 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Vizier Gaussian Process Bandit Algorithm
Aug 21, 2024Google Vizier has performed millions of optimizations and accelerated numerous research and production systems at Google, demonstrating the success of Bayesian optimization as a large-scale service. Over multiple years, its algorithm has been improved considerably, through the collective experiences of numerous research efforts and user feedback. In this technical report, we discuss the implementation details and design choices of the current default algorithm provided by Open Source Vizier. Our experiments on standardized benchmarks reveal its robustness and versatility against well-established industry baselines on multiple practical modes.
Open Source Vizier: Distributed Infrastructure and API for Reliable and Flexible Blackbox Optimization
Jul 27, 2022
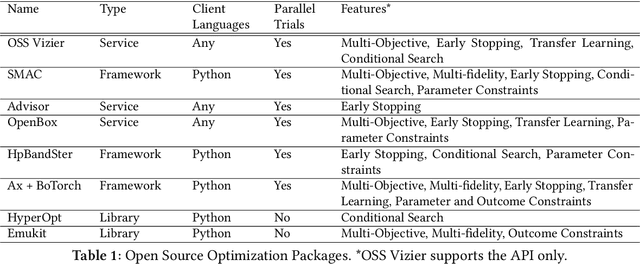

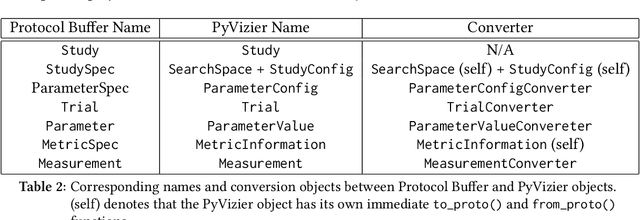
Vizier is the de-facto blackbox and hyperparameter optimization service across Google, having optimized some of Google's largest products and research efforts. To operate at the scale of tuning thousands of users' critical systems, Google Vizier solved key design challenges in providing multiple different features, while remaining fully fault-tolerant. In this paper, we introduce Open Source (OSS) Vizier, a standalone Python-based interface for blackbox optimization and research, based on the Google-internal Vizier infrastructure and framework. OSS Vizier provides an API capable of defining and solving a wide variety of optimization problems, including multi-metric, early stopping, transfer learning, and conditional search. Furthermore, it is designed to be a distributed system that assures reliability, and allows multiple parallel evaluations of the user's objective function. The flexible RPC-based infrastructure allows users to access OSS Vizier from binaries written in any language. OSS Vizier also provides a back-end ("Pythia") API that gives algorithm authors a way to interface new algorithms with the core OSS Vizier system. OSS Vizier is available at https://github.com/google/vizier.
Towards Learning Universal Hyperparameter Optimizers with Transformers
May 26, 2022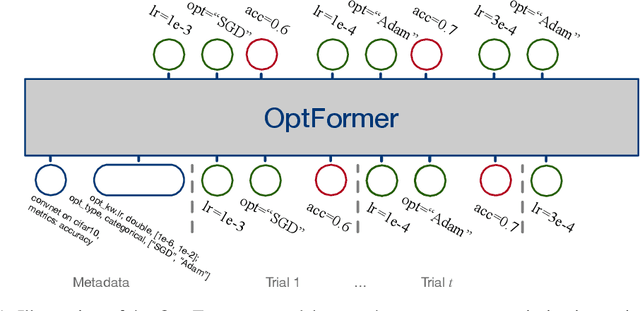


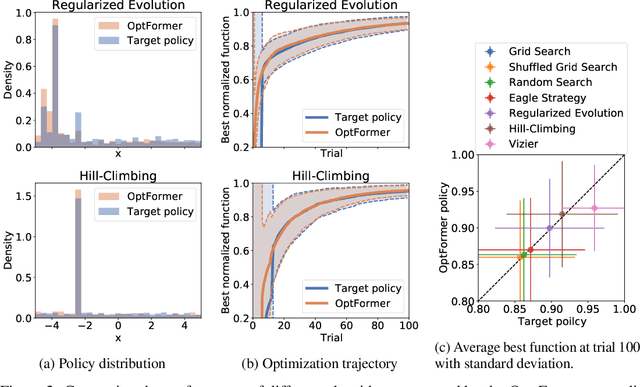
Meta-learning hyperparameter optimization (HPO) algorithms from prior experiments is a promising approach to improve optimization efficiency over objective functions from a similar distribution. However, existing methods are restricted to learning from experiments sharing the same set of hyperparameters. In this paper, we introduce the OptFormer, the first text-based Transformer HPO framework that provides a universal end-to-end interface for jointly learning policy and function prediction when trained on vast tuning data from the wild. Our extensive experiments demonstrate that the OptFormer can imitate at least 7 different HPO algorithms, which can be further improved via its function uncertainty estimates. Compared to a Gaussian Process, the OptFormer also learns a robust prior distribution for hyperparameter response functions, and can thereby provide more accurate and better calibrated predictions. This work paves the path to future extensions for training a Transformer-based model as a general HPO optimizer.
Gradientless Descent: High-Dimensional Zeroth-Order Optimization
Nov 19, 2019
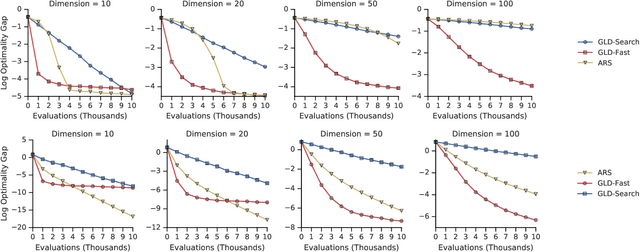
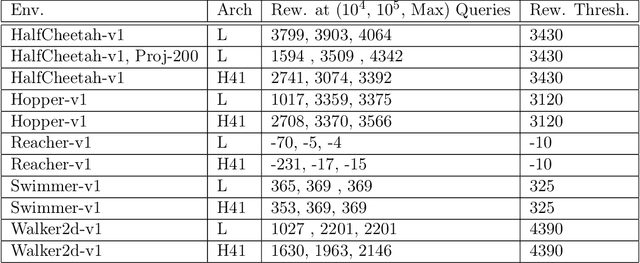

Zeroth-order optimization is the process of minimizing an objective $f(x)$, given oracle access to evaluations at adaptively chosen inputs $x$. In this paper, we present two simple yet powerful GradientLess Descent (GLD) algorithms that do not rely on an underlying gradient estimate and are numerically stable. We analyze our algorithm from a novel geometric perspective and present a novel analysis that shows convergence within an $\epsilon$-ball of the optimum in $O(kQ\log(n)\log(R/\epsilon))$ evaluations, for any monotone transform of a smooth and strongly convex objective with latent dimension $k < n$, where the input dimension is $n$, $R$ is the diameter of the input space and $Q$ is the condition number. Our rates are the first of its kind to be both 1) poly-logarithmically dependent on dimensionality and 2) invariant under monotone transformations. We further leverage our geometric perspective to show that our analysis is optimal. Both monotone invariance and its ability to utilize a low latent dimensionality are key to the empirical success of our algorithms, as demonstrated on BBOB and MuJoCo benchmarks.