 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Human Eye Movements with Neural Networks in a Maze-Solving Task
Dec 20, 2022



From smoothly pursuing moving objects to rapidly shifting gazes during visual search, humans employ a wide variety of eye movement strategies in different contexts. While eye movements provide a rich window into mental processes, building generative models of eye movements is notoriously difficult, and to date the computational objectives guiding eye movements remain largely a mystery. In this work, we tackled these problems in the context of a canonical spatial planning task, maze-solving. We collected eye movement data from human subjects and built deep generative models of eye movements using a novel differentiable architecture for gaze fixations and gaze shifts. We found that human eye movements are best predicted by a model that is optimized not to perform the task as efficiently as possible but instead to run an internal simulation of an object traversing the maze. This not only provides a generative model of eye movements in this task but also suggests a computational theory for how humans solve the task, namely that humans use mental simulation.
Modular Object-Oriented Games: A Task Framework for Reinforcement Learning, Psychology, and Neuroscience
Feb 25, 2021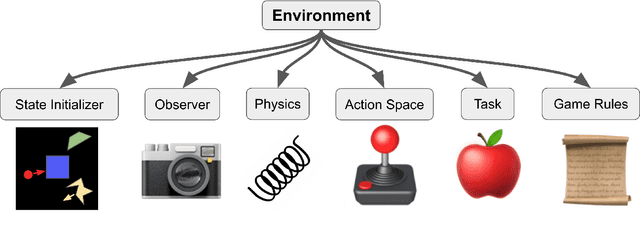
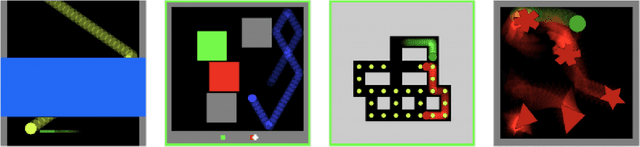
In recent years, trends towards studying simulated games have gained momentum in the fields of artificial intelligence, cognitive science, psychology, and neuroscience. The intersections of these fields have also grown recently, as researchers increasing study such games using both artificial agents and human or animal subjects. However, implementing games can be a time-consuming endeavor and may require a researcher to grapple with complex codebases that are not easily customized. Furthermore, interdisciplinary researchers studying some combination of artificial intelligence, human psychology, and animal neurophysiology face additional challenges, because existing platforms are designed for only one of these domains. Here we introduce Modular Object-Oriented Games, a Python task framework that is lightweight, flexible, customizable, and designed for use by machine learning, psychology, and neurophysiology researchers.
A Heuristic for Unsupervised Model Selection for Variational Disentangled Representation Learning
May 29, 2019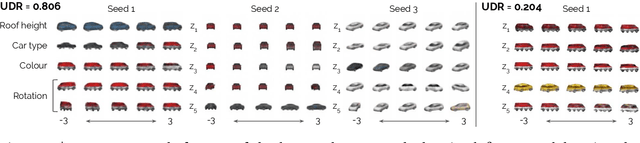

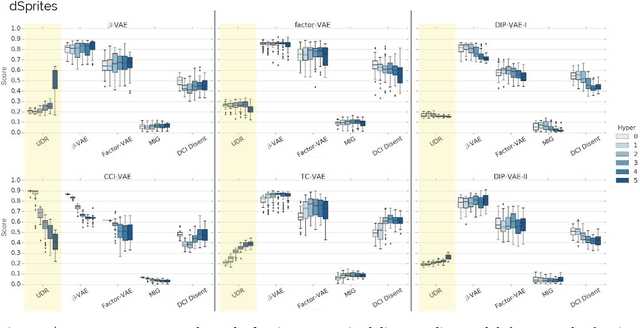

Disentangled representations have recently been shown to improve data efficiency, generalisation, robustness and interpretability in simple supervised and reinforcement learning tasks. To extend such results to more complex domains, it is important to address a major shortcoming of the current state of the art unsupervised disentangling approaches -- high convergence variance, whereby different disentanglement quality may be achieved by the same model depending on its initial state. The existing model selection methods require access to the ground truth attribute labels, which are not available for most datasets. Hence, the benefits of disentangled representations have not yet been fully explored in practical applications. This paper addresses this problem by introducing a simple yet robust and reliable method for unsupervised disentangled model selection. We show that our approach performs comparably to the existing supervised alternatives across 5400 models from six state of the art unsupervised disentangled representation learning model classes.
COBRA: Data-Efficient Model-Based RL through Unsupervised Object Discovery and Curiosity-Driven Exploration
May 22, 2019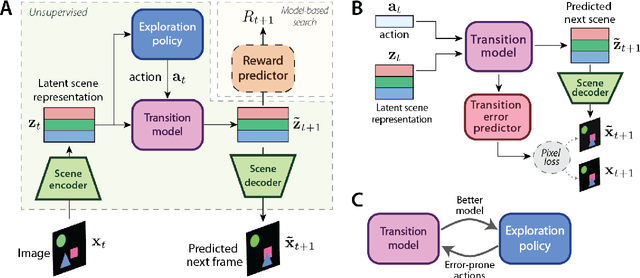


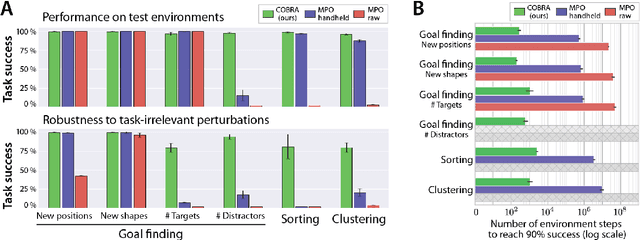
Data efficiency and robustness to task-irrelevant perturbations are long-standing challenges for deep reinforcement learning algorithms. Here we introduce a modular approach to addressing these challenges in a continuous control environment, without using hand-crafted or supervised information. Our Curious Object-Based seaRch Agent (COBRA) uses task-free intrinsically motivated exploration and unsupervised learning to build object-based models of its environment and action space. Subsequently, it can learn a variety of tasks through model-based search in very few steps and excel on structured hold-out tests of policy robustness.
MONet: Unsupervised Scene Decomposition and Representation
Jan 22, 2019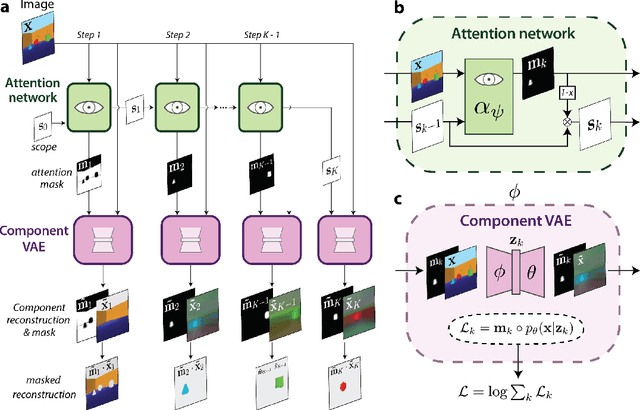
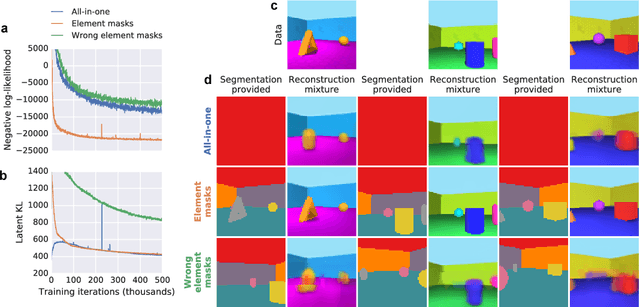
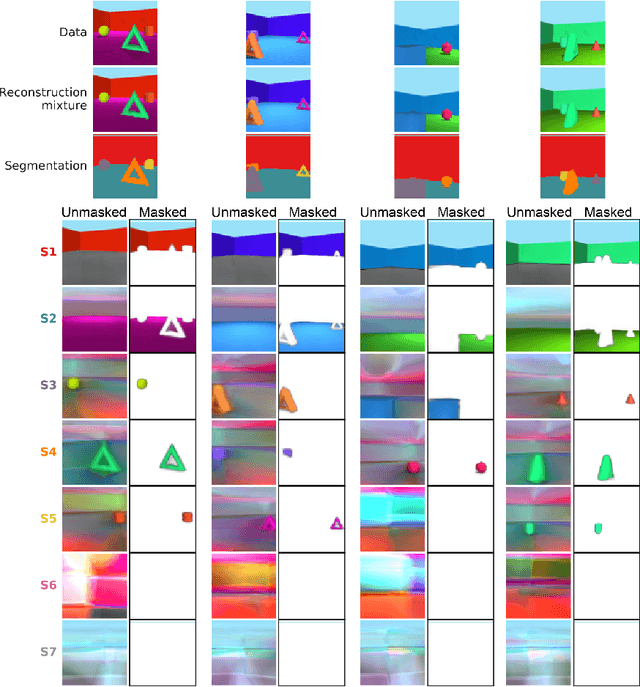
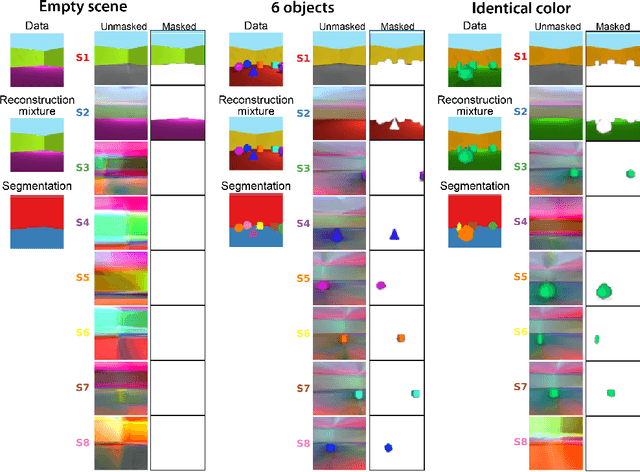
The ability to decompose scenes in terms of abstract building blocks is crucial for general intelligence. Where those basic building blocks share meaningful properties, interactions and other regularities across scenes, such decompositions can simplify reasoning and facilitate imagination of novel scenarios. In particular, representing perceptual observations in terms of entities should improve data efficiency and transfer performance on a wide range of tasks. Thus we need models capable of discovering useful decompositions of scenes by identifying units with such regularities and representing them in a common format. To address this problem, we have developed the Multi-Object Network (MONet). In this model, a VAE is trained end-to-end together with a recurrent attention network -- in a purely unsupervised manner -- to provide attention masks around, and reconstructions of, regions of images. We show that this model is capable of learning to decompose and represent challenging 3D scenes into semantically meaningful components, such as objects and background elements.
Spatial Broadcast Decoder: A Simple Architecture for Learning Disentangled Representations in VAEs
Jan 21, 2019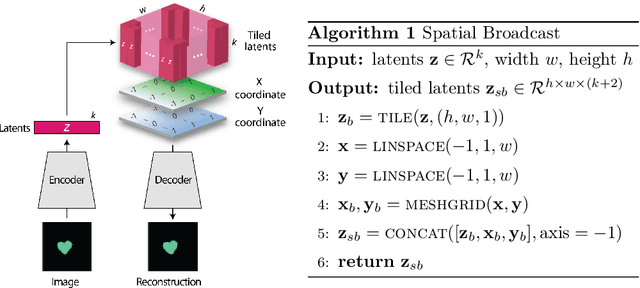

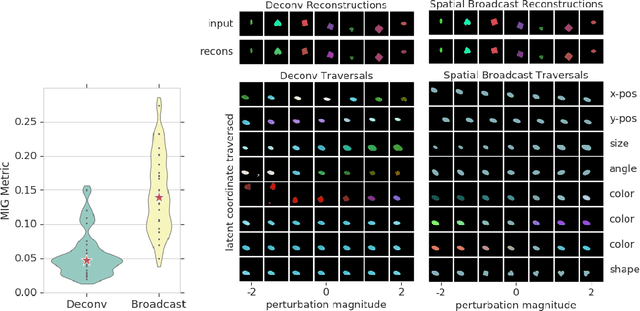

We present a simple neural rendering architecture that helps variational autoencoders (VAEs) learn disentangled representations. Instead of the deconvolutional network typically used in the decoder of VAEs, we tile (broadcast) the latent vector across space, concatenate fixed X- and Y-"coordinate" channels, and apply a fully convolutional network with 1x1 stride. This provides an architectural prior for dissociating positional from non-positional features in the latent distribution of VAEs, yet without providing any explicit supervision to this effect. We show that this architecture, which we term the Spatial Broadcast decoder, improves disentangling, reconstruction accuracy, and generalization to held-out regions in data space. It provides a particularly dramatic benefit when applied to datasets with small objects. We also emphasize a method for visualizing learned latent spaces that helped us diagnose our models and may prove useful for others aiming to assess data representations. Finally, we show the Spatial Broadcast Decoder is complementary to state-of-the-art (SOTA) disentangling techniques and when incorporated improves their performance.
Visual Interaction Networks
Jun 05, 2017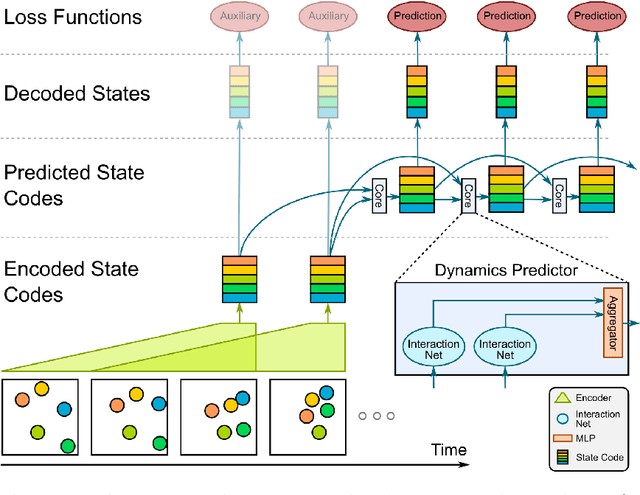

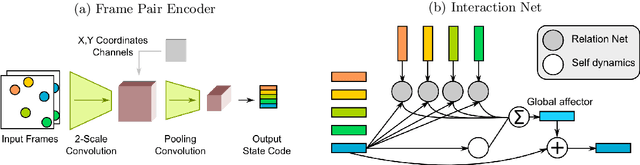
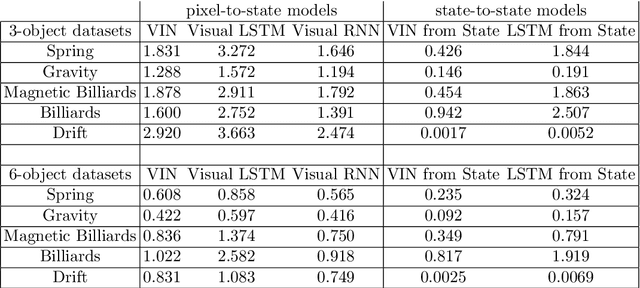
From just a glance, humans can make rich predictions about the future state of a wide range of physical systems. On the other hand, modern approaches from engineering, robotics, and graphics are often restricted to narrow domains and require direct measurements of the underlying states. We introduce the Visual Interaction Network, a general-purpose model for learning the dynamics of a physical system from raw visual observations. Our model consists of a perceptual front-end based on convolutional neural networks and a dynamics predictor based on interaction networks. Through joint training, the perceptual front-end learns to parse a dynamic visual scene into a set of factored latent object representations. The dynamics predictor learns to roll these states forward in time by computing their interactions and dynamics, producing a predicted physical trajectory of arbitrary length. We found that from just six input video frames the Visual Interaction Network can generate accurate future trajectories of hundreds of time steps on a wide range of physical systems. Our model can also be applied to scenes with invisible objects, inferring their future states from their effects on the visible objects, and can implicitly infer the unknown mass of objects. Our results demonstrate that the perceptual module and the object-based dynamics predictor module can induce factored latent representations that support accurate dynamical predictions. This work opens new opportunities for model-based decision-making and planning from raw sensory observations in complex physical environments.