 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSet Learning for Accurate and Calibrated Models
Paper and Code
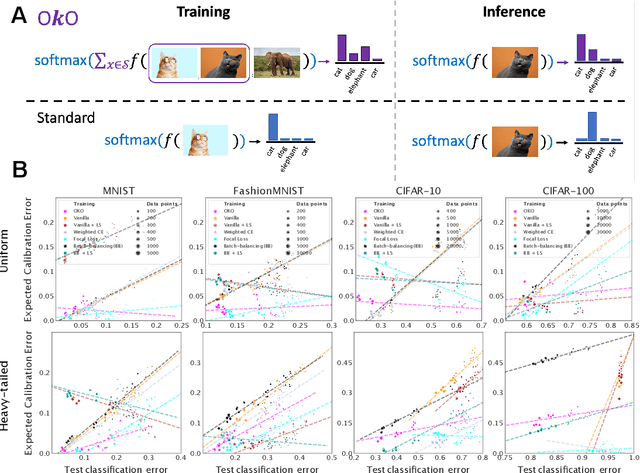
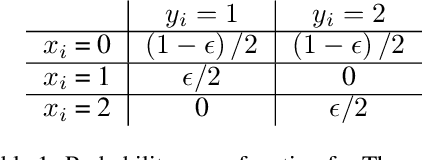
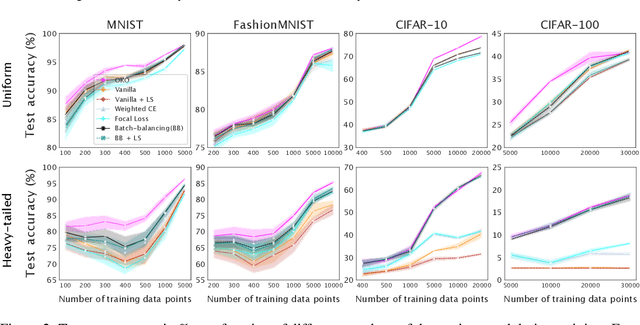
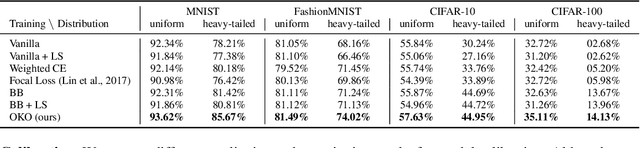
Model overconfidence and poor calibration are common in machine learning and difficult to account for when applying standard empirical risk minimization. In this work, we propose a novel method to alleviate these problems that we call odd-$k$-out learning (OKO), which minimizes the cross-entropy error for sets rather than for single examples. This naturally allows the model to capture correlations across data examples and achieves both better accuracy and calibration, especially in limited training data and class-imbalanced regimes. Perhaps surprisingly, OKO often yields better calibration even when training with hard labels and dropping any additional calibration parameter tuning, such as temperature scaling. We provide theoretical justification, establishing that OKO naturally yields better calibration, and provide extensive experimental analyses that corroborate our theoretical findings. We emphasize that OKO is a general framework that can be easily adapted to many settings and the trained model can be applied to single examples at inference time, without introducing significant run-time overhead or architecture changes.