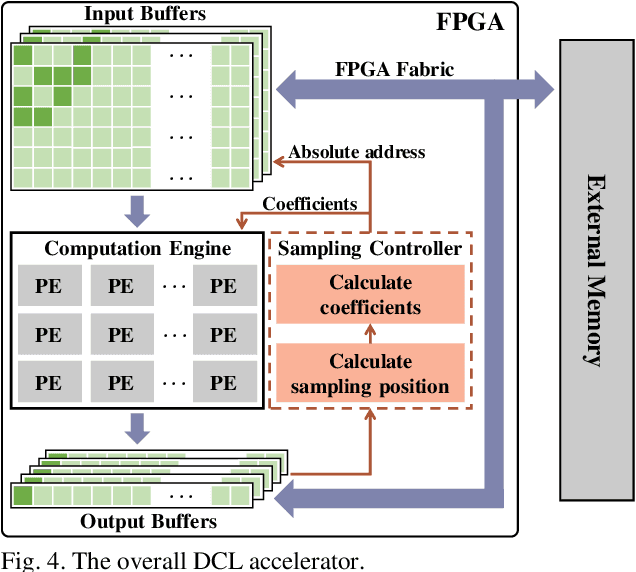
Deformable convolutional networks have demonstrated outstanding performance in object recognition tasks with an effective feature extraction. Unlike standard convolution, the deformable convolution decides the receptive field size using dynamically generated offsets, which leads to an irregular memory access. Especially, the memory access pattern varies both spatially and temporally, making static optimization ineffective. Thus, a naive implementation would lead to an excessive memory footprint. In this paper, we present a novel approach to accelerate deformable convolution on FPGA. First, we propose a novel training method to reduce the size of the receptive field in the deformable convolutional layer without compromising accuracy. By optimizing the receptive field, we can compress the maximum size of the receptive field by 12.6 times. Second, we propose an efficient systolic architecture to maximize its efficiency. We then implement our design on FPGA to support the optimized dataflow. Experimental results show that our accelerator achieves up to 17.25 times speedup over the state-of-the-art accelerator.