 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Adversarially Robust Deepfake Detection: An Ensemble Approach
Paper and Code
Feb 11, 2022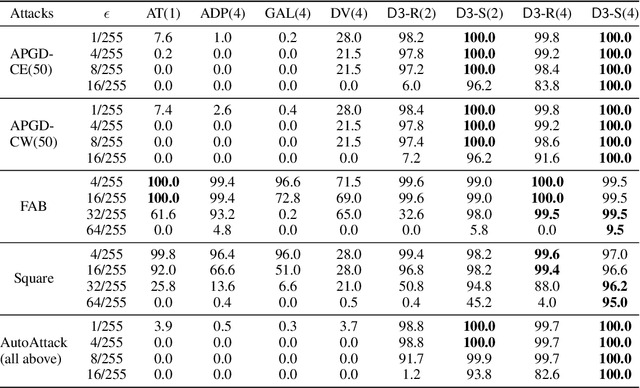
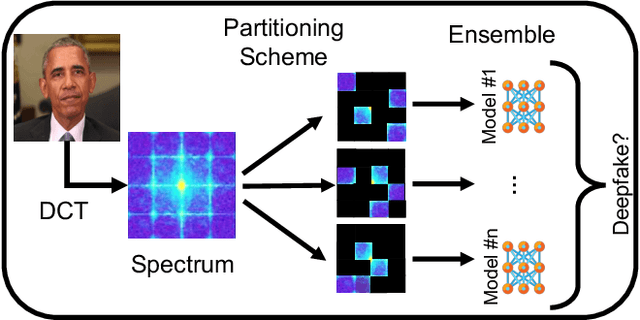
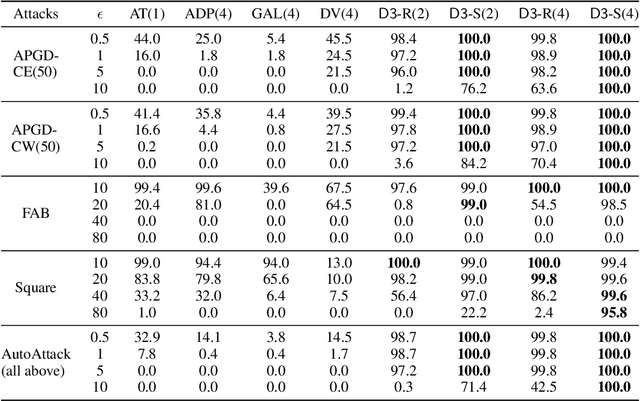
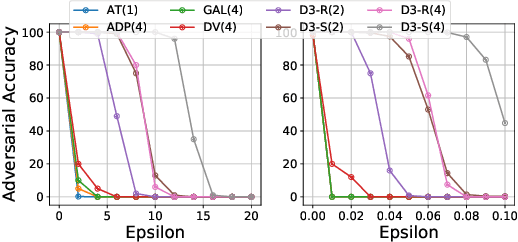
Detecting deepfakes is an important problem, but recent work has shown that DNN-based deepfake detectors are brittle against adversarial deepfakes, in which an adversary adds imperceptible perturbations to a deepfake to evade detection. In this work, we show that a modification to the detection strategy in which we replace a single classifier with a carefully chosen ensemble, in which input transformations for each model in the ensemble induces pairwise orthogonal gradients, can significantly improve robustness beyond the de facto solution of adversarial training. We present theoretical results to show that such orthogonal gradients can help thwart a first-order adversary by reducing the dimensionality of the input subspace in which adversarial deepfakes lie. We validate the results empirically by instantiating and evaluating a randomized version of such "orthogonal" ensembles for adversarial deepfake detection and find that these randomized ensembles exhibit significantly higher robustness as deepfake detectors compared to state-of-the-art deepfake detectors against adversarial deepfakes, even those created using strong PGD-500 attacks.