 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Interpretability of Programmatic Policies with Large Language Models
Paper and Code
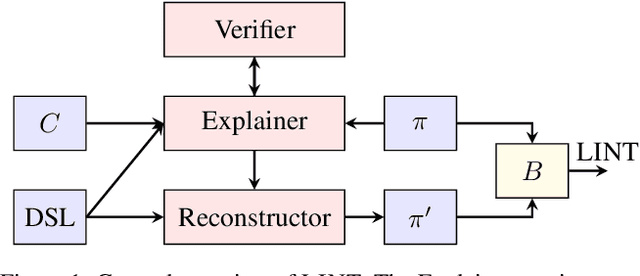


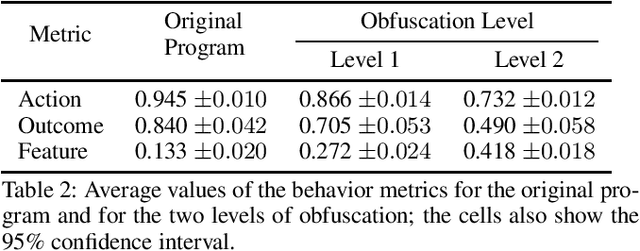
Although the synthesis of programs encoding policies often carries the promise of interpretability, systematic evaluations to assess the interpretability of these policies were never performed, likely because of the complexity of such an evaluation. In this paper, we introduce a novel metric that uses large-language models (LLM) to assess the interpretability of programmatic policies. For our metric, an LLM is given both a program and a description of its associated programming language. The LLM then formulates a natural language explanation of the program. This explanation is subsequently fed into a second LLM, which tries to reconstruct the program from the natural language explanation. Our metric measures the behavioral similarity between the reconstructed program and the original. We validate our approach using obfuscated programs that are used to solve classic programming problems. We also assess our metric with programmatic policies synthesized for playing a real-time strategy game, comparing the interpretability scores of programmatic policies synthesized by an existing system to lightly obfuscated versions of the same programs. Our LLM-based interpretability score consistently ranks less interpretable programs lower and more interpretable ones higher. These findings suggest that our metric could serve as a reliable and inexpensive tool for evaluating the interpretability of programmatic policies.