 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Agent Planning for Security and Autonomy
Feb 11, 2026Indirect prompt injection attacks threaten AI agents that execute consequential actions, motivating deterministic system-level defenses. Such defenses can provably block unsafe actions by enforcing confidentiality and integrity policies, but currently appear costly: they reduce task completion rates and increase token usage compared to probabilistic defenses. We argue that existing evaluations miss a key benefit of system-level defenses: reduced reliance on human oversight. We introduce autonomy metrics to quantify this benefit: the fraction of consequential actions an agent can execute without human-in-the-loop (HITL) approval while preserving security. To increase autonomy, we design a security-aware agent that (i) introduces richer HITL interactions, and (ii) explicitly plans for both task progress and policy compliance. We implement this agent design atop an existing information-flow control defense against prompt injection and evaluate it on the AgentDojo and WASP benchmarks. Experiments show that this approach yields higher autonomy without sacrificing utility.
Securing AI Agents with Information-Flow Control
May 29, 2025As AI agents become increasingly autonomous and capable, ensuring their security against vulnerabilities such as prompt injection becomes critical. This paper explores the use of information-flow control (IFC) to provide security guarantees for AI agents. We present a formal model to reason about the security and expressiveness of agent planners. Using this model, we characterize the class of properties enforceable by dynamic taint-tracking and construct a taxonomy of tasks to evaluate security and utility trade-offs of planner designs. Informed by this exploration, we present Fides, a planner that tracks confidentiality and integrity labels, deterministically enforces security policies, and introduces novel primitives for selectively hiding information. Its evaluation in AgentDojo demonstrates that this approach broadens the range of tasks that can be securely accomplished. A tutorial to walk readers through the the concepts introduced in the paper can be found at https://github.com/microsoft/fides
Attacking Byzantine Robust Aggregation in High Dimensions
Dec 22, 2023Training modern neural networks or models typically requires averaging over a sample of high-dimensional vectors. Poisoning attacks can skew or bias the average vectors used to train the model, forcing the model to learn specific patterns or avoid learning anything useful. Byzantine robust aggregation is a principled algorithmic defense against such biasing. Robust aggregators can bound the maximum bias in computing centrality statistics, such as mean, even when some fraction of inputs are arbitrarily corrupted. Designing such aggregators is challenging when dealing with high dimensions. However, the first polynomial-time algorithms with strong theoretical bounds on the bias have recently been proposed. Their bounds are independent of the number of dimensions, promising a conceptual limit on the power of poisoning attacks in their ongoing arms race against defenses. In this paper, we show a new attack called HIDRA on practical realization of strong defenses which subverts their claim of dimension-independent bias. HIDRA highlights a novel computational bottleneck that has not been a concern of prior information-theoretic analysis. Our experimental evaluation shows that our attacks almost completely destroy the model performance, whereas existing attacks with the same goal fail to have much effect. Our findings leave the arms race between poisoning attacks and provable defenses wide open.
RETEXO: Scalable Neural Network Training over Distributed Graphs
Mar 08, 2023



Graph neural networks offer a promising approach to supervised learning over graph data. Graph data, especially when it is privacy-sensitive or too large to train on centrally, is often stored partitioned across disparate processing units (clients) which want to minimize the communication costs during collaborative training. The fully-distributed setup takes such partitioning to its extreme, wherein features of only a single node and its adjacent edges are kept locally with one client processor. Existing GNNs are not architected for training in such setups and incur prohibitive costs therein. We propose RETEXO, a novel transformation of existing GNNs that improves the communication efficiency during training in the fully-distributed setup. We experimentally confirm that RETEXO offers up to 6 orders of magnitude better communication efficiency even when training shallow GNNs, with a minimal trade-off in accuracy for supervised node classification tasks.
LPGNet: Link Private Graph Networks for Node Classification
May 06, 2022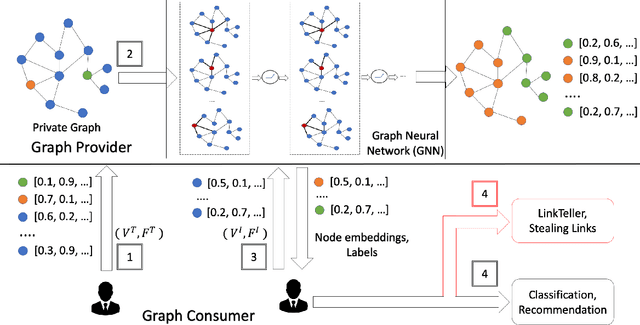

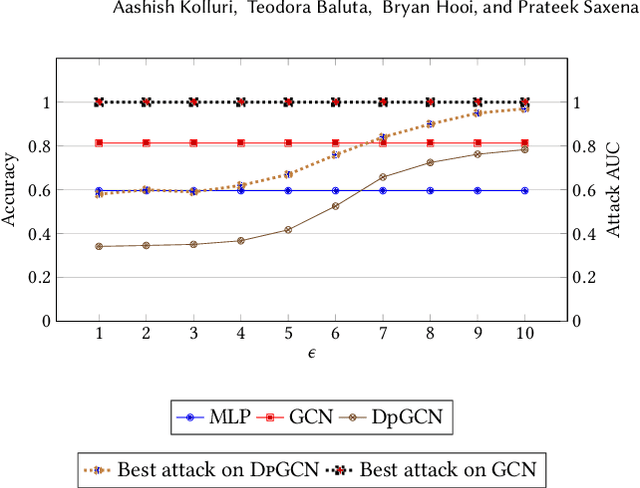

Classification tasks on labeled graph-structured data have many important applications ranging from social recommendation to financial modeling. Deep neural networks are increasingly being used for node classification on graphs, wherein nodes with similar features have to be given the same label. Graph convolutional networks (GCNs) are one such widely studied neural network architecture that perform well on this task. However, powerful link-stealing attacks on GCNs have recently shown that even with black-box access to the trained model, inferring which links (or edges) are present in the training graph is practical. In this paper, we present a new neural network architecture called LPGNet for training on graphs with privacy-sensitive edges. LPGNet provides differential privacy (DP) guarantees for edges using a novel design for how graph edge structure is used during training. We empirically show that LPGNet models often lie in the sweet spot between providing privacy and utility: They can offer better utility than "trivially" private architectures which use no edge information (e.g., vanilla MLPs) and better resilience against existing link-stealing attacks than vanilla GCNs which use the full edge structure. LPGNet also offers consistently better privacy-utility tradeoffs than DPGCN, which is the state-of-the-art mechanism for retrofitting differential privacy into conventional GCNs, in most of our evaluated datasets.