 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePINNOCHIO: Physics-Informed Neural Network for Coupled Hyperelastic Interface-Volume Simulation in Orthognathic Surgery
Jun 01, 2026Predicting patient-specific facial soft-tissue deformation is critical for iterative orthognathic surgery planning. However, current computational methods face a strict accuracy-efficiency trade-off: high-fidelity Finite Element Methods (FEM) are computationally prohibitive, whereas pure deep learning models often produce biomechanically inconsistent results. While Physics-Informed Neural Networks (PINNs) offer a promising avenue, learning the complex heterogeneous mechanics of bone--soft-tissue interactions with only partial clinical supervision (i.e., outer facial surfaces) remains highly unstable. To overcome these challenges, we present PINNOCHIO, a novel physics-informed framework for facial soft-tissue simulation. PINNOCHIO introduces a hybrid sequential decomposition that explicitly decouples discontinuous bone--soft-tissue interface movements from continuous volumetric hyperelastic deformation. This structural separation enables stable training and facilitates a physics-enabled sim-to-real adaptation strategy, ensuring internal biomechanical consistency without requiring volumetric ground truth. Evaluated on a 40-patient clinical cohort, PINNOCHIO outperforms existing baselines in both surface accuracy and physical validity. Furthermore, it achieves a substantial speedup over FEM, successfully resolving the accuracy-efficiency trade-off to provide a highly reliable and practical tool for interactive surgical planning.
Soft-tissue Driven Craniomaxillofacial Surgical Planning
Jul 20, 2023In CMF surgery, the planning of bony movement to achieve a desired facial outcome is a challenging task. Current bone driven approaches focus on normalizing the bone with the expectation that the facial appearance will be corrected accordingly. However, due to the complex non-linear relationship between bony structure and facial soft-tissue, such bone-driven methods are insufficient to correct facial deformities. Despite efforts to simulate facial changes resulting from bony movement, surgical planning still relies on iterative revisions and educated guesses. To address these issues, we propose a soft-tissue driven framework that can automatically create and verify surgical plans. Our framework consists of a bony planner network that estimates the bony movements required to achieve the desired facial outcome and a facial simulator network that can simulate the possible facial changes resulting from the estimated bony movement plans. By combining these two models, we can verify and determine the final bony movement required for planning. The proposed framework was evaluated using a clinical dataset, and our experimental results demonstrate that the soft-tissue driven approach greatly improves the accuracy and efficacy of surgical planning when compared to the conventional bone-driven approach.
Deep Learning-based Facial Appearance Simulation Driven by Surgically Planned Craniomaxillofacial Bony Movement
Oct 04, 2022Simulating facial appearance change following bony movement is a critical step in orthognathic surgical planning for patients with jaw deformities. Conventional biomechanics-based methods such as the finite-element method (FEM) are labor intensive and computationally inefficient. Deep learning-based approaches can be promising alternatives due to their high computational efficiency and strong modeling capability. However, the existing deep learning-based method ignores the physical correspondence between facial soft tissue and bony segments and thus is significantly less accurate compared to FEM. In this work, we propose an Attentive Correspondence assisted Movement Transformation network (ACMT-Net) to estimate the facial appearance by transforming the bony movement to facial soft tissue through a point-to-point attentive correspondence matrix. Experimental results on patients with jaw deformity show that our proposed method can achieve comparable facial change prediction accuracy compared with the state-of-the-art FEM-based approach with significantly improved computational efficiency.
Federated Cross Learning for Medical Image Segmentation
Apr 05, 2022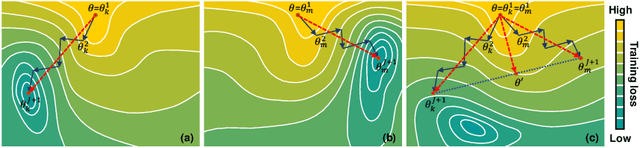
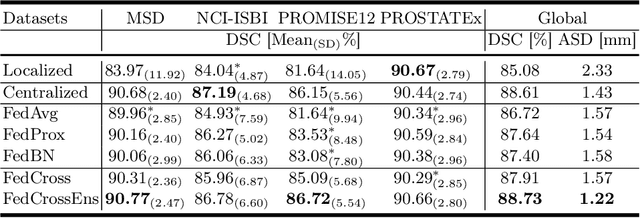

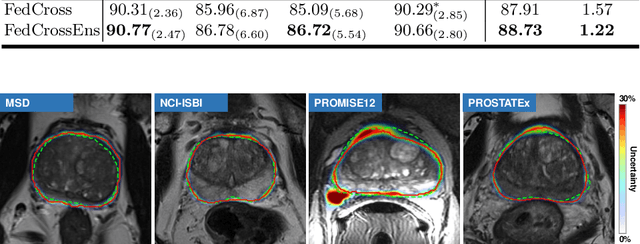
Federated learning (FL) can collaboratively train deep learning models using isolated patient data owned by different hospitals for various clinical applications, including medical image segmentation. However, a major problem of FL is its performance degradation when dealing with the data that are not independently and identically distributed (non-iid), which is often the case in medical images. In this paper, we first conduct a theoretical analysis on the FL algorithm to reveal the problem of model aggregation during training on non-iid data. With the insights gained through the analysis, we propose a simple and yet effective method, federated cross learning (FedCross), to tackle this challenging problem. Unlike the conventional FL methods that combine multiple individually trained local models on a server node, our FedCross sequentially trains the global model across different clients in a round-robin manner, and thus the entire training procedure does not involve any model aggregation steps. To further improve its performance to be comparable with the centralized learning method, we combine the FedCross with an ensemble learning mechanism to compose a federated cross ensemble learning (FedCrossEns) method. Finally, we conduct extensive experiments using a set of public datasets. The experimental results show that the proposed FedCross training strategy outperforms the mainstream FL methods on non-iid data. In addition to improving the segmentation performance, our FedCrossEns can further provide a quantitative estimation of the model uncertainty, demonstrating the effectiveness and clinical significance of our designs. Source code will be made publicly available after paper publication.
SkullEngine: A Multi-stage CNN Framework for Collaborative CBCT Image Segmentation and Landmark Detection
Oct 07, 2021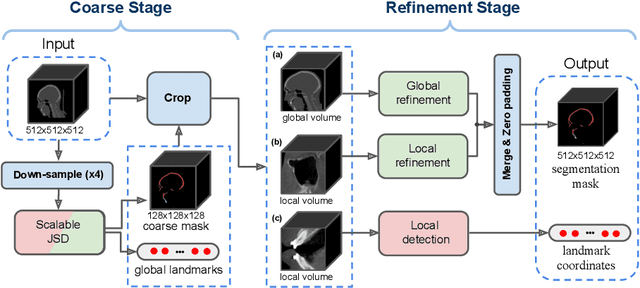

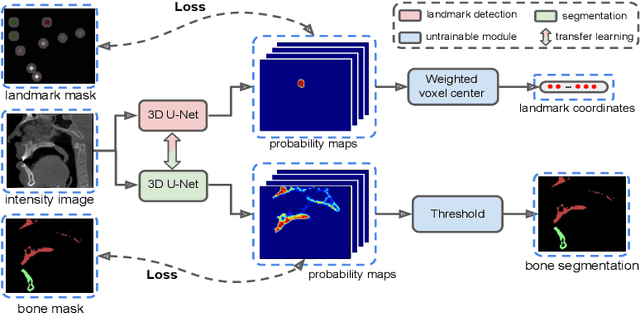

We propose a multi-stage coarse-to-fine CNN-based framework, called SkullEngine, for high-resolution segmentation and large-scale landmark detection through a collaborative, integrated, and scalable JSD model and three segmentation and landmark detection refinement models. We evaluated our framework on a clinical dataset consisting of 170 CBCT/CT images for the task of segmenting 2 bones (midface and mandible) and detecting 175 clinically common landmarks on bones, teeth, and soft tissues.
A Self-Supervised Deep Framework for Reference Bony Shape Estimation in Orthognathic Surgical Planning
Sep 11, 2021
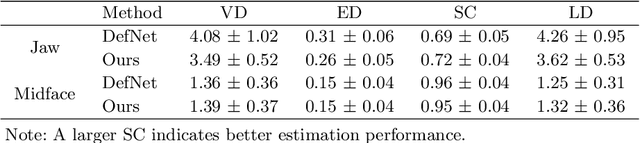
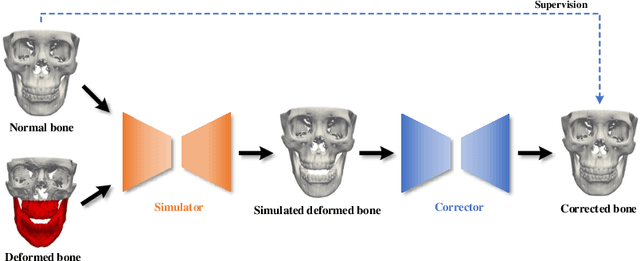
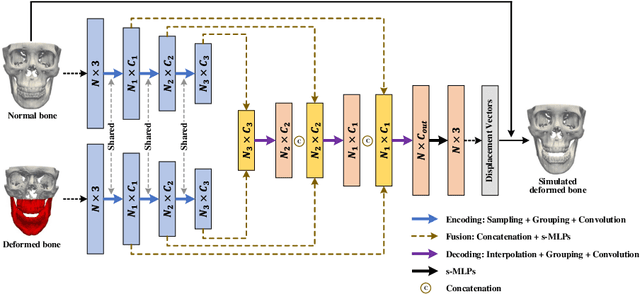
Virtual orthognathic surgical planning involves simulating surgical corrections of jaw deformities on 3D facial bony shape models. Due to the lack of necessary guidance, the planning procedure is highly experience-dependent and the planning results are often suboptimal. A reference facial bony shape model representing normal anatomies can provide an objective guidance to improve planning accuracy. Therefore, we propose a self-supervised deep framework to automatically estimate reference facial bony shape models. Our framework is an end-to-end trainable network, consisting of a simulator and a corrector. In the training stage, the simulator maps jaw deformities of a patient bone to a normal bone to generate a simulated deformed bone. The corrector then restores the simulated deformed bone back to normal. In the inference stage, the trained corrector is applied to generate a patient-specific normal-looking reference bone from a real deformed bone. The proposed framework was evaluated using a clinical dataset and compared with a state-of-the-art method that is based on a supervised point-cloud network. Experimental results show that the estimated shape models given by our approach are clinically acceptable and significantly more accurate than that of the competing method.