 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResponsible and Regulatory Conform Machine Learning for Medicine: A Survey of Technical Challenges and Solutions
Jul 20, 2021

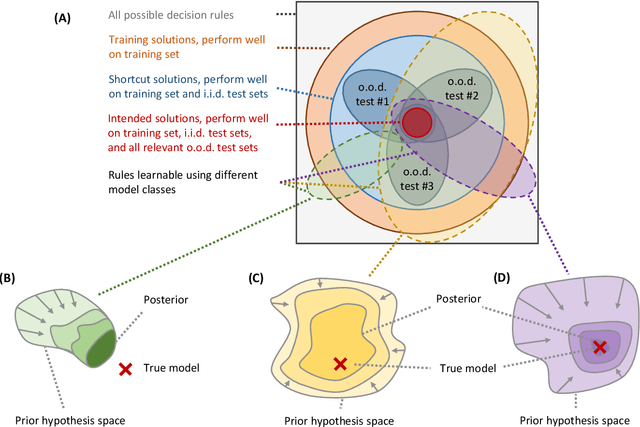

Machine learning is expected to fuel significant improvements in medical care. To ensure that fundamental principles such as beneficence, respect for human autonomy, prevention of harm, justice, privacy, and transparency are respected, medical machine learning applications must be developed responsibly. In this paper, we survey the technical challenges involved in creating medical machine learning systems responsibly and in conformity with existing regulations, as well as possible solutions to address these challenges. We begin by providing a brief overview of existing regulations affecting medical machine learning, showing that properties such as safety, robustness, reliability, privacy, security, transparency, explainability, and nondiscrimination are all demanded already by existing law and regulations - albeit, in many cases, to an uncertain degree. Next, we discuss the underlying technical challenges, possible ways for addressing them, and their respective merits and drawbacks. We notice that distribution shift, spurious correlations, model underspecification, and data scarcity represent severe challenges in the medical context (and others) that are very difficult to solve with classical black-box deep neural networks. Important measures that may help to address these challenges include the use of large and representative datasets and federated learning as a means to that end, the careful exploitation of domain knowledge wherever feasible, the use of inherently transparent models, comprehensive model testing and verification, as well as stakeholder inclusion.