 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-GBDT: Frugal Differentially Private Gradient Boosting Decision Trees
Sep 28, 2023Privacy-preserving learning of gradient boosting decision trees (GBDT) has the potential for strong utility-privacy tradeoffs for tabular data, such as census data or medical meta data: classical GBDT learners can extract non-linear patterns from small sized datasets. The state-of-the-art notion for provable privacy-properties is differential privacy, which requires that the impact of single data points is limited and deniable. We introduce a novel differentially private GBDT learner and utilize four main techniques to improve the utility-privacy tradeoff. (1) We use an improved noise scaling approach with tighter accounting of privacy leakage of a decision tree leaf compared to prior work, resulting in noise that in expectation scales with $O(1/n)$, for $n$ data points. (2) We integrate individual R\'enyi filters to our method to learn from data points that have been underutilized during an iterative training process, which -- potentially of independent interest -- results in a natural yet effective insight to learning streams of non-i.i.d. data. (3) We incorporate the concept of random decision tree splits to concentrate privacy budget on learning leaves. (4) We deploy subsampling for privacy amplification. Our evaluation shows for the Abalone dataset ($<4k$ training data points) a $R^2$-score of $0.39$ for $\varepsilon=0.15$, which the closest prior work only achieved for $\varepsilon=10.0$. On the Adult dataset ($50k$ training data points) we achieve test error of $18.7\,\%$ for $\varepsilon=0.07$ which the closest prior work only achieved for $\varepsilon=1.0$. For the Abalone dataset for $\varepsilon=0.54$ we achieve $R^2$-score of $0.47$ which is very close to the $R^2$-score of $0.54$ for the nonprivate version of GBDT. For the Adult dataset for $\varepsilon=0.54$ we achieve test error $17.1\,\%$ which is very close to the test error $13.7\,\%$ of the nonprivate version of GBDT.
The Applicability of Federated Learning to Official Statistics
Jul 28, 2023



This work investigates the potential of Federated Learning (FL) for official statistics and shows how well the performance of FL models can keep up with centralized learning methods. At the same time, its utilization can safeguard the privacy of data holders, thus facilitating access to a broader range of data and ultimately enhancing official statistics. By simulating three different use cases, important insights on the applicability of the technology are gained. The use cases are based on a medical insurance data set, a fine dust pollution data set and a mobile radio coverage data set - all of which are from domains close to official statistics. We provide a detailed analysis of the results, including a comparison of centralized and FL algorithm performances for each simulation. In all three use cases, we were able to train models via FL which reach a performance very close to the centralized model benchmarks. Our key observations and their implications for transferring the simulations into practice are summarized. We arrive at the conclusion that FL has the potential to emerge as a pivotal technology in future use cases of official statistics.
Property Unlearning: A Defense Strategy Against Property Inference Attacks
May 18, 2022
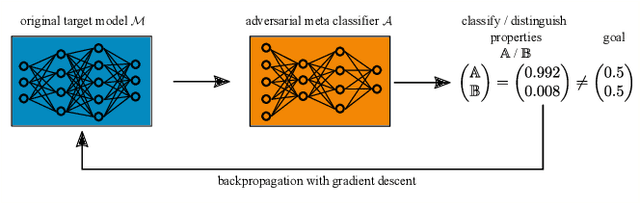
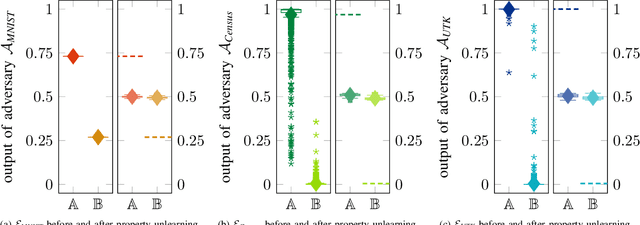
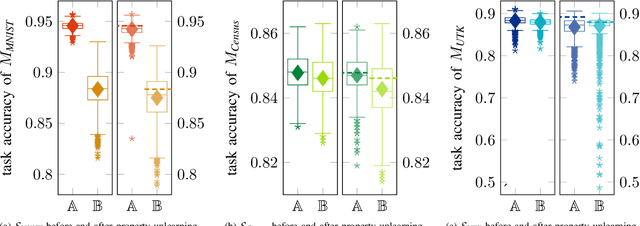
During the training of machine learning models, they may store or "learn" more information about the training data than what is actually needed for the prediction or classification task. This is exploited by property inference attacks which aim at extracting statistical properties from the training data of a given model without having access to the training data itself. These properties may include the quality of pictures to identify the camera model, the age distribution to reveal the target audience of a product, or the included host types to refine a malware attack in computer networks. This attack is especially accurate when the attacker has access to all model parameters, i.e., in a white-box scenario. By defending against such attacks, model owners are able to ensure that their training data, associated properties, and thus their intellectual property stays private, even if they deliberately share their models, e.g., to train collaboratively, or if models are leaked. In this paper, we introduce property unlearning, an effective defense mechanism against white-box property inference attacks, independent of the training data type, model task, or number of properties. Property unlearning mitigates property inference attacks by systematically changing the trained weights and biases of a target model such that an adversary cannot extract chosen properties. We empirically evaluate property unlearning on three different data sets, including tabular and image data, and two types of artificial neural networks. Our results show that property unlearning is both efficient and reliable to protect machine learning models against property inference attacks, with a good privacy-utility trade-off. Furthermore, our approach indicates that this mechanism is also effective to unlearn multiple properties.