 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTATIC : Surface Temporal Affine for TIme Consistency in Video Monocular Depth Estimation
Paper and Code
Dec 02, 2024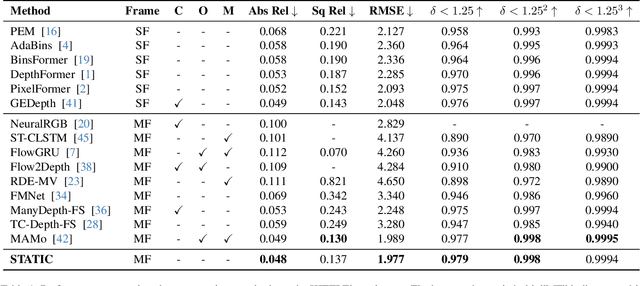


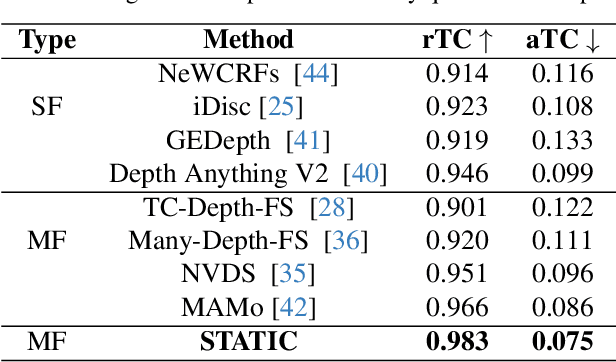
Video monocular depth estimation is essential for applications such as autonomous driving, AR/VR, and robotics. Recent transformer-based single-image monocular depth estimation models perform well on single images but struggle with depth consistency across video frames. Traditional methods aim to improve temporal consistency using multi-frame temporal modules or prior information like optical flow and camera parameters. However, these approaches face issues such as high memory use, reduced performance with dynamic or irregular motion, and limited motion understanding. We propose STATIC, a novel model that independently learns temporal consistency in static and dynamic area without additional information. A difference mask from surface normals identifies static and dynamic area by measuring directional variance. For static area, the Masked Static (MS) module enhances temporal consistency by focusing on stable regions. For dynamic area, the Surface Normal Similarity (SNS) module aligns areas and enhances temporal consistency by measuring feature similarity between frames. A final refinement integrates the independently learned static and dynamic area, enabling STATIC to achieve temporal consistency across the entire sequence. Our method achieves state-of-the-art video depth estimation on the KITTI and NYUv2 datasets without additional information.