 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHexaCoder: Secure Code Generation via Oracle-Guided Synthetic Training Data
Paper and Code
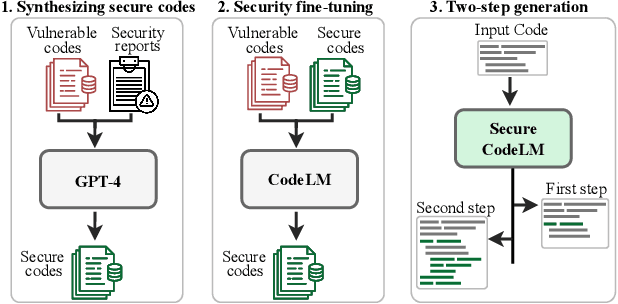



Large language models (LLMs) have shown great potential for automatic code generation and form the basis for various tools such as GitHub Copilot. However, recent studies highlight that many LLM-generated code contains serious security vulnerabilities. While previous work tries to address this by training models that generate secure code, these attempts remain constrained by limited access to training data and labor-intensive data preparation. In this paper, we introduce HexaCoder, a novel approach to enhance the ability of LLMs to generate secure codes by automatically synthesizing secure codes, which reduces the effort of finding suitable training data. HexaCoder comprises two key components: an oracle-guided data synthesis pipeline and a two-step process for secure code generation. The data synthesis pipeline generates pairs of vulnerable and fixed codes for specific Common Weakness Enumeration (CWE) types by utilizing a state-of-the-art LLM for repairing vulnerable code. A security oracle identifies vulnerabilities, and a state-of-the-art LLM repairs them by extending and/or editing the codes, creating data pairs for fine-tuning using the Low-Rank Adaptation (LoRA) method. Each example of our fine-tuning dataset includes the necessary security-related libraries and code that form the basis of our novel two-step generation approach. This allows the model to integrate security-relevant libraries before generating the main code, significantly reducing the number of generated vulnerable codes by up to 85% compared to the baseline methods. We perform extensive evaluations on three different benchmarks for four LLMs, demonstrating that HexaCoder not only improves the security of the generated code but also maintains a high level of functional correctness.