 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven Model Reduction using WeldNet: Windowed Encoders for Learning Dynamics
Dec 11, 2025Many problems in science and engineering involve time-dependent, high dimensional datasets arising from complex physical processes, which are costly to simulate. In this work, we propose WeldNet: Windowed Encoders for Learning Dynamics, a data-driven nonlinear model reduction framework to build a low-dimensional surrogate model for complex evolution systems. Given time-dependent training data, we split the time domain into multiple overlapping windows, within which nonlinear dimension reduction is performed by auto-encoders to capture latent codes. Once a low-dimensional representation of the data is learned, a propagator network is trained to capture the evolution of the latent codes in each window, and a transcoder is trained to connect the latent codes between adjacent windows. The proposed windowed decomposition significantly simplifies propagator training by breaking long-horizon dynamics into multiple short, manageable segments, while the transcoders ensure consistency across windows. In addition to the algorithmic framework, we develop a mathematical theory establishing the representation power of WeldNet under the manifold hypothesis, justifying the success of nonlinear model reduction via deep autoencoder-based architectures. Our numerical experiments on various differential equations indicate that WeldNet can capture nonlinear latent structures and their underlying dynamics, outperforming both traditional projection-based approaches and recently developed nonlinear model reduction methods.
Generalization Error Guaranteed Auto-Encoder-Based Nonlinear Model Reduction for Operator Learning
Jan 19, 2024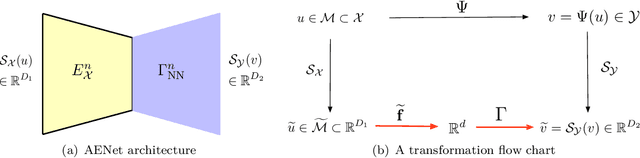
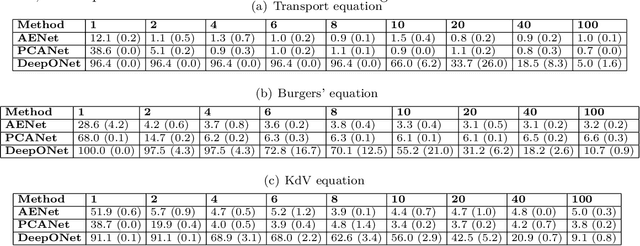
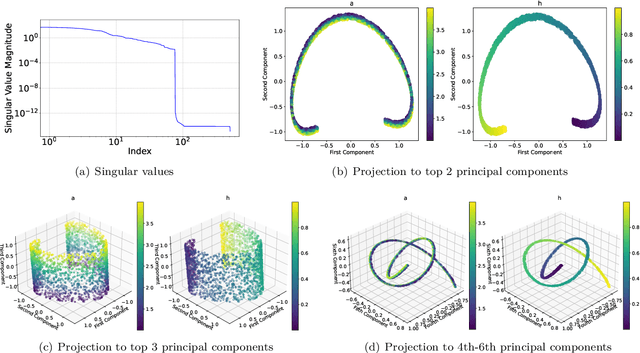
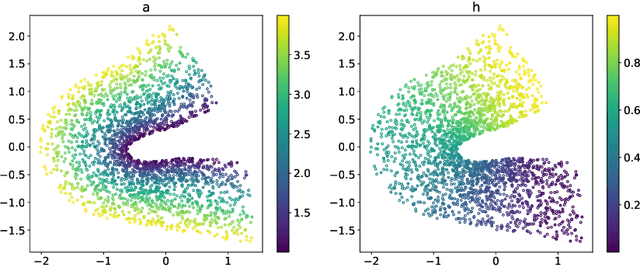
Many physical processes in science and engineering are naturally represented by operators between infinite-dimensional function spaces. The problem of operator learning, in this context, seeks to extract these physical processes from empirical data, which is challenging due to the infinite or high dimensionality of data. An integral component in addressing this challenge is model reduction, which reduces both the data dimensionality and problem size. In this paper, we utilize low-dimensional nonlinear structures in model reduction by investigating Auto-Encoder-based Neural Network (AENet). AENet first learns the latent variables of the input data and then learns the transformation from these latent variables to corresponding output data. Our numerical experiments validate the ability of AENet to accurately learn the solution operator of nonlinear partial differential equations. Furthermore, we establish a mathematical and statistical estimation theory that analyzes the generalization error of AENet. Our theoretical framework shows that the sample complexity of training AENet is intricately tied to the intrinsic dimension of the modeled process, while also demonstrating the remarkable resilience of AENet to noise.
On Deep Generative Models for Approximation and Estimation of Distributions on Manifolds
Feb 25, 2023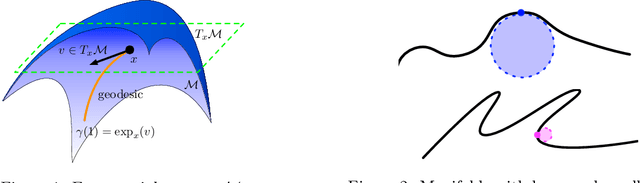
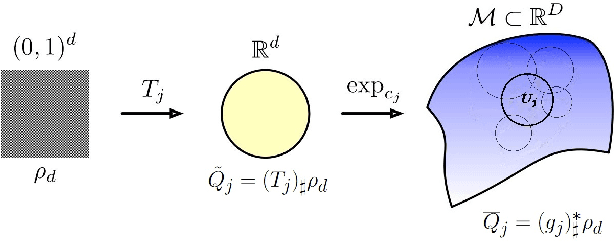
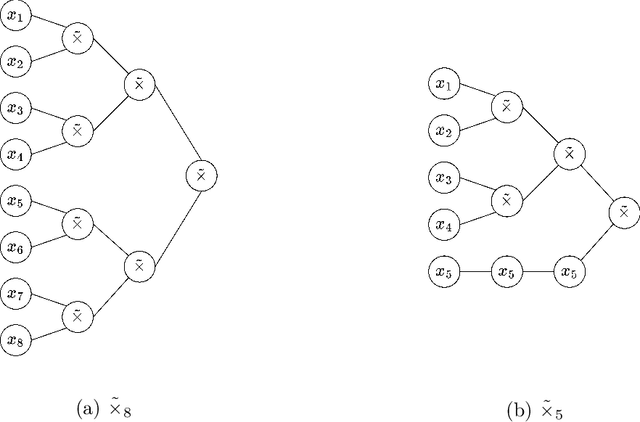
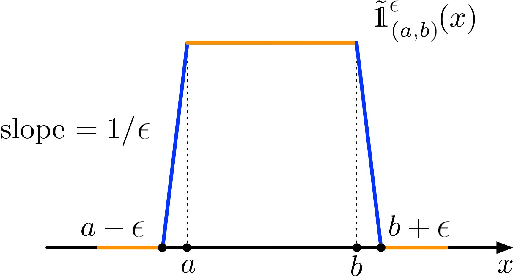
Generative networks have experienced great empirical successes in distribution learning. Many existing experiments have demonstrated that generative networks can generate high-dimensional complex data from a low-dimensional easy-to-sample distribution. However, this phenomenon can not be justified by existing theories. The widely held manifold hypothesis speculates that real-world data sets, such as natural images and signals, exhibit low-dimensional geometric structures. In this paper, we take such low-dimensional data structures into consideration by assuming that data distributions are supported on a low-dimensional manifold. We prove statistical guarantees of generative networks under the Wasserstein-1 loss. We show that the Wasserstein-1 loss converges to zero at a fast rate depending on the intrinsic dimension instead of the ambient data dimension. Our theory leverages the low-dimensional geometric structures in data sets and justifies the practical power of generative networks. We require no smoothness assumptions on the data distribution which is desirable in practice.