 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Latent Space of Robot Dynamics for Cutting Interaction Inference
Paper and Code
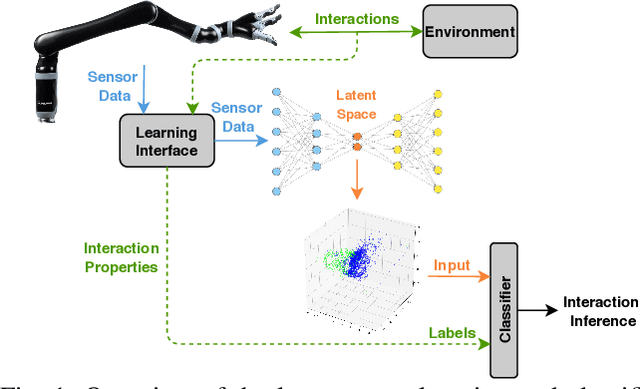
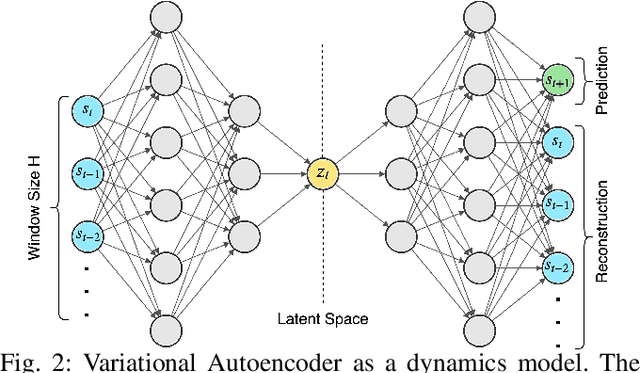

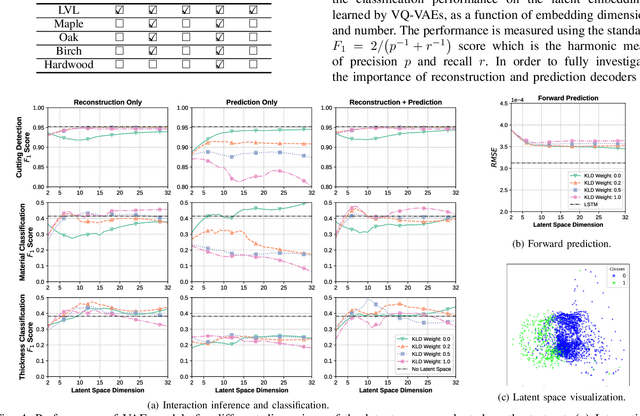
Utilization of latent space to capture a lower-dimensional representation of a complex dynamics model is explored in this work. The targeted application is of a robotic manipulator executing a complex environment interaction task, in particular, cutting a wooden object. We train two flavours of Variational Autoencoders---standard and Vector-Quantised---to learn the latent space which is then used to infer certain properties of the cutting operation, such as whether the robot is cutting or not, as well as, material and geometry of the object being cut. The two VAE models are evaluated with reconstruction, prediction and a combined reconstruction/prediction decoders. The results demonstrate the expressiveness of the latent space for robotic interaction inference and the competitive prediction performance against recurrent neural networks.