 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the fairness of risk score models
Paper and Code
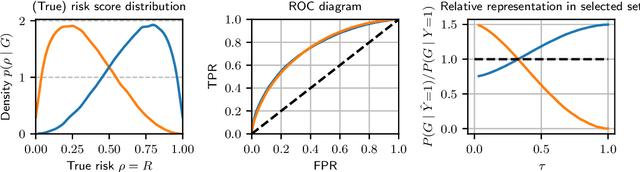
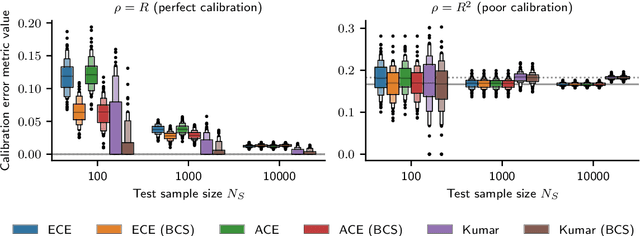
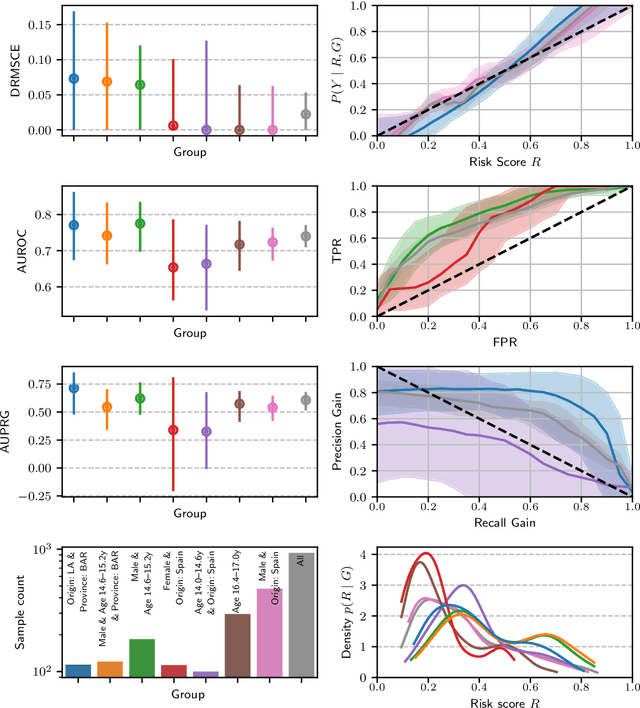
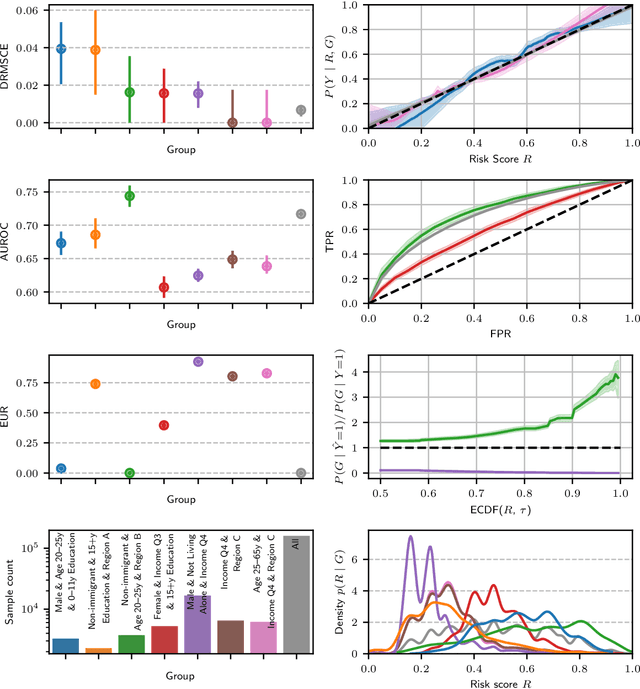
Recent work on algorithmic fairness has largely focused on the fairness of discrete decisions, or classifications. While such decisions are often based on risk score models, the fairness of the risk models themselves has received considerably less attention. Risk models are of interest for a number of reasons, including the fact that they communicate uncertainty about the potential outcomes to users, thus representing a way to enable meaningful human oversight. Here, we address fairness desiderata for risk score models. We identify the provision of similar epistemic value to different groups as a key desideratum for risk score fairness. Further, we address how to assess the fairness of risk score models quantitatively, including a discussion of metric choices and meaningful statistical comparisons between groups. In this context, we also introduce a novel calibration error metric that is less sample size-biased than previously proposed metrics, enabling meaningful comparisons between groups of different sizes. We illustrate our methodology - which is widely applicable in many other settings - in two case studies, one in recidivism risk prediction, and one in risk of major depressive disorder (MDD) prediction.