 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElevating Flow-Guided Video Inpainting with Reference Generation
Paper and Code

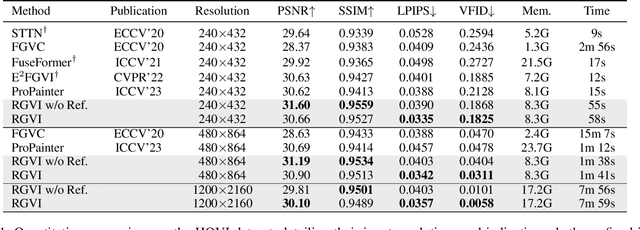
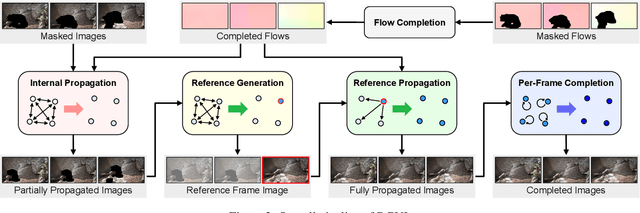
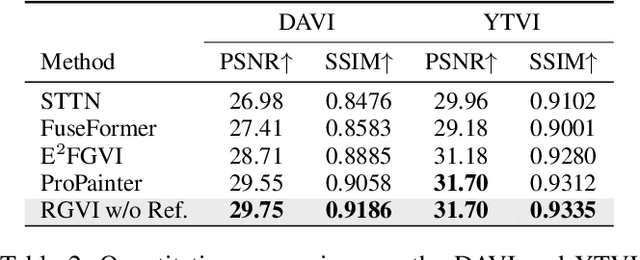
Video inpainting (VI) is a challenging task that requires effective propagation of observable content across frames while simultaneously generating new content not present in the original video. In this study, we propose a robust and practical VI framework that leverages a large generative model for reference generation in combination with an advanced pixel propagation algorithm. Powered by a strong generative model, our method not only significantly enhances frame-level quality for object removal but also synthesizes new content in the missing areas based on user-provided text prompts. For pixel propagation, we introduce a one-shot pixel pulling method that effectively avoids error accumulation from repeated sampling while maintaining sub-pixel precision. To evaluate various VI methods in realistic scenarios, we also propose a high-quality VI benchmark, HQVI, comprising carefully generated videos using alpha matte composition. On public benchmarks and the HQVI dataset, our method demonstrates significantly higher visual quality and metric scores compared to existing solutions. Furthermore, it can process high-resolution videos exceeding 2K resolution with ease, underscoring its superiority for real-world applications.