 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne for All and All for One: GNN-based Control-Flow Attestation for Embedded Devices
Mar 12, 2024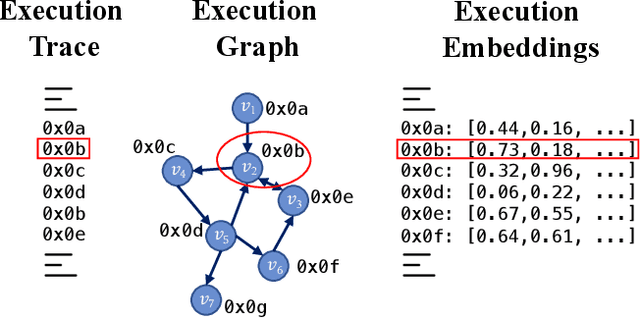



Control-Flow Attestation (CFA) is a security service that allows an entity (verifier) to verify the integrity of code execution on a remote computer system (prover). Existing CFA schemes suffer from impractical assumptions, such as requiring access to the prover's internal state (e.g., memory or code), the complete Control-Flow Graph (CFG) of the prover's software, large sets of measurements, or tailor-made hardware. Moreover, current CFA schemes are inadequate for attesting embedded systems due to their high computational overhead and resource usage. In this paper, we overcome the limitations of existing CFA schemes for embedded devices by introducing RAGE, a novel, lightweight CFA approach with minimal requirements. RAGE can detect Code Reuse Attacks (CRA), including control- and non-control-data attacks. It efficiently extracts features from one execution trace and leverages Unsupervised Graph Neural Networks (GNNs) to identify deviations from benign executions. The core intuition behind RAGE is to exploit the correspondence between execution trace, execution graph, and execution embeddings to eliminate the unrealistic requirement of having access to a complete CFG. We evaluate RAGE on embedded benchmarks and demonstrate that (i) it detects 40 real-world attacks on embedded software; (ii) Further, we stress our scheme with synthetic return-oriented programming (ROP) and data-oriented programming (DOP) attacks on the real-world embedded software benchmark Embench, achieving 98.03% (ROP) and 91.01% (DOP) F1-Score while maintaining a low False Positive Rate of 3.19%; (iii) Additionally, we evaluate RAGE on OpenSSL, used by millions of devices and achieve 97.49% and 84.42% F1-Score for ROP and DOP attack detection, with an FPR of 5.47%.
FakeWake: Understanding and Mitigating Fake Wake-up Words of Voice Assistants
Sep 21, 2021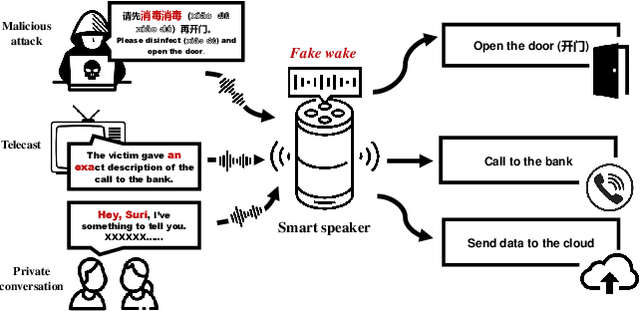
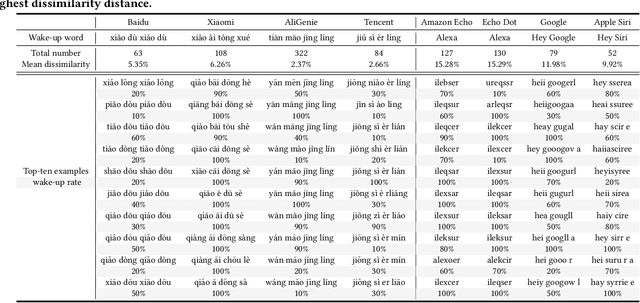
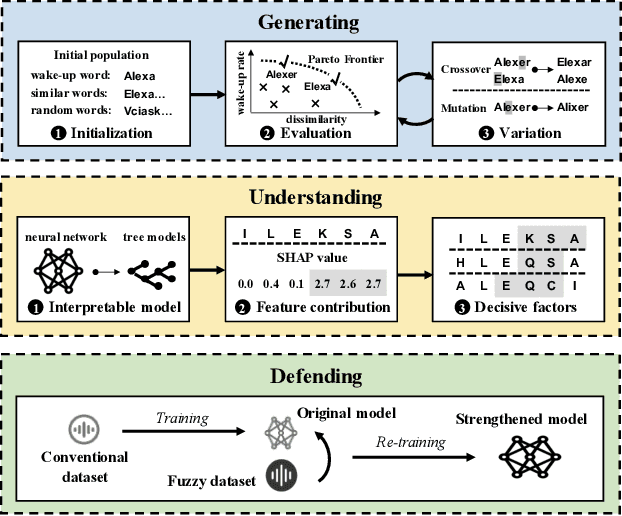

In the area of Internet of Things (IoT) voice assistants have become an important interface to operate smart speakers, smartphones, and even automobiles. To save power and protect user privacy, voice assistants send commands to the cloud only if a small set of pre-registered wake-up words are detected. However, voice assistants are shown to be vulnerable to the FakeWake phenomena, whereby they are inadvertently triggered by innocent-sounding fuzzy words. In this paper, we present a systematic investigation of the FakeWake phenomena from three aspects. To start with, we design the first fuzzy word generator to automatically and efficiently produce fuzzy words instead of searching through a swarm of audio materials. We manage to generate 965 fuzzy words covering 8 most popular English and Chinese smart speakers. To explain the causes underlying the FakeWake phenomena, we construct an interpretable tree-based decision model, which reveals phonetic features that contribute to false acceptance of fuzzy words by wake-up word detectors. Finally, we propose remedies to mitigate the effect of FakeWake. The results show that the strengthened models are not only resilient to fuzzy words but also achieve better overall performance on original training datasets.