 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-training Quantization for Neural Networks with Provable Guarantees
Paper and Code

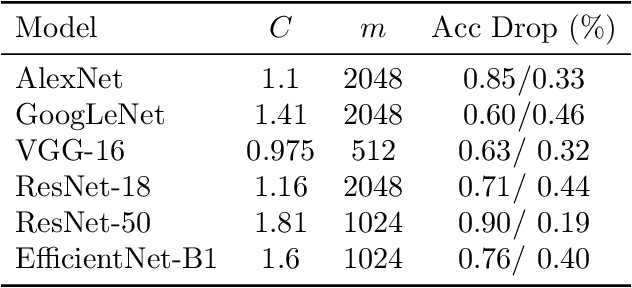

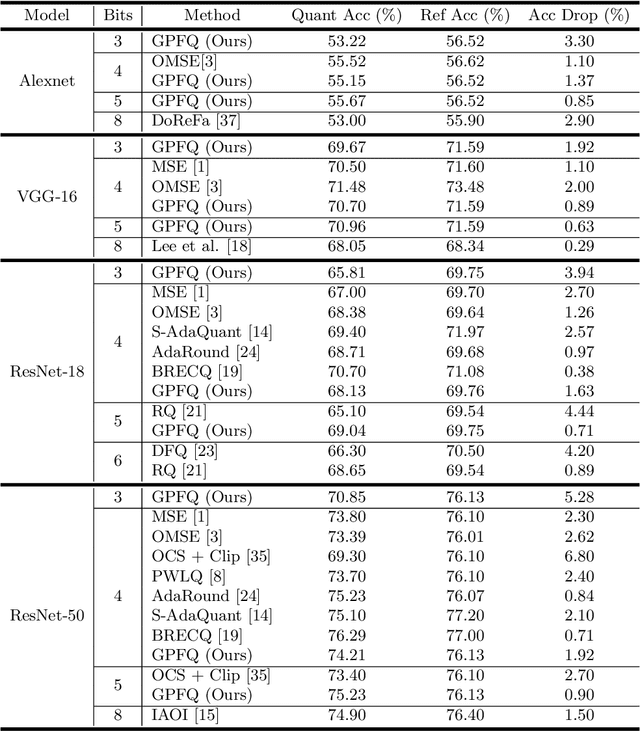
While neural networks have been remarkably successful in a wide array of applications, implementing them in resource-constrained hardware remains an area of intense research. By replacing the weights of a neural network with quantized (e.g., 4-bit, or binary) counterparts, massive savings in computation cost, memory, and power consumption are attained. We modify a post-training neural-network quantization method, GPFQ, that is based on a greedy path-following mechanism, and rigorously analyze its error. We prove that for quantizing a single-layer network, the relative square error essentially decays linearly in the number of weights -- i.e., level of over-parametrization. Our result holds across a range of input distributions and for both fully-connected and convolutional architectures. To empirically evaluate the method, we quantize several common architectures with few bits per weight, and test them on ImageNet, showing only minor loss of accuracy. We also demonstrate that standard modifications, such as bias correction and mixed precision quantization, further improve accuracy.