 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvariant Anomaly Detection under Distribution Shifts: A Causal Perspective
Dec 21, 2023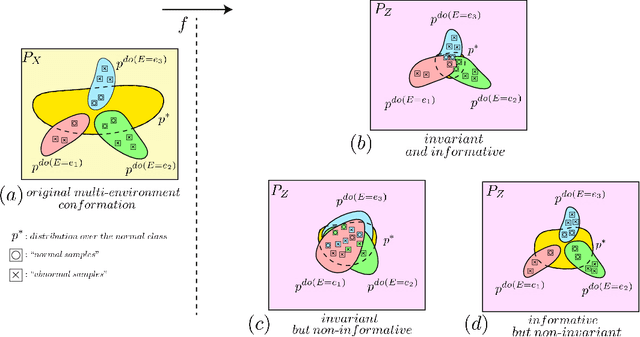
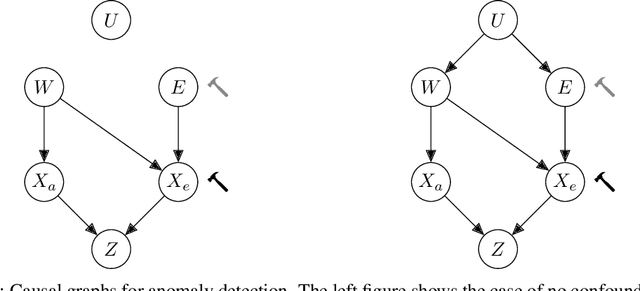
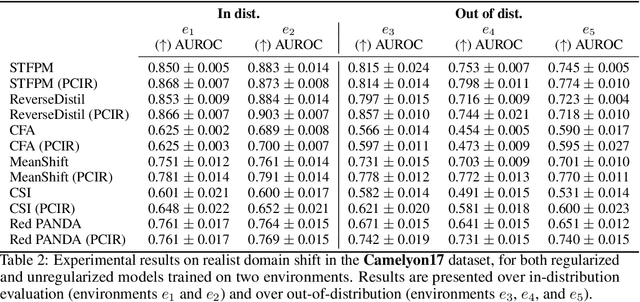
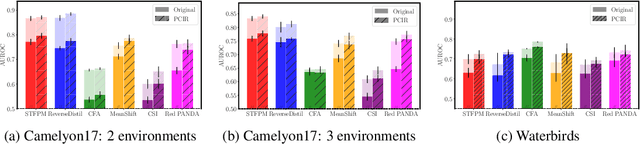
Anomaly detection (AD) is the machine learning task of identifying highly discrepant abnormal samples by solely relying on the consistency of the normal training samples. Under the constraints of a distribution shift, the assumption that training samples and test samples are drawn from the same distribution breaks down. In this work, by leveraging tools from causal inference we attempt to increase the resilience of anomaly detection models to different kinds of distribution shifts. We begin by elucidating a simple yet necessary statistical property that ensures invariant representations, which is critical for robust AD under both domain and covariate shifts. From this property, we derive a regularization term which, when minimized, leads to partial distribution invariance across environments. Through extensive experimental evaluation on both synthetic and real-world tasks, covering a range of six different AD methods, we demonstrated significant improvements in out-of-distribution performance. Under both covariate and domain shift, models regularized with our proposed term showed marked increased robustness. Code is available at: https://github.com/JoaoCarv/invariant-anomaly-detection.
Improving Explainability of Disentangled Representations using Multipath-Attribution Mappings
Jun 15, 2023Explainable AI aims to render model behavior understandable by humans, which can be seen as an intermediate step in extracting causal relations from correlative patterns. Due to the high risk of possible fatal decisions in image-based clinical diagnostics, it is necessary to integrate explainable AI into these safety-critical systems. Current explanatory methods typically assign attribution scores to pixel regions in the input image, indicating their importance for a model's decision. However, they fall short when explaining why a visual feature is used. We propose a framework that utilizes interpretable disentangled representations for downstream-task prediction. Through visualizing the disentangled representations, we enable experts to investigate possible causation effects by leveraging their domain knowledge. Additionally, we deploy a multi-path attribution mapping for enriching and validating explanations. We demonstrate the effectiveness of our approach on a synthetic benchmark suite and two medical datasets. We show that the framework not only acts as a catalyst for causal relation extraction but also enhances model robustness by enabling shortcut detection without the need for testing under distribution shifts.
Spatially Dependent U-Nets: Highly Accurate Architectures for Medical Imaging Segmentation
Mar 22, 2021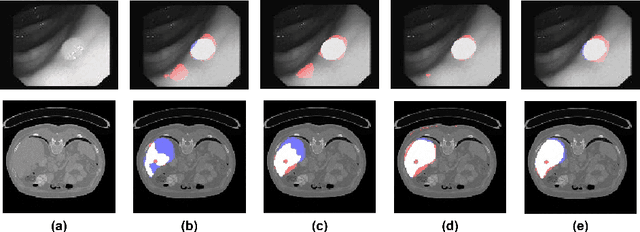
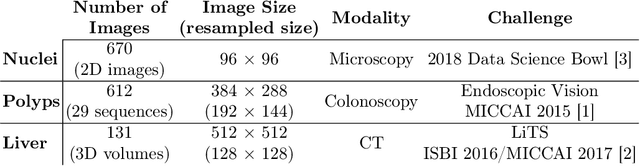
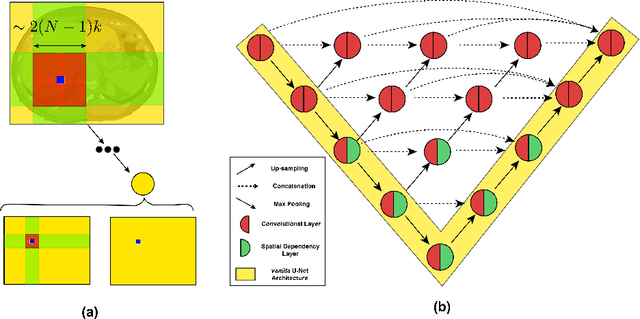
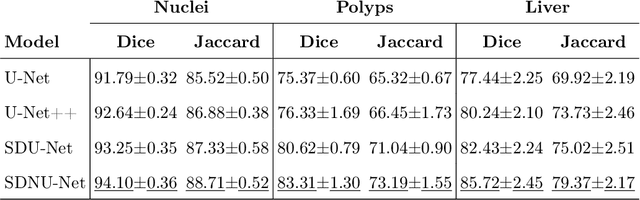
In clinical practice, regions of interest in medical imaging often need to be identified through a process of precise image segmentation. The quality of this image segmentation step critically affects the subsequent clinical assessment of the patient status. To enable high accuracy, automatic image segmentation, we introduce a novel deep neural network architecture that exploits the inherent spatial coherence of anatomical structures and is well equipped to capture long-range spatial dependencies in the segmented pixel/voxel space. In contrast to the state-of-the-art solutions based on convolutional layers, our approach leverages on recently introduced spatial dependency layers that have an unbounded receptive field and explicitly model the inductive bias of spatial coherence. Our method performs favourably to commonly used U-Net and U-Net++ architectures as demonstrated by improved Dice and Jaccardscore in three different medical segmentation tasks: nuclei segmentation in microscopy images, polyp segmentation in colonoscopy videos, and liver segmentation in abdominal CT scans.