 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Preserving Cross-Style Visual Reasoning for Robust Multi-Modal Understanding in Large Vision-Language Models
Oct 26, 2025



The "style trap" poses a significant challenge for Large Vision-Language Models (LVLMs), hindering robust semantic understanding across diverse visual styles, especially in in-context learning (ICL). Existing methods often fail to effectively decouple style from content, hindering generalization. To address this, we propose the Semantic-Preserving Cross-Style Visual Reasoner (SP-CSVR), a novel framework for stable semantic understanding and adaptive cross-style visual reasoning. SP-CSVR integrates a Cross-Style Feature Encoder (CSFE) for style-content disentanglement, a Semantic-Aligned In-Context Decoder (SAICD) for efficient few-shot style adaptation, and an Adaptive Semantic Consistency Module (ASCM) employing multi-task contrastive learning to enforce cross-style semantic invariance. Extensive experiments on a challenging multi-style dataset demonstrate SP-CSVR's state-of-the-art performance across visual captioning, visual question answering, and in-context style adaptation. Comprehensive evaluations, including ablation studies and generalization analysis, confirm SP-CSVR's efficacy in enhancing robustness, generalization, and efficiency across diverse visual styles.
High-Fidelity Pseudo-label Generation by Large Language Models for Training Robust Radiology Report Classifiers
May 03, 2025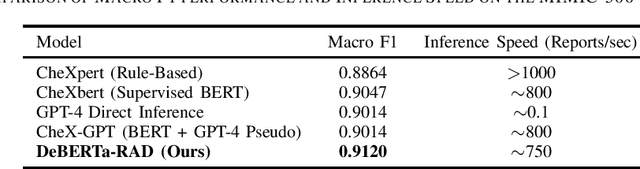


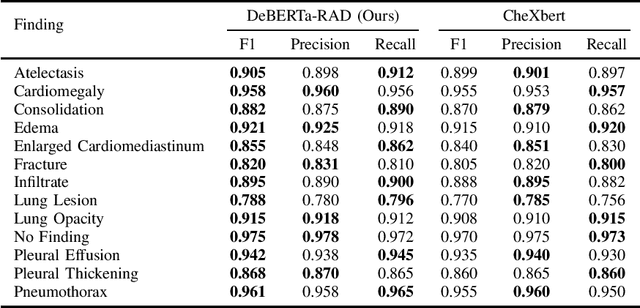
Automated labeling of chest X-ray reports is essential for enabling downstream tasks such as training image-based diagnostic models, population health studies, and clinical decision support. However, the high variability, complexity, and prevalence of negation and uncertainty in these free-text reports pose significant challenges for traditional Natural Language Processing methods. While large language models (LLMs) demonstrate strong text understanding, their direct application for large-scale, efficient labeling is limited by computational cost and speed. This paper introduces DeBERTa-RAD, a novel two-stage framework that combines the power of state-of-the-art LLM pseudo-labeling with efficient DeBERTa-based knowledge distillation for accurate and fast chest X-ray report labeling. We leverage an advanced LLM to generate high-quality pseudo-labels, including certainty statuses, for a large corpus of reports. Subsequently, a DeBERTa-Base model is trained on this pseudo-labeled data using a tailored knowledge distillation strategy. Evaluated on the expert-annotated MIMIC-500 benchmark, DeBERTa-RAD achieves a state-of-the-art Macro F1 score of 0.9120, significantly outperforming established rule-based systems, fine-tuned transformer models, and direct LLM inference, while maintaining a practical inference speed suitable for high-throughput applications. Our analysis shows particular strength in handling uncertain findings. This work demonstrates a promising path to overcome data annotation bottlenecks and achieve high-performance medical text processing through the strategic combination of LLM capabilities and efficient student models trained via distillation.
Optimizing Vision-Language Interactions Through Decoder-Only Models
Dec 14, 2024Vision-Language Models (VLMs) have emerged as key enablers for multimodal tasks, but their reliance on separate visual encoders introduces challenges in efficiency, scalability, and modality alignment. To address these limitations, we propose MUDAIF (Multimodal Unified Decoder with Adaptive Input Fusion), a decoder-only vision-language model that seamlessly integrates visual and textual inputs through a novel Vision-Token Adapter (VTA) and adaptive co-attention mechanism. By eliminating the need for a visual encoder, MUDAIF achieves enhanced efficiency, flexibility, and cross-modal understanding. Trained on a large-scale dataset of 45M image-text pairs, MUDAIF consistently outperforms state-of-the-art methods across multiple benchmarks, including VQA, image captioning, and multimodal reasoning tasks. Extensive analyses and human evaluations demonstrate MUDAIF's robustness, generalization capabilities, and practical usability, establishing it as a new standard in encoder-free vision-language models.
An Application-Agnostic Automatic Target Recognition System Using Vision Language Models
Nov 05, 2024

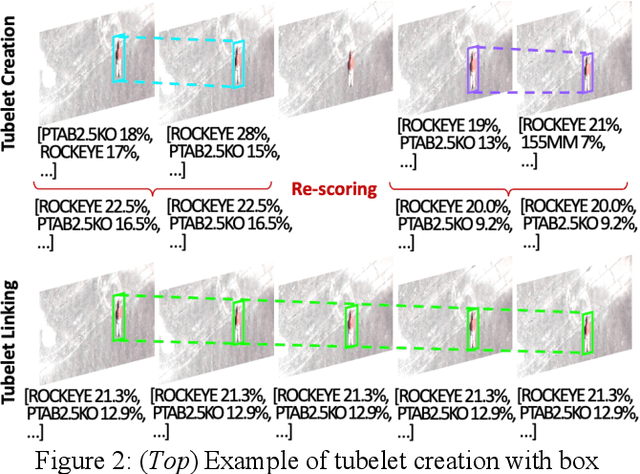
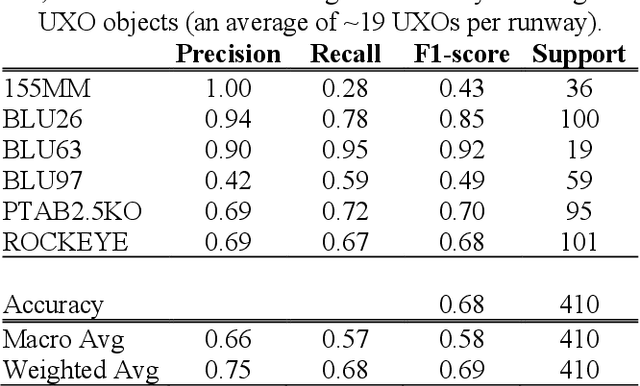
We present a novel Automatic Target Recognition (ATR) system using open-vocabulary object detection and classification models. A primary advantage of this approach is that target classes can be defined just before runtime by a non-technical end user, using either a few natural language text descriptions of the target, or a few image exemplars, or both. Nuances in the desired targets can be expressed in natural language, which is useful for unique targets with little or no training data. We also implemented a novel combination of several techniques to improve performance, such as leveraging the additional information in the sequence of overlapping frames to perform tubelet identification (i.e., sequential bounding box matching), bounding box re-scoring, and tubelet linking. Additionally, we developed a technique to visualize the aggregate output of many overlapping frames as a mosaic of the area scanned during the aerial surveillance or reconnaissance, and a kernel density estimate (or heatmap) of the detected targets. We initially applied this ATR system to the use case of detecting and clearing unexploded ordinance on airfield runways and we are currently extending our research to other real-world applications.
Leveraging Language Models for Emotion and Behavior Analysis in Education
Aug 13, 2024The analysis of students' emotions and behaviors is crucial for enhancing learning outcomes and personalizing educational experiences. Traditional methods often rely on intrusive visual and physiological data collection, posing privacy concerns and scalability issues. This paper proposes a novel method leveraging large language models (LLMs) and prompt engineering to analyze textual data from students. Our approach utilizes tailored prompts to guide LLMs in detecting emotional and engagement states, providing a non-intrusive and scalable solution. We conducted experiments using Qwen, ChatGPT, Claude2, and GPT-4, comparing our method against baseline models and chain-of-thought (CoT) prompting. Results demonstrate that our method significantly outperforms the baselines in both accuracy and contextual understanding. This study highlights the potential of LLMs combined with prompt engineering to offer practical and effective tools for educational emotion and behavior analysis.
FOLIO: Natural Language Reasoning with First-Order Logic
Sep 02, 2022
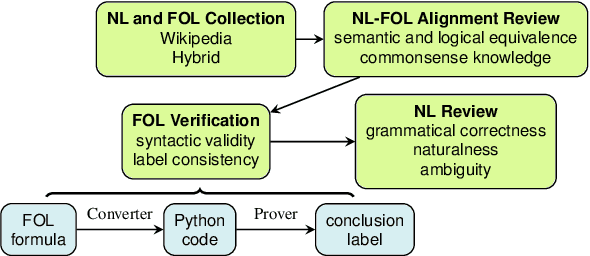
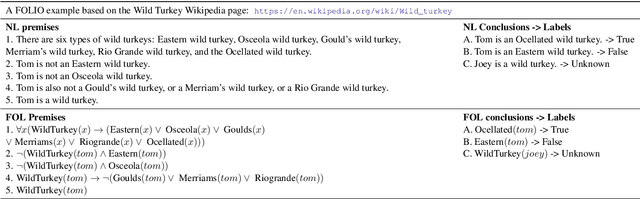
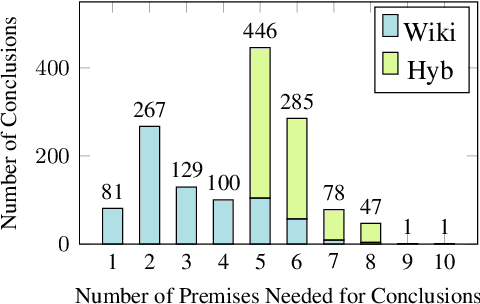
We present FOLIO, a human-annotated, open-domain, and logically complex and diverse dataset for reasoning in natural language (NL), equipped with first order logic (FOL) annotations. FOLIO consists of 1,435 examples (unique conclusions), each paired with one of 487 sets of premises which serve as rules to be used to deductively reason for the validity of each conclusion. The logical correctness of premises and conclusions is ensured by their parallel FOL annotations, which are automatically verified by our FOL inference engine. In addition to the main NL reasoning task, NL-FOL pairs in FOLIO automatically constitute a new NL-FOL translation dataset using FOL as the logical form. Our experiments on FOLIO systematically evaluate the FOL reasoning ability of supervised fine-tuning on medium-sized language models (BERT, RoBERTa) and few-shot prompting on large language models (GPT-NeoX, OPT, GPT-3, Codex). For NL-FOL translation, we experiment with GPT-3 and Codex. Our results show that one of the most capable Large Language Model (LLM) publicly available, GPT-3 davinci, achieves only slightly better than random results with few-shot prompting on a subset of FOLIO, and the model is especially bad at predicting the correct truth values for False and Unknown conclusions. Our dataset and code are available at https://github.com/Yale-LILY/FOLIO.