 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Accelerator Design Methodology for Deformable Convolutional Networks
Jun 13, 2020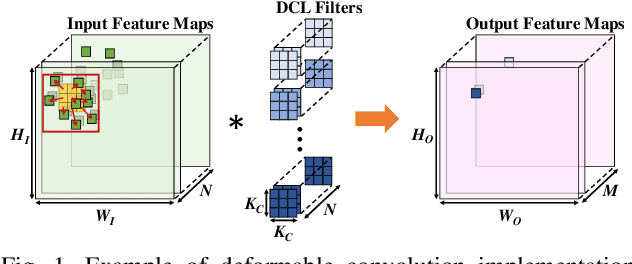
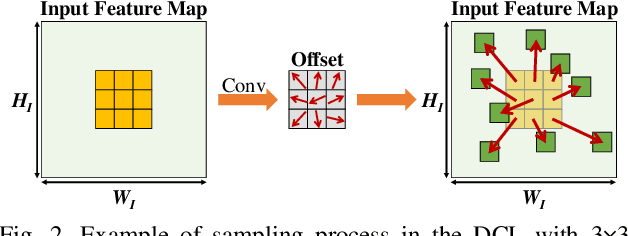
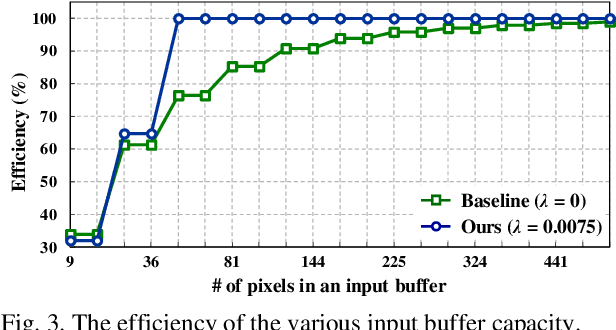
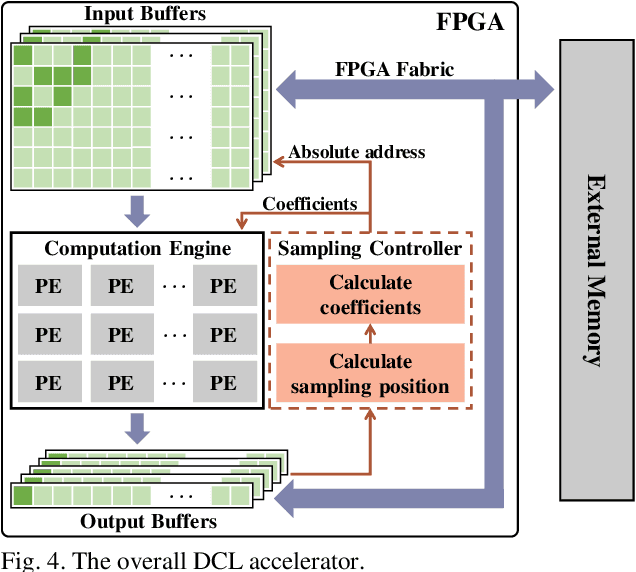
Deformable convolutional networks have demonstrated outstanding performance in object recognition tasks with an effective feature extraction. Unlike standard convolution, the deformable convolution decides the receptive field size using dynamically generated offsets, which leads to an irregular memory access. Especially, the memory access pattern varies both spatially and temporally, making static optimization ineffective. Thus, a naive implementation would lead to an excessive memory footprint. In this paper, we present a novel approach to accelerate deformable convolution on FPGA. First, we propose a novel training method to reduce the size of the receptive field in the deformable convolutional layer without compromising accuracy. By optimizing the receptive field, we can compress the maximum size of the receptive field by 12.6 times. Second, we propose an efficient systolic architecture to maximize its efficiency. We then implement our design on FPGA to support the optimized dataflow. Experimental results show that our accelerator achieves up to 17.25 times speedup over the state-of-the-art accelerator.
Towards Design Methodology of Efficient Fast Algorithms for Accelerating Generative Adversarial Networks on FPGAs
Nov 15, 2019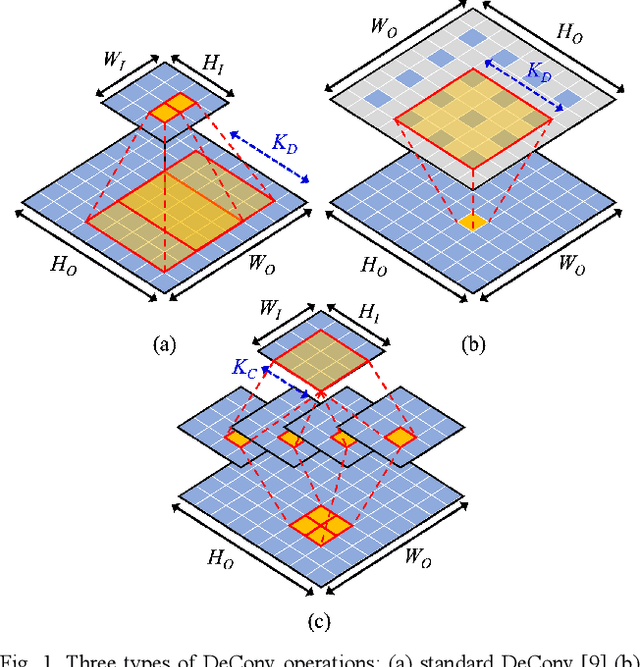
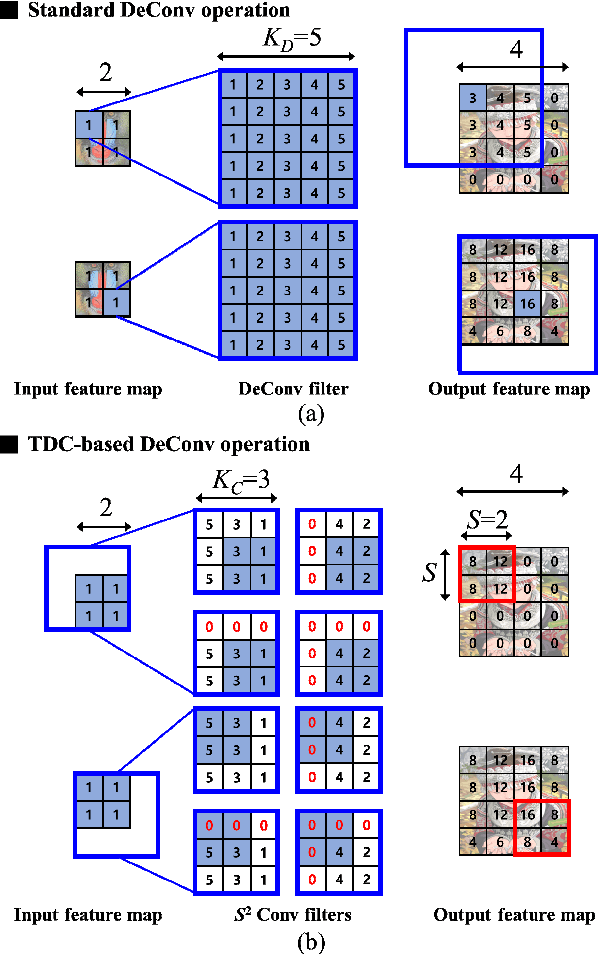
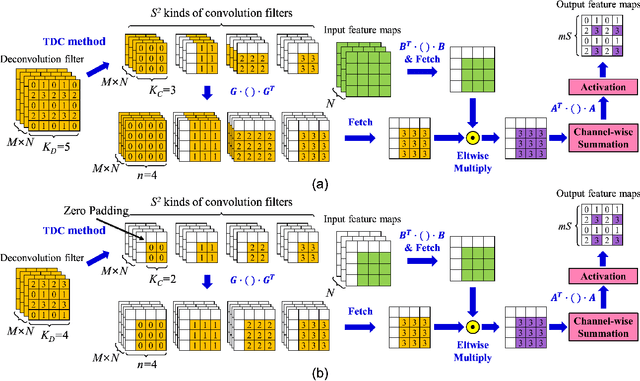
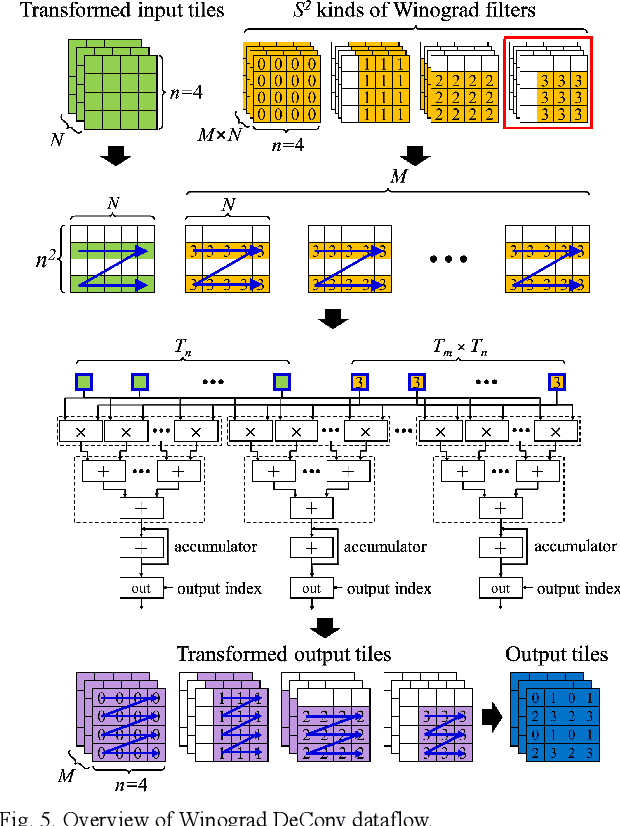
Generative adversarial networks (GANs) have shown excellent performance in image and speech applications. GANs create impressive data primarily through a new type of operator called deconvolution (DeConv) or transposed convolution (Conv). To implement the DeConv layer in hardware, the state-of-the-art accelerator reduces the high computational complexity via the DeConv-to-Conv conversion and achieves the same results. However, there is a problem that the number of filters increases due to this conversion. Recently, Winograd minimal filtering has been recognized as an effective solution to improve the arithmetic complexity and resource efficiency of the Conv layer. In this paper, we propose an efficient Winograd DeConv accelerator that combines these two orthogonal approaches on FPGAs. Firstly, we introduce a new class of fast algorithm for DeConv layers using Winograd minimal filtering. Since there are regular sparse patterns in Winograd filters, we further amortize the computational complexity by skipping zero weights. Secondly, we propose a new dataflow to prevent resource underutilization by reorganizing the filter layout in the Winograd domain. Finally, we propose an efficient architecture for implementing Winograd DeConv by designing the line buffer and exploring the design space. Experimental results on various GANs show that our accelerator achieves up to 1.78x~8.38x speedup over the state-of-the-art DeConv accelerators.