 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-distribution aware Self-training in an Open World Setting
Paper and Code
Dec 21, 2020
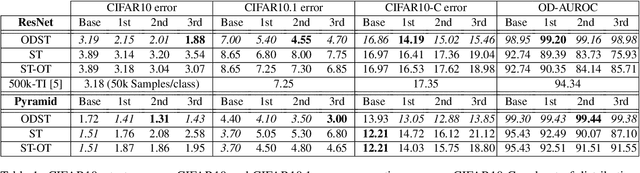
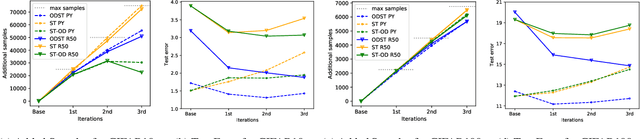
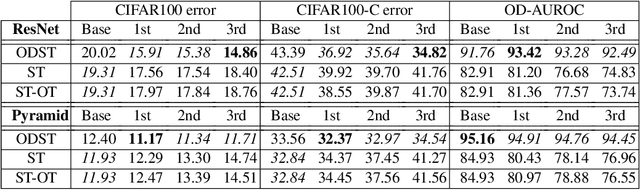
Deep Learning heavily depends on large labeled datasets which limits further improvements. While unlabeled data is available in large amounts, in particular in image recognition, it does not fulfill the closed world assumption of semi-supervised learning that all unlabeled data are task-related. The goal of this paper is to leverage unlabeled data in an open world setting to further improve prediction performance. For this purpose, we introduce out-distribution aware self-training, which includes a careful sample selection strategy based on the confidence of the classifier. While normal self-training deteriorates prediction performance, our iterative scheme improves using up to 15 times the amount of originally labeled data. Moreover, our classifiers are by design out-distribution aware and can thus distinguish task-related inputs from unrelated ones.