 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Latent Memories: Assessing Data Leakage and Memorization Patterns in Large Language Models
Jun 20, 2024The proliferation of large language models has revolutionized natural language processing tasks, yet it raises profound concerns regarding data privacy and security. Language models are trained on extensive corpora including potentially sensitive or proprietary information, and the risk of data leakage -- where the model response reveals pieces of such information -- remains inadequately understood. This study examines susceptibility to data leakage by quantifying the phenomenon of memorization in machine learning models, focusing on the evolution of memorization patterns over training. We investigate how the statistical characteristics of training data influence the memories encoded within the model by evaluating how repetition influences memorization. We reproduce findings that the probability of memorizing a sequence scales logarithmically with the number of times it is present in the data. Furthermore, we find that sequences which are not apparently memorized after the first encounter can be uncovered throughout the course of training even without subsequent encounters. The presence of these latent memorized sequences presents a challenge for data privacy since they may be hidden at the final checkpoint of the model. To this end, we develop a diagnostic test for uncovering these latent memorized sequences by considering their cross entropy loss.
A Heuristic for Unsupervised Model Selection for Variational Disentangled Representation Learning
May 29, 2019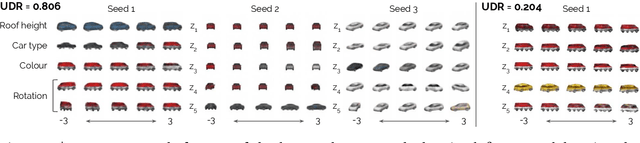

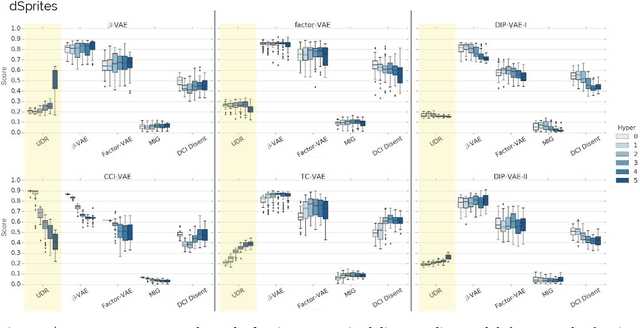

Disentangled representations have recently been shown to improve data efficiency, generalisation, robustness and interpretability in simple supervised and reinforcement learning tasks. To extend such results to more complex domains, it is important to address a major shortcoming of the current state of the art unsupervised disentangling approaches -- high convergence variance, whereby different disentanglement quality may be achieved by the same model depending on its initial state. The existing model selection methods require access to the ground truth attribute labels, which are not available for most datasets. Hence, the benefits of disentangled representations have not yet been fully explored in practical applications. This paper addresses this problem by introducing a simple yet robust and reliable method for unsupervised disentangled model selection. We show that our approach performs comparably to the existing supervised alternatives across 5400 models from six state of the art unsupervised disentangled representation learning model classes.