 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLAG: Finding Line Anomalies (in code) with Generative AI
Paper and Code
Jun 22, 2023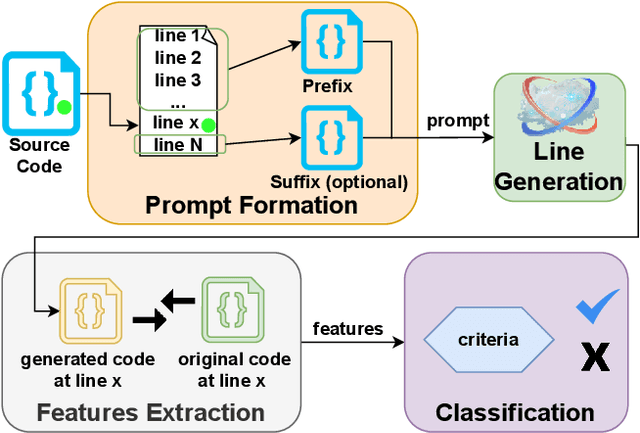



Code contains security and functional bugs. The process of identifying and localizing them is difficult and relies on human labor. In this work, we present a novel approach (FLAG) to assist human debuggers. FLAG is based on the lexical capabilities of generative AI, specifically, Large Language Models (LLMs). Here, we input a code file then extract and regenerate each line within that file for self-comparison. By comparing the original code with an LLM-generated alternative, we can flag notable differences as anomalies for further inspection, with features such as distance from comments and LLM confidence also aiding this classification. This reduces the inspection search space for the designer. Unlike other automated approaches in this area, FLAG is language-agnostic, can work on incomplete (and even non-compiling) code and requires no creation of security properties, functional tests or definition of rules. In this work, we explore the features that help LLMs in this classification and evaluate the performance of FLAG on known bugs. We use 121 benchmarks across C, Python and Verilog; with each benchmark containing a known security or functional weakness. We conduct the experiments using two state of the art LLMs in OpenAI's code-davinci-002 and gpt-3.5-turbo, but our approach may be used by other models. FLAG can identify 101 of the defects and helps reduce the search space to 12-17% of source code.