 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoCLUE : Object-Aware Clustering Enhances Monocular 3D Object Detection
Nov 11, 2025Monocular 3D object detection offers a cost-effective solution for autonomous driving but suffers from ill-posed depth and limited field of view. These constraints cause a lack of geometric cues and reduced accuracy in occluded or truncated scenes. While recent approaches incorporate additional depth information to address geometric ambiguity, they overlook the visual cues crucial for robust recognition. We propose MonoCLUE, which enhances monocular 3D detection by leveraging both local clustering and generalized scene memory of visual features. First, we perform K-means clustering on visual features to capture distinct object-level appearance parts (e.g., bonnet, car roof), improving detection of partially visible objects. The clustered features are propagated across regions to capture objects with similar appearances. Second, we construct a generalized scene memory by aggregating clustered features across images, providing consistent representations that generalize across scenes. This improves object-level feature consistency, enabling stable detection across varying environments. Lastly, we integrate both local cluster features and generalized scene memory into object queries, guiding attention toward informative regions. Exploiting a unified local clustering and generalized scene memory strategy, MonoCLUE enables robust monocular 3D detection under occlusion and limited visibility, achieving state-of-the-art performance on the KITTI benchmark.
STATIC : Surface Temporal Affine for TIme Consistency in Video Monocular Depth Estimation
Dec 02, 2024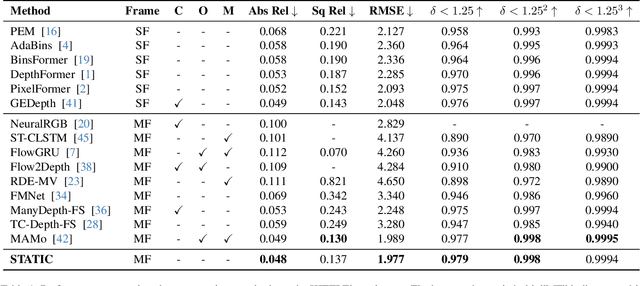


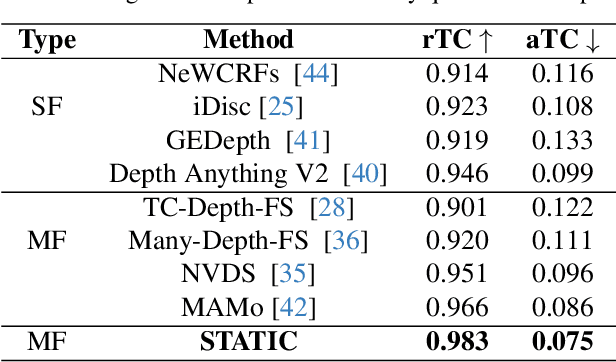
Video monocular depth estimation is essential for applications such as autonomous driving, AR/VR, and robotics. Recent transformer-based single-image monocular depth estimation models perform well on single images but struggle with depth consistency across video frames. Traditional methods aim to improve temporal consistency using multi-frame temporal modules or prior information like optical flow and camera parameters. However, these approaches face issues such as high memory use, reduced performance with dynamic or irregular motion, and limited motion understanding. We propose STATIC, a novel model that independently learns temporal consistency in static and dynamic area without additional information. A difference mask from surface normals identifies static and dynamic area by measuring directional variance. For static area, the Masked Static (MS) module enhances temporal consistency by focusing on stable regions. For dynamic area, the Surface Normal Similarity (SNS) module aligns areas and enhances temporal consistency by measuring feature similarity between frames. A final refinement integrates the independently learned static and dynamic area, enabling STATIC to achieve temporal consistency across the entire sequence. Our method achieves state-of-the-art video depth estimation on the KITTI and NYUv2 datasets without additional information.
Effective SAM Combination for Open-Vocabulary Semantic Segmentation
Nov 22, 2024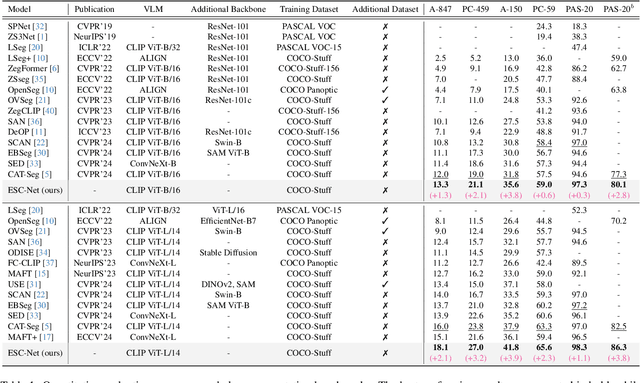
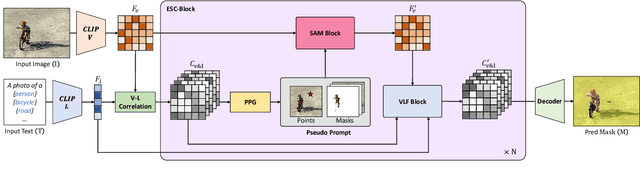
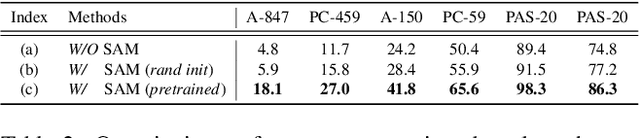

Open-vocabulary semantic segmentation aims to assign pixel-level labels to images across an unlimited range of classes. Traditional methods address this by sequentially connecting a powerful mask proposal generator, such as the Segment Anything Model (SAM), with a pre-trained vision-language model like CLIP. But these two-stage approaches often suffer from high computational costs, memory inefficiencies. In this paper, we propose ESC-Net, a novel one-stage open-vocabulary segmentation model that leverages the SAM decoder blocks for class-agnostic segmentation within an efficient inference framework. By embedding pseudo prompts generated from image-text correlations into SAM's promptable segmentation framework, ESC-Net achieves refined spatial aggregation for accurate mask predictions. ESC-Net achieves superior performance on standard benchmarks, including ADE20K, PASCAL-VOC, and PASCAL-Context, outperforming prior methods in both efficiency and accuracy. Comprehensive ablation studies further demonstrate its robustness across challenging conditions.
Video Diffusion Models are Strong Video Inpainter
Aug 21, 2024



Propagation-based video inpainting using optical flow at the pixel or feature level has recently garnered significant attention. However, it has limitations such as the inaccuracy of optical flow prediction and the propagation of noise over time. These issues result in non-uniform noise and time consistency problems throughout the video, which are particularly pronounced when the removed area is large and involves substantial movement. To address these issues, we propose a novel First Frame Filling Video Diffusion Inpainting model (FFF-VDI). We design FFF-VDI inspired by the capabilities of pre-trained image-to-video diffusion models that can transform the first frame image into a highly natural video. To apply this to the video inpainting task, we propagate the noise latent information of future frames to fill the masked areas of the first frame's noise latent code. Next, we fine-tune the pre-trained image-to-video diffusion model to generate the inpainted video. The proposed model addresses the limitations of existing methods that rely on optical flow quality, producing much more natural and temporally consistent videos. This proposed approach is the first to effectively integrate image-to-video diffusion models into video inpainting tasks. Through various comparative experiments, we demonstrate that the proposed model can robustly handle diverse inpainting types with high quality.