 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThUnderVolt: Enabling Aggressive Voltage Underscaling and Timing Error Resilience for Energy Efficient Deep Neural Network Accelerators
Mar 13, 2018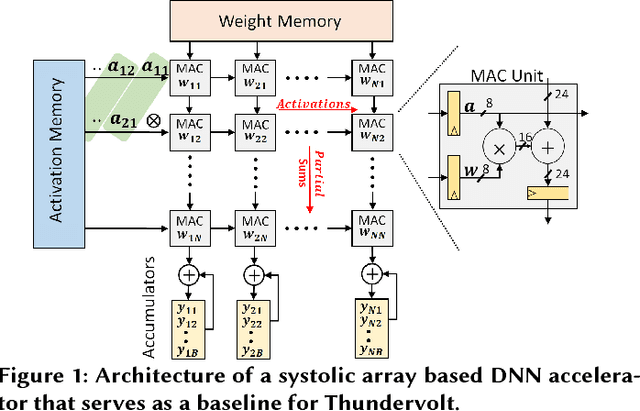
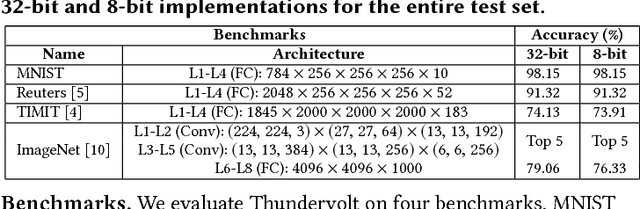
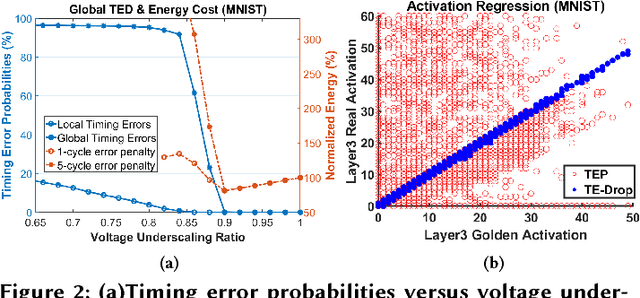
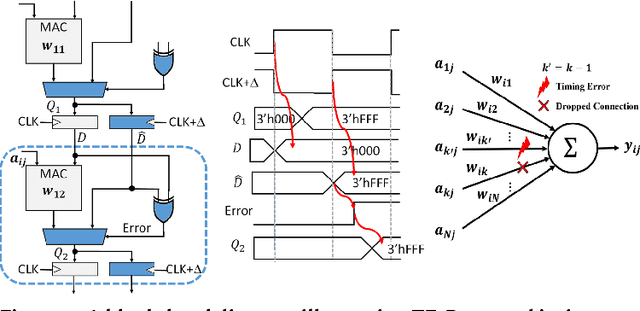
Hardware accelerators are being increasingly deployed to boost the performance and energy efficiency of deep neural network (DNN) inference. In this paper we propose Thundervolt, a new framework that enables aggressive voltage underscaling of high-performance DNN accelerators without compromising classification accuracy even in the presence of high timing error rates. Using post-synthesis timing simulations of a DNN accelerator modeled on the Google TPU, we show that Thundervolt enables between 34%-57% energy savings on state-of-the-art speech and image recognition benchmarks with less than 1% loss in classification accuracy and no performance loss. Further, we show that Thundervolt is synergistic with and can further increase the energy efficiency of commonly used run-time DNN pruning techniques like Zero-Skip.