 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWild Networks: Exposure of 5G Network Infrastructures to Adversarial Examples
Jul 04, 2022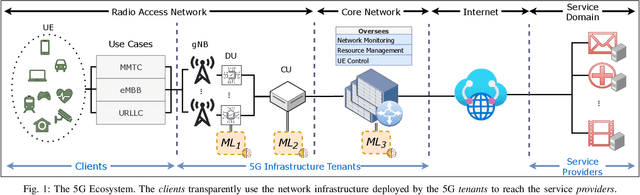
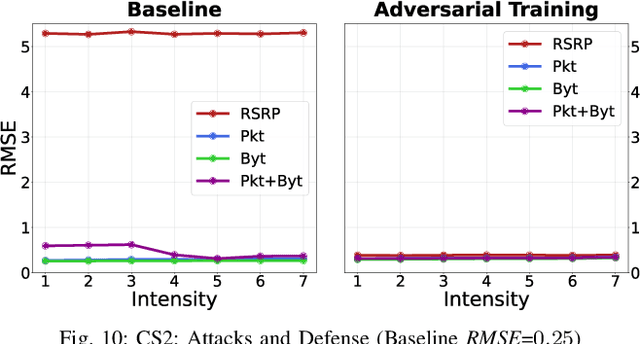
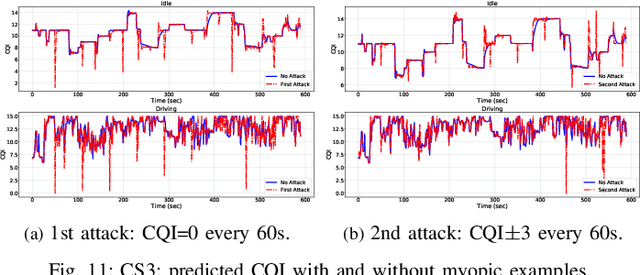
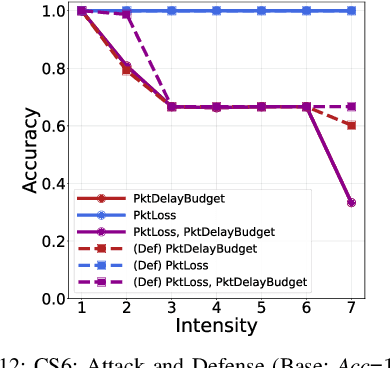
Fifth Generation (5G) networks must support billions of heterogeneous devices while guaranteeing optimal Quality of Service (QoS). Such requirements are impossible to meet with human effort alone, and Machine Learning (ML) represents a core asset in 5G. ML, however, is known to be vulnerable to adversarial examples; moreover, as our paper will show, the 5G context is exposed to a yet another type of adversarial ML attacks that cannot be formalized with existing threat models. Proactive assessment of such risks is also challenging due to the lack of ML-powered 5G equipment available for adversarial ML research. To tackle these problems, we propose a novel adversarial ML threat model that is particularly suited to 5G scenarios, and is agnostic to the precise function solved by ML. In contrast to existing ML threat models, our attacks do not require any compromise of the target 5G system while still being viable due to the QoS guarantees and the open nature of 5G networks. Furthermore, we propose an original framework for realistic ML security assessments based on public data. We proactively evaluate our threat model on 6 applications of ML envisioned in 5G. Our attacks affect both the training and the inference stages, can degrade the performance of state-of-the-art ML systems, and have a lower entry barrier than previous attacks.
SoK: The Impact of Unlabelled Data in Cyberthreat Detection
May 18, 2022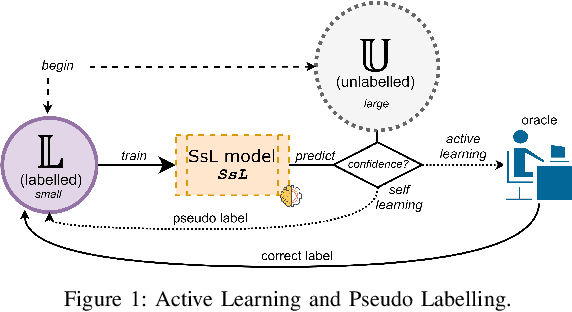
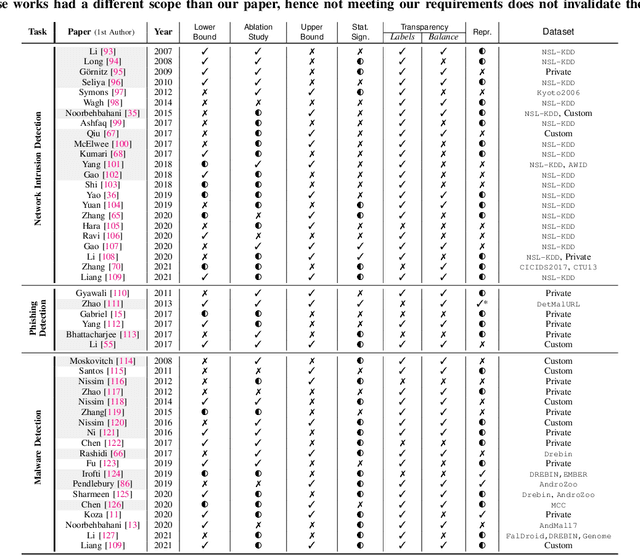
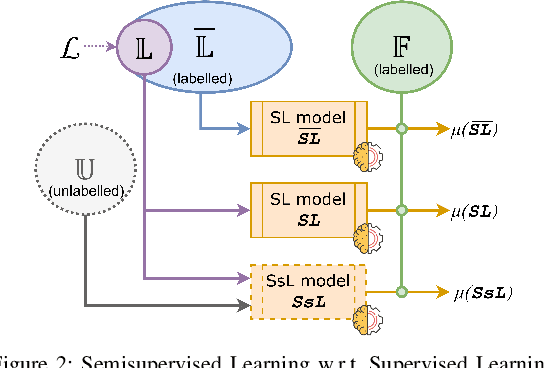
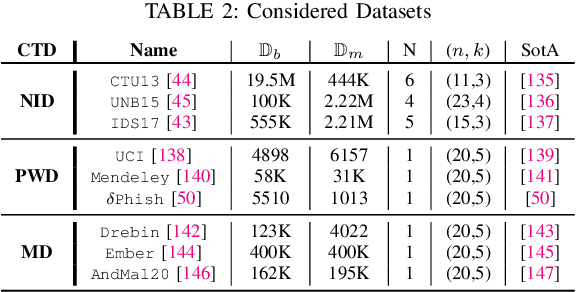
Machine learning (ML) has become an important paradigm for cyberthreat detection (CTD) in the recent years. A substantial research effort has been invested in the development of specialized algorithms for CTD tasks. From the operational perspective, however, the progress of ML-based CTD is hindered by the difficulty in obtaining the large sets of labelled data to train ML detectors. A potential solution to this problem are semisupervised learning (SsL) methods, which combine small labelled datasets with large amounts of unlabelled data. This paper is aimed at systematization of existing work on SsL for CTD and, in particular, on understanding the utility of unlabelled data in such systems. To this end, we analyze the cost of labelling in various CTD tasks and develop a formal cost model for SsL in this context. Building on this foundation, we formalize a set of requirements for evaluation of SsL methods, which elucidates the contribution of unlabelled data. We review the state-of-the-art and observe that no previous work meets such requirements. To address this problem, we propose a framework for assessing the benefits of unlabelled data in SsL. We showcase an application of this framework by performing the first benchmark evaluation that highlights the tradeoffs of 9 existing SsL methods on 9 public datasets. Our findings verify that, in some cases, unlabelled data provides a small, but statistically significant, performance gain. This paper highlights that SsL in CTD has a lot of room for improvement, which should stimulate future research in this field.