 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges to Solving Combinatorially Hard Long-Horizon Deep RL Tasks
Paper and Code
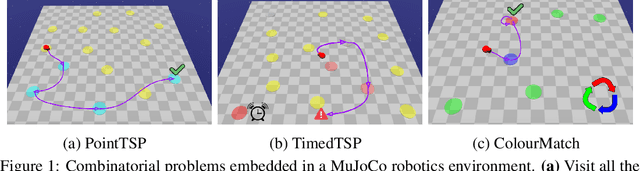
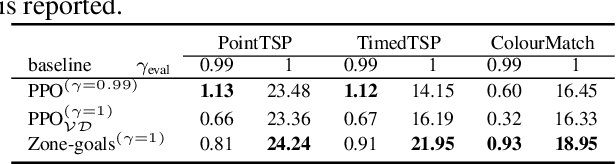
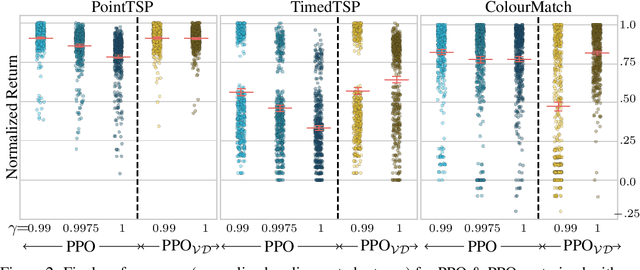
Deep reinforcement learning has shown promise in discrete domains requiring complex reasoning, including games such as Chess, Go, and Hanabi. However, this type of reasoning is less often observed in long-horizon, continuous domains with high-dimensional observations, where instead RL research has predominantly focused on problems with simple high-level structure (e.g. opening a drawer or moving a robot as fast as possible). Inspired by combinatorially hard optimization problems, we propose a set of robotics tasks which admit many distinct solutions at the high-level, but require reasoning about states and rewards thousands of steps into the future for the best performance. Critically, while RL has traditionally suffered on complex, long-horizon tasks due to sparse rewards, our tasks are carefully designed to be solvable without specialized exploration. Nevertheless, our investigation finds that standard RL methods often neglect long-term effects due to discounting, while general-purpose hierarchical RL approaches struggle unless additional abstract domain knowledge can be exploited.